Department of Biostatistics, School of Public Health and Modeling of Noncommunicable Diseases Research Center, Hamadan University of Medical Sciences, Hamadan, Iran.
Department of Biostatistics, School of Public Health, Hamadan University of Medical Sciences, Hamadan, Iran.
BMC Med Genomics. 2023 Feb 27;16(1):35. doi: 10.1186/s12920-023-01462-6.
Oral cancer (OC) is a debilitating disease that can affect the quality of life of these patients adversely. Oral premalignant lesion patients have a high risk of developing OC. Therefore, identifying robust survival subgroups among them may significantly improve patient therapy and care. This study aimed to identify prognostic biomarkers that predict the time-to-development of OC and survival stratification for patients using state-of-the-art machine learning and deep learning.
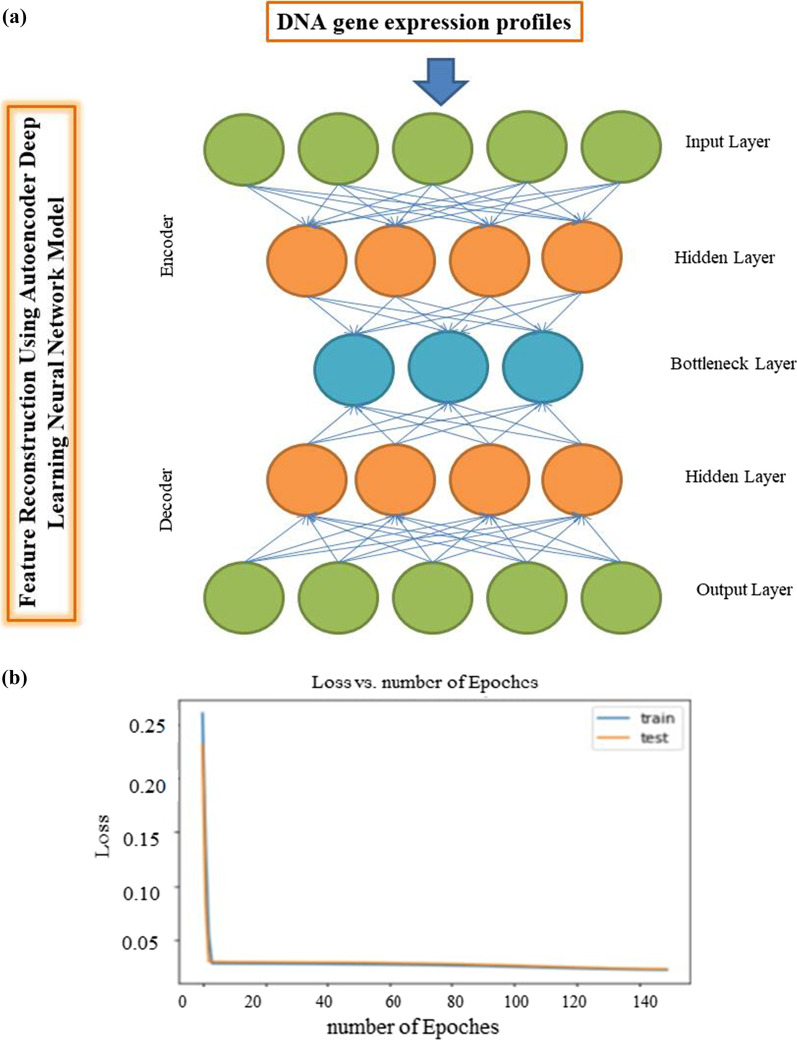
Gene expression profiles (29,096 probes) related to 86 patients from the GSE26549 dataset from the GEO repository were used. An autoencoder deep learning neural network model was used to extract features. We also used a univariate Cox regression model to select significant features obtained from the deep learning method (P < 0.05). High-risk and low-risk groups were then identified using a hierarchical clustering technique based on 100 encoded features (the number of units of the encoding layer, i.e., bottleneck of the network) from autoencoder and selected by Cox proportional hazards model and a supervised random forest (RF) classifier was used to identify gene profiles related to subtypes of OC from the original 29,096 probes.
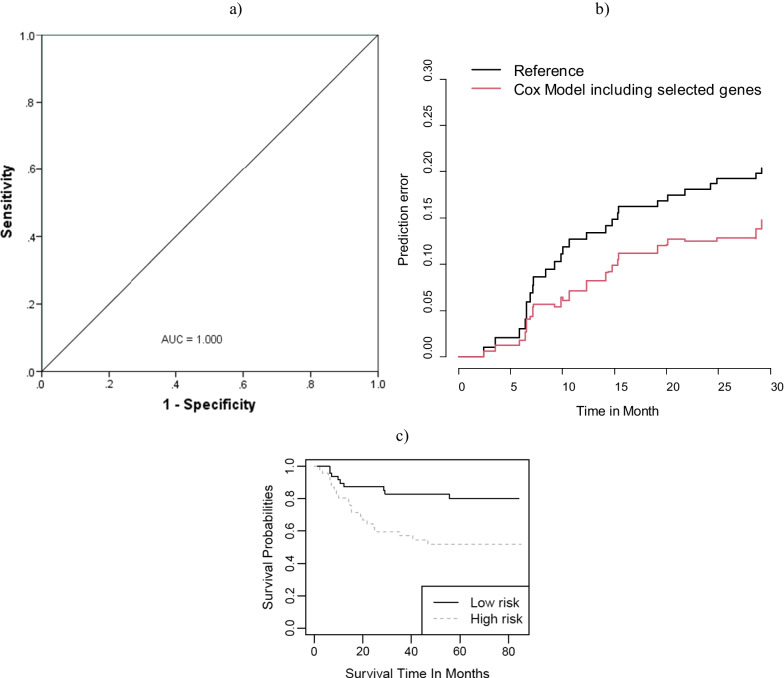
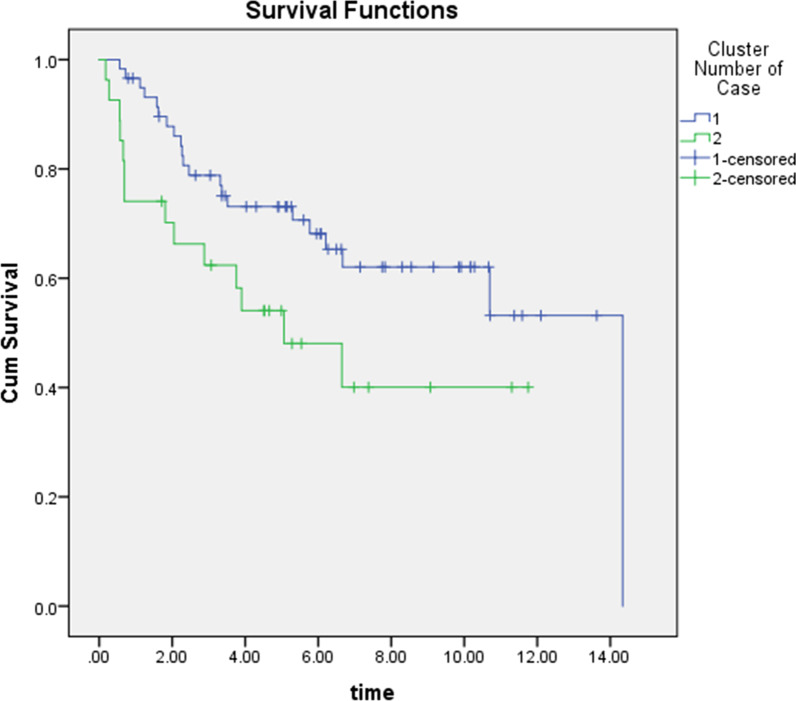
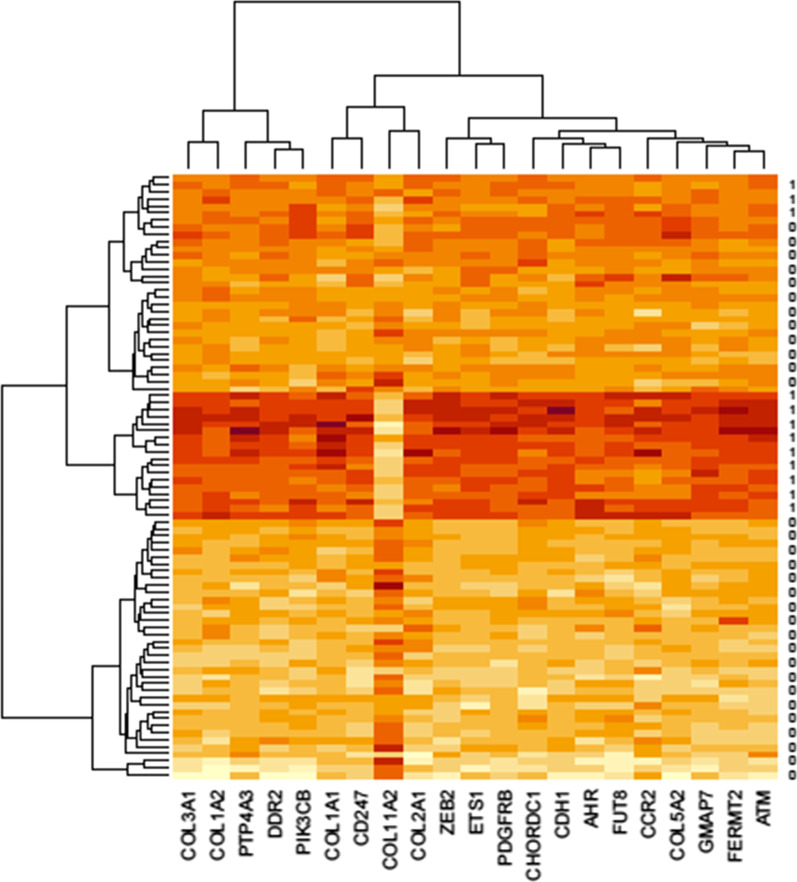
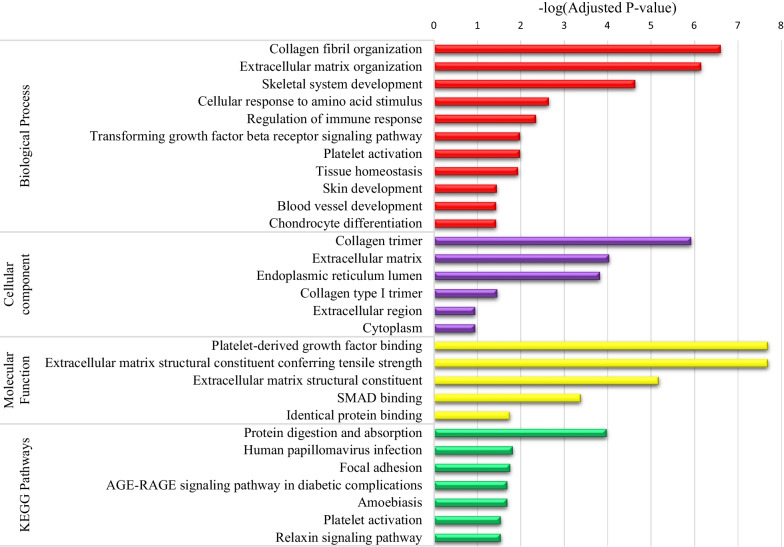
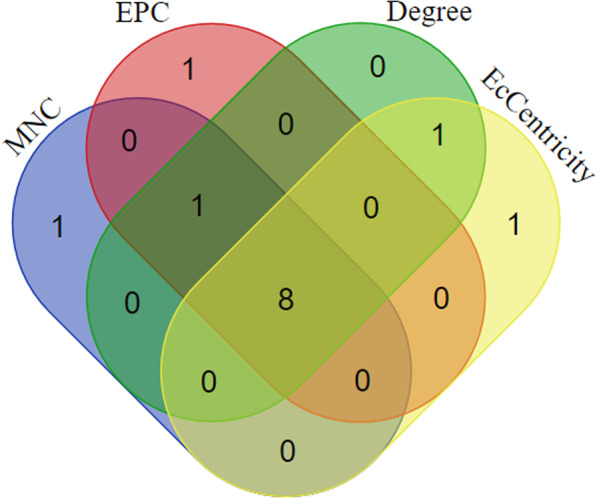
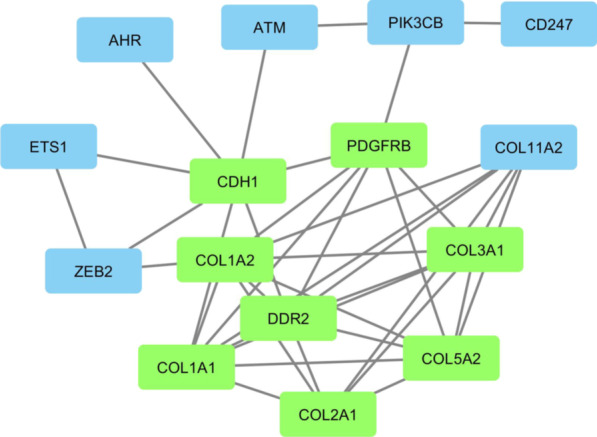
Among 100 encoded features extracted by autoencoder, seventy features were significantly related to time-to-OC-development, based on the univariate Cox model, which was used as the inputs for the clustering of patients. Two survival risk groups were identified (P value of log-rank test = 0.003) and were used as the labels for supervised classification. The overall accuracy of the RF classifier was 0.916 over the test set, yielded 21 top genes (FUT8-DDR2-ATM-CD247-ETS1-ZEB2-COL5A2-GMAP7-CDH1-COL11A2-COL3A1-AHR-COL2A1-CHORDC1-PTP4A3-COL1A2-CCR2-PDGFRB-COL1A1-FERMT2-PIK3CB) associated with time to developing OC, selected among the original 29,096 probes.
Using deep learning, our study identified prominent transcriptional biomarkers in determining high-risk patients for developing oral cancer, which may be prognostic as significant targets for OC therapy. The identified genes may serve as potential targets for oral cancer chemoprevention. Additional validation of these biomarkers in experimental prospective and retrospective studies will launch them in OC clinics.
口腔癌(OC)是一种使人衰弱的疾病,会对患者的生活质量产生不利影响。口腔癌前病变患者发生 OC 的风险较高。因此,在他们中间确定稳健的生存亚组可能会显著改善患者的治疗和护理。本研究旨在使用最先进的机器学习和深度学习技术,确定预测 OC 发病时间和患者生存分层的预后生物标志物。
使用来自 GEO 存储库的 GSE26549 数据集的 86 名患者的基因表达谱(29096 个探针)。使用自动编码器深度学习神经网络模型提取特征。我们还使用单变量 Cox 回归模型选择从深度学习方法获得的显著特征(P < 0.05)。然后使用基于自动编码器的 100 个编码特征(编码层的单元数,即网络的瓶颈)的层次聚类技术和 Cox 比例风险模型选择高风险和低风险组,并使用监督随机森林(RF)分类器从原始的 29096 个探针中识别与 OC 亚型相关的基因谱。
基于单变量 Cox 模型,自动编码器提取的 100 个编码特征中有 70 个特征与 OC 发病时间显著相关,该模型被用作患者聚类的输入。确定了两个生存风险组(对数秩检验的 P 值= 0.003),并将其用作监督分类的标签。RF 分类器在测试集上的总体准确率为 0.916,产生了 21 个顶级基因(FUT8-DDR2-ATM-CD247-ETS1-ZEB2-COL5A2-GMAP7-CDH1-COL11A2-COL3A1-AHR-COL2A1-CHORDC1-PTP4A3-COL1A2-CCR2-PDGFRB-COL1A1-FERMT2-PIK3CB),这些基因与从原始的 29096 个探针中选择的 OC 发病时间相关。
使用深度学习,我们的研究确定了在确定发生口腔癌的高危患者方面具有突出转录生物标志物,这些标志物可能具有预后意义,是 OC 治疗的重要靶标。鉴定的基因可能成为口腔癌化学预防的潜在靶标。在实验前瞻性和回顾性研究中进一步验证这些生物标志物将使其在 OC 临床中得到应用。