Lancashire Clinical Trials Unit, Faculty of Health and Care, University of Central Lancashire, Preston, UK.
Centre for Biostatistics, Division of Population Health, Health Services Research & Primary Care, School of Health Sciences, Faculty of Biology, Medicine and Health, The University of Manchester, Manchester, UK.
Clin Trials. 2023 Jun;20(3):293-306. doi: 10.1177/17407745231164569. Epub 2023 Apr 10.
The intracluster correlation coefficient is a key input parameter for sample size determination in cluster-randomised trials. Sample size is very sensitive to small differences in the intracluster correlation coefficient, so it is vital to have a robust intracluster correlation coefficient estimate. This is often problematic because either a relevant intracluster correlation coefficient estimate is not available or the available estimate is imprecise due to being based on small-scale studies with low numbers of clusters. Misspecification may lead to an underpowered or inefficiently large and potentially unethical trial.
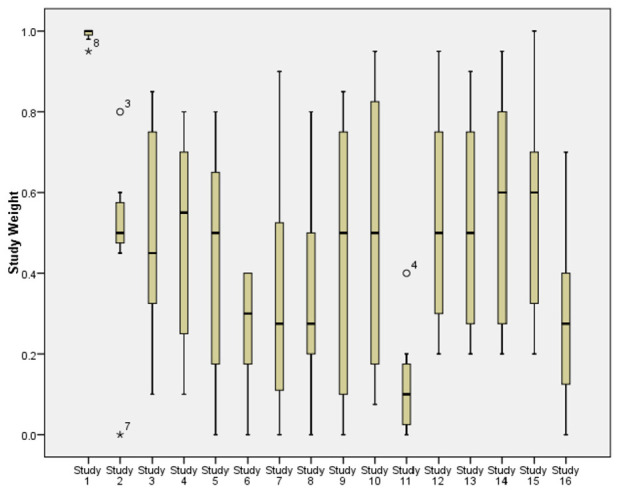
We apply a Bayesian approach to produce an intracluster correlation coefficient estimate and hence propose sample size for a planned cluster-randomised trial of the effectiveness of a systematic voiding programme for post-stroke incontinence. A Bayesian hierarchical model is used to combine intracluster correlation coefficient estimates from other relevant trials making use of the wealth of intracluster correlation coefficient information available in published research. We employ knowledge elicitation process to assess the relevance of each intracluster correlation coefficient estimate to the planned trial setting. The team of expert reviewers assigned relevance weights to each study, and each outcome within the study, hence informing parameters of Bayesian modelling. To measure the performance of experts, agreement and reliability methods were applied.
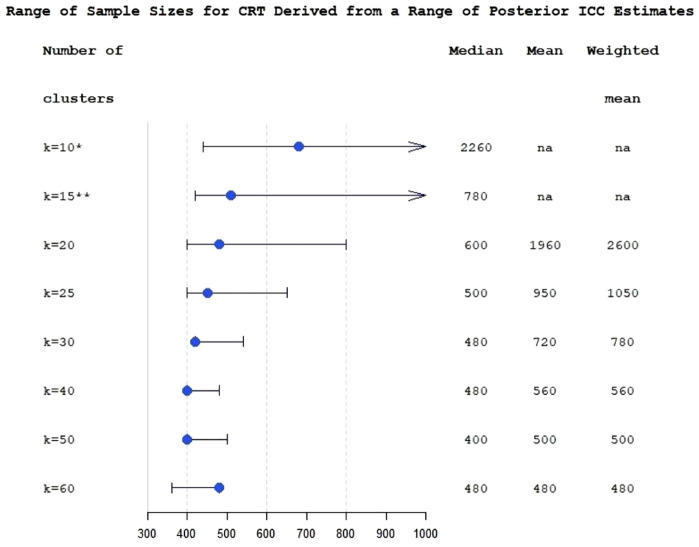
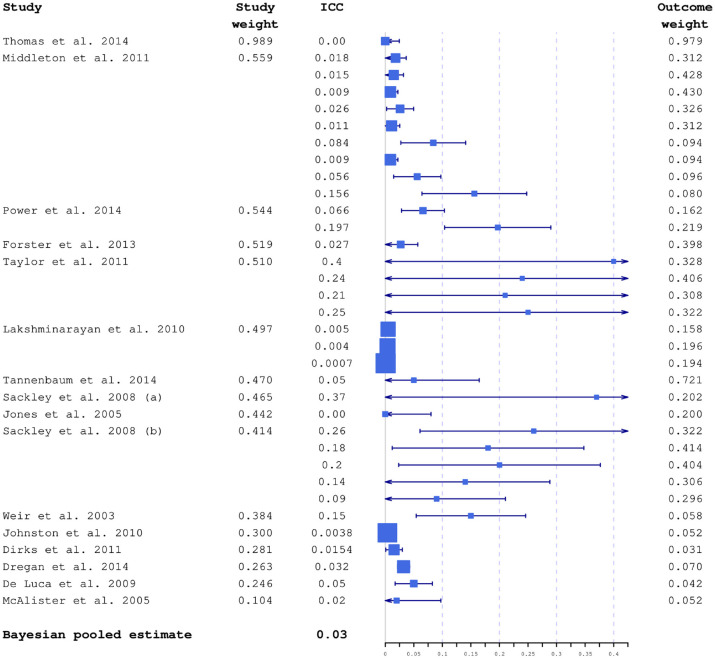
The 34 intracluster correlation coefficient estimates extracted from 16 previously published trials were combined in the Bayesian hierarchical model using aggregated relevance weights elicited from the experts. The intracluster correlation coefficients available from external sources were used to construct a posterior distribution of the targeted intracluster correlation coefficient which was summarised as a posterior median with a 95% credible interval informing researchers about the range of plausible sample size values. The estimated intracluster correlation coefficient determined a sample size of between 450 (25 clusters) and 480 (20 clusters), compared to 500-600 from a classical approach. The use of quantiles, and other parameters, from the estimated posterior distribution is illustrated and the impact on sample size described.
Accounting for uncertainty in an unknown intracluster correlation coefficient, trials can be designed with a more robust sample size. The approach presented provides the possibility of incorporating intracluster correlation coefficients from various cluster-randomised trial settings which can differ from the planned study, with the difference being accounted for in the modelling. By using expert knowledge to elicit relevance weights and synthesising the externally available intracluster correlation coefficient estimates, information is used more efficiently than in a classical approach, where the intracluster correlation coefficient estimates tend to be less robust and overly conservative. The intracluster correlation coefficient estimate constructed is likely to produce a smaller sample size on average than the conventional strategy of choosing a conservative intracluster correlation coefficient estimate. This may therefore result in substantial time and resources savings.
在整群随机试验中,组内相关系数是确定样本量的关键输入参数。由于组内相关系数的微小差异会对样本量产生很大影响,因此获得稳健的组内相关系数估计至关重要。这通常是一个问题,因为要么没有相关的组内相关系数估计值,要么由于基于小规模研究且集群数量较少,可用的估计值不够精确。参数设定不当可能导致检验效能不足或效率低下,并且潜在地不道德。
我们应用贝叶斯方法来生成组内相关系数估计值,并提出了一项针对卒中后尿失禁的系统排空方案有效性的计划整群随机试验的样本量。贝叶斯层次模型用于结合其他相关试验中的组内相关系数估计值,充分利用已发表研究中可用的丰富组内相关系数信息。我们采用知识启发过程来评估每个组内相关系数估计值与计划试验设置的相关性。专家组的评审员为每个研究及其研究内的每个结果分配相关性权重,从而为贝叶斯模型的参数提供信息。为了衡量专家的表现,应用了一致性和可靠性方法。
从 16 项先前发表的试验中提取了 34 个组内相关系数估计值,使用专家启发得出的聚合相关性权重在贝叶斯层次模型中进行了组合。使用来自外部来源的组内相关系数来构建目标组内相关系数的后验分布,该分布的后验中位数和 95%可信区间总结了合理的样本量值范围,为研究人员提供了信息。估计的组内相关系数确定的样本量为 450(25 个集群)至 480(20 个集群),而经典方法确定的样本量为 500-600。说明了如何使用估计后验分布的分位数和其他参数,并描述了其对样本量的影响。
在未知组内相关系数中考虑不确定性,可以使用更稳健的样本量设计试验。所提出的方法提供了从各种整群随机试验设置中纳入组内相关系数的可能性,这些设置可能与计划研究不同,模型中会考虑到这种差异。通过使用专家知识来启发相关性权重,并综合外部可用的组内相关系数估计值,信息的使用比经典方法更有效,在经典方法中,组内相关系数估计值往往不够稳健且过于保守。构建的组内相关系数估计值平均而言可能产生较小的样本量,而不是选择保守的组内相关系数估计值的传统策略。因此,这可能会节省大量的时间和资源。