Department of Biomedical Data Science, Stanford University, Stanford, CA 94305, USA.
Departments of Bioengineering, Genetics, and Medicine, Stanford University, Stanford, CA 94305, USA.
Biomolecules. 2023 Feb 18;13(2):387. doi: 10.3390/biom13020387.
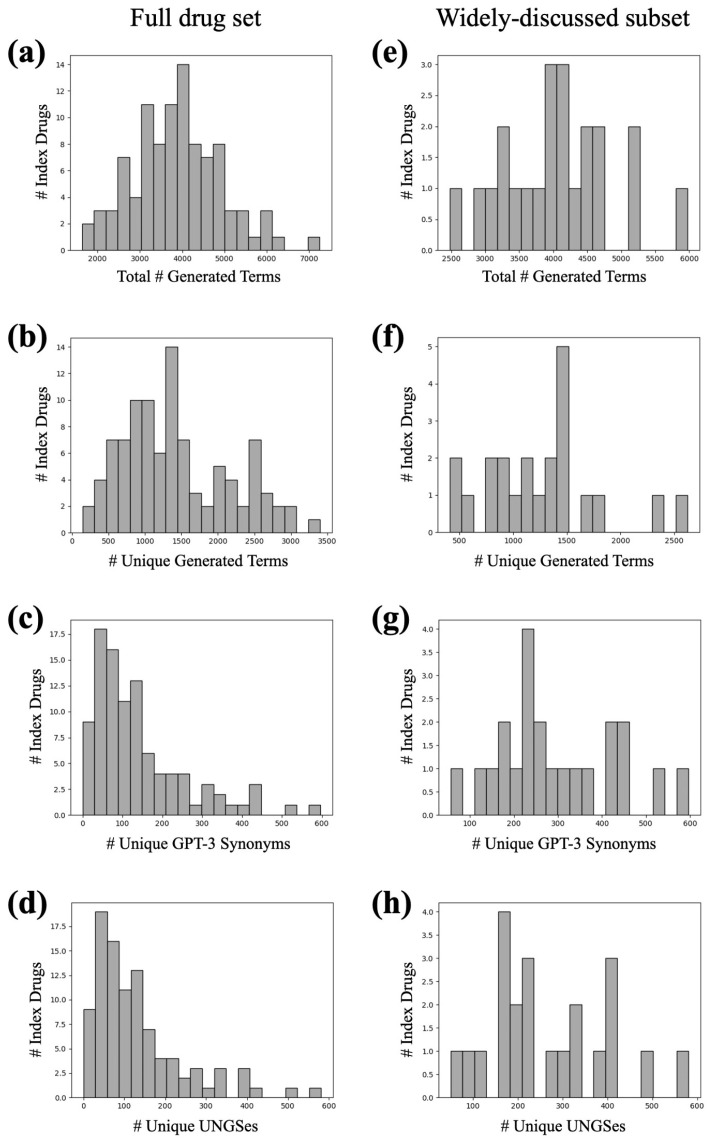
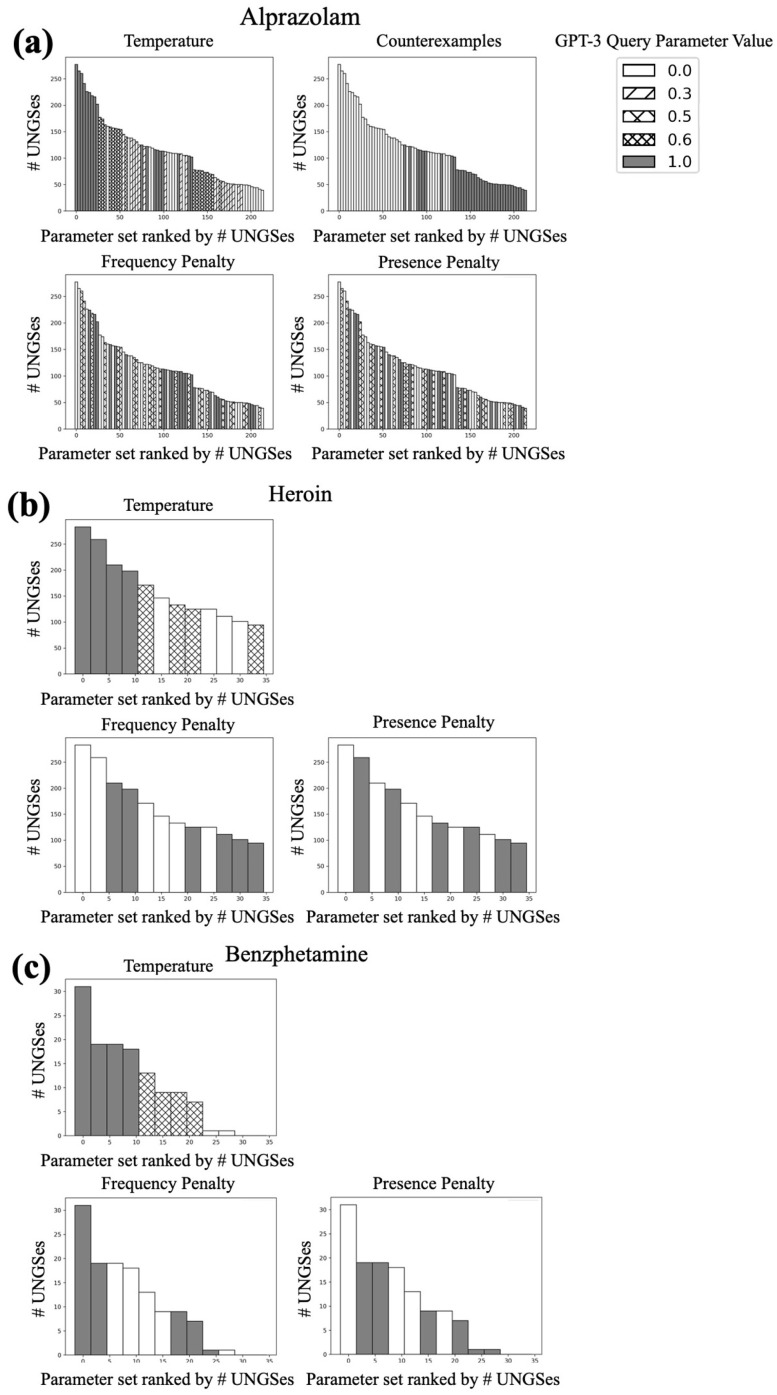
Drug abuse is a serious problem in the United States, with over 90,000 drug overdose deaths nationally in 2020. A key step in combating drug abuse is detecting, monitoring, and characterizing its trends over time and location, also known as pharmacovigilance. While federal reporting systems accomplish this to a degree, they often have high latency and incomplete coverage. Social-media-based pharmacovigilance has zero latency, is easily accessible and unfiltered, and benefits from drug users being willing to share their experiences online pseudo-anonymously. However, unlike highly structured official data sources, social media text is rife with misspellings and slang, making automated analysis difficult. Generative Pretrained Transformer 3 (GPT-3) is a large autoregressive language model specialized for few-shot learning that was trained on text from the entire internet. We demonstrate that GPT-3 can be used to generate slang and common misspellings of terms for drugs of abuse. We repeatedly queried GPT-3 for synonyms of drugs of abuse and filtered the generated terms using automated Google searches and cross-references to known drug names. When generated terms for alprazolam were manually labeled, we found that our method produced 269 synonyms for alprazolam, 221 of which were new discoveries not included in an existing drug lexicon for social media. We repeated this process for 98 drugs of abuse, of which 22 are widely-discussed drugs of abuse, building a lexicon of colloquial drug synonyms that can be used for pharmacovigilance on social media.
药物滥用是美国的一个严重问题,2020 年全国有超过 90,000 例药物过量死亡。打击药物滥用的一个关键步骤是检测、监测和描述其随时间和地点的趋势,也称为药物警戒。虽然联邦报告系统在一定程度上实现了这一目标,但它们通常存在高延迟和不完整的覆盖范围。基于社交媒体的药物警戒具有零延迟、易于访问且不受过滤、并且受益于药物使用者愿意在网上匿名分享他们的经验。然而,与高度结构化的官方数据源不同,社交媒体文本充满了拼写错误和俚语,使得自动化分析变得困难。生成式预训练转换器 3(GPT-3)是一种专门用于少量学习的大型自回归语言模型,它是在整个互联网的文本上进行训练的。我们证明 GPT-3 可用于生成滥用药物的俚语和常见拼写错误。我们反复向 GPT-3 查询滥用药物的同义词,并使用自动谷歌搜索和交叉引用已知药物名称来过滤生成的术语。当对阿普唑仑生成的术语进行手动标记时,我们发现我们的方法生成了 269 个阿普唑仑的同义词,其中 221 个是新发现的,未包含在现有的社交媒体药物词汇中。我们对 98 种滥用药物重复了这个过程,其中 22 种是广泛讨论的滥用药物,构建了一个口语药物同义词词汇表,可用于社交媒体上的药物警戒。