Department of Engineering Science, University of Oxford, Oxford, UK.
NLPie Research, Oxford, UK.
Bioinformatics. 2023 Mar 1;39(3). doi: 10.1093/bioinformatics/btad103.
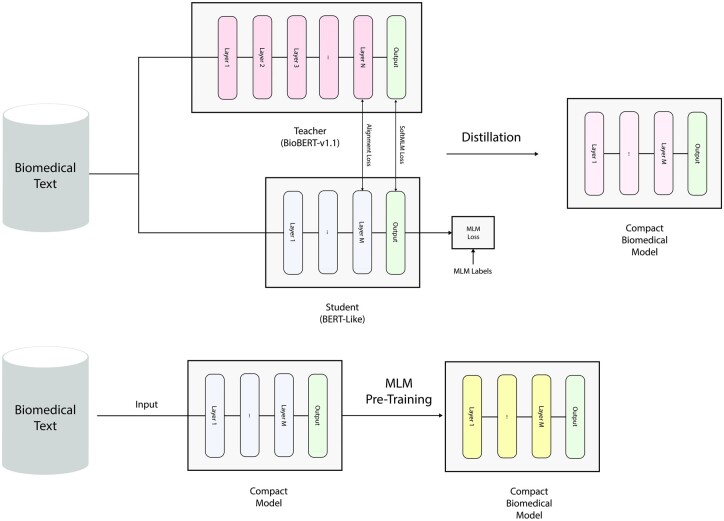
Language models pre-trained on biomedical corpora, such as BioBERT, have recently shown promising results on downstream biomedical tasks. Many existing pre-trained models, on the other hand, are resource-intensive and computationally heavy owing to factors such as embedding size, hidden dimension and number of layers. The natural language processing community has developed numerous strategies to compress these models utilizing techniques such as pruning, quantization and knowledge distillation, resulting in models that are considerably faster, smaller and subsequently easier to use in practice. By the same token, in this article, we introduce six lightweight models, namely, BioDistilBERT, BioTinyBERT, BioMobileBERT, DistilBioBERT, TinyBioBERT and CompactBioBERT which are obtained either by knowledge distillation from a biomedical teacher or continual learning on the Pubmed dataset. We evaluate all of our models on three biomedical tasks and compare them with BioBERT-v1.1 to create the best efficient lightweight models that perform on par with their larger counterparts.
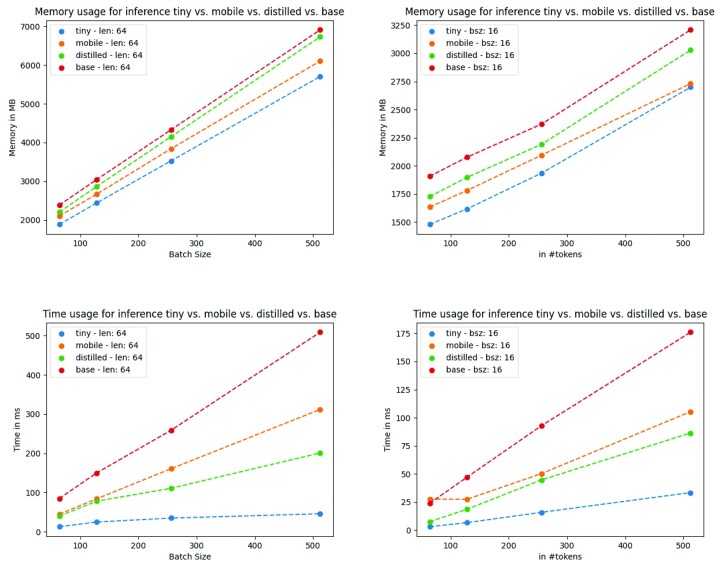
We trained six different models in total, with the largest model having 65 million in parameters and the smallest having 15 million; a far lower range of parameters compared with BioBERT's 110M. Based on our experiments on three different biomedical tasks, we found that models distilled from a biomedical teacher and models that have been additionally pre-trained on the PubMed dataset can retain up to 98.8% and 98.6% of the performance of the BioBERT-v1.1, respectively. Overall, our best model below 30 M parameters is BioMobileBERT, while our best models over 30 M parameters are DistilBioBERT and CompactBioBERT, which can keep up to 98.2% and 98.8% of the performance of the BioBERT-v1.1, respectively.
Codes are available at: https://github.com/nlpie-research/Compact-Biomedical-Transformers. Trained models can be accessed at: https://huggingface.co/nlpie.
最近,基于生物医学语料库(如 BioBERT)进行预训练的语言模型在下游生物医学任务中显示出了很有前景的结果。另一方面,许多现有的预训练模型由于嵌入大小、隐藏维度和层数等因素,资源密集且计算量大。自然语言处理社区已经开发了许多策略,利用剪枝、量化和知识蒸馏等技术来压缩这些模型,从而得到速度更快、体积更小、在实践中更容易使用的模型。同样,在本文中,我们介绍了六个轻量级模型,即通过知识蒸馏从生物医学教师或在 Pubmed 数据集上进行连续学习获得的 BioDistilBERT、BioTinyBERT、BioMobileBERT、DistilBioBERT、TinyBioBERT 和 CompactBioBERT。我们在三个生物医学任务上评估了所有模型,并将它们与 BioBERT-v1.1 进行比较,以创建性能与大型模型相当的最佳高效轻量级模型。
我们总共训练了六个不同的模型,最大的模型有 6500 万个参数,最小的有 1500 万个;与 BioBERT 的 1.11 亿相比,参数范围要小得多。基于我们在三个不同生物医学任务上的实验,我们发现从生物医学教师那里蒸馏出来的模型和在 PubMed 数据集上额外预训练的模型分别可以保留 BioBERT-v1.1 性能的 98.8%和 98.6%。总的来说,我们参数低于 30M 的最佳模型是 BioMobileBERT,而我们参数高于 30M 的最佳模型是 DistilBioBERT 和 CompactBioBERT,它们分别可以保留 BioBERT-v1.1 性能的 98.2%和 98.8%。
代码可在 https://github.com/nlpie-research/Compact-Biomedical-Transformers 上获得。训练好的模型可以在 https://huggingface.co/nlpie 上访问。