Thirunavukarasu Arun James, Hassan Refaat, Mahmood Shathar, Sanghera Rohan, Barzangi Kara, El Mukashfi Mohanned, Shah Sachin
University of Cambridge School of Clinical Medicine, Cambridge, United Kingdom.
Attenborough Surgery, Bushey Medical Centre, Bushey, United Kingdom.
JMIR Med Educ. 2023 Apr 21;9:e46599. doi: 10.2196/46599.
Large language models exhibiting human-level performance in specialized tasks are emerging; examples include Generative Pretrained Transformer 3.5, which underlies the processing of ChatGPT. Rigorous trials are required to understand the capabilities of emerging technology, so that innovation can be directed to benefit patients and practitioners.
Here, we evaluated the strengths and weaknesses of ChatGPT in primary care using the Membership of the Royal College of General Practitioners Applied Knowledge Test (AKT) as a medium.
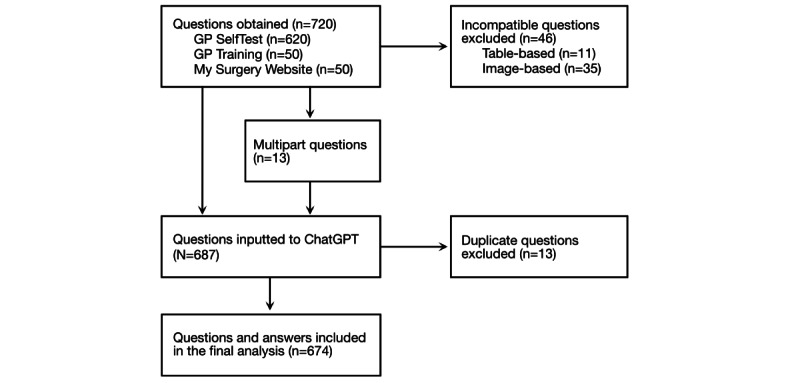
AKT questions were sourced from a web-based question bank and 2 AKT practice papers. In total, 674 unique AKT questions were inputted to ChatGPT, with the model's answers recorded and compared to correct answers provided by the Royal College of General Practitioners. Each question was inputted twice in separate ChatGPT sessions, with answers on repeated trials compared to gauge consistency. Subject difficulty was gauged by referring to examiners' reports from 2018 to 2022. Novel explanations from ChatGPT-defined as information provided that was not inputted within the question or multiple answer choices-were recorded. Performance was analyzed with respect to subject, difficulty, question source, and novel model outputs to explore ChatGPT's strengths and weaknesses.
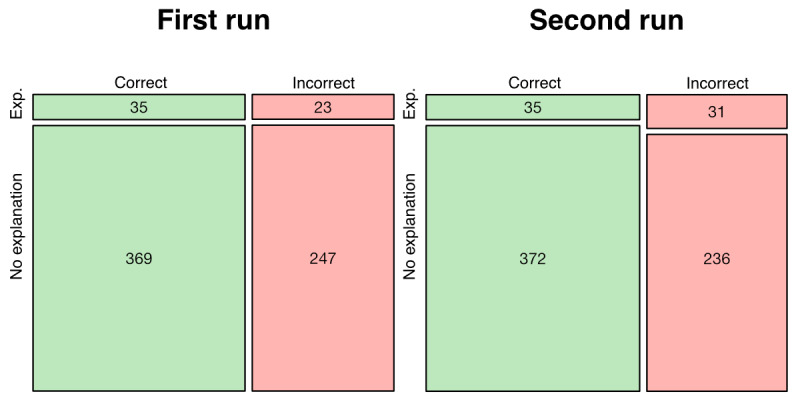
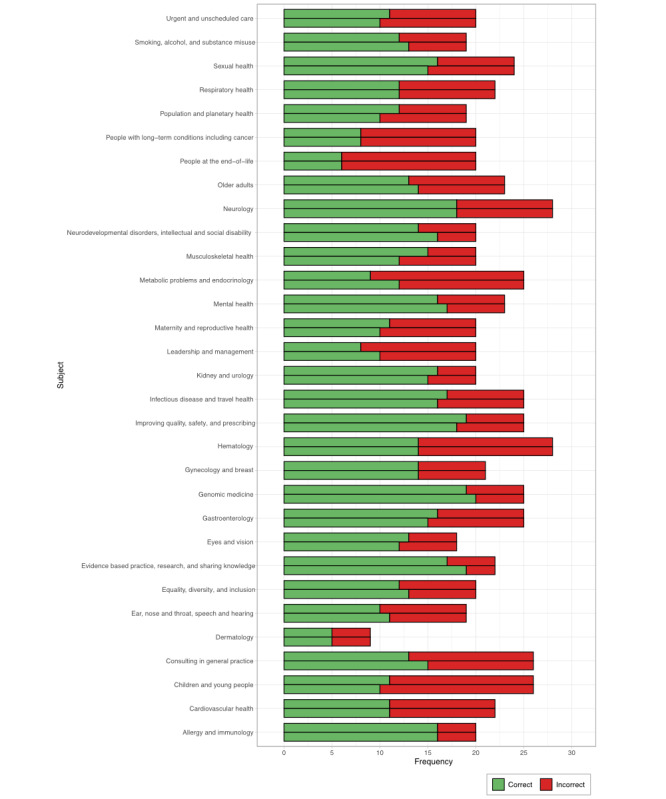
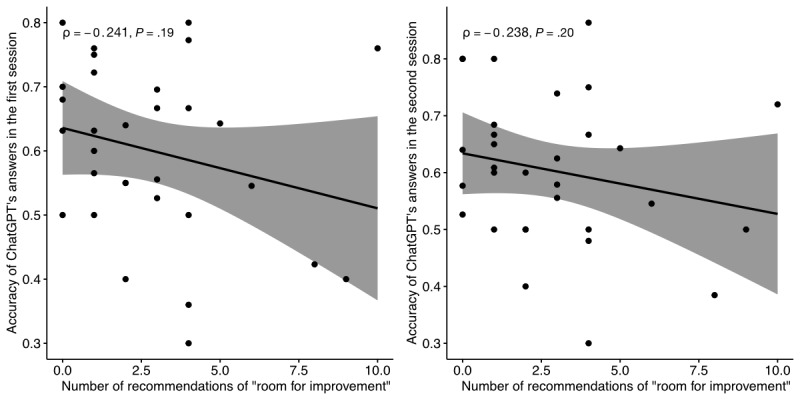
Average overall performance of ChatGPT was 60.17%, which is below the mean passing mark in the last 2 years (70.42%). Accuracy differed between sources (P=.04 and .06). ChatGPT's performance varied with subject category (P=.02 and .02), but variation did not correlate with difficulty (Spearman ρ=-0.241 and -0.238; P=.19 and .20). The proclivity of ChatGPT to provide novel explanations did not affect accuracy (P>.99 and .23).
Large language models are approaching human expert-level performance, although further development is required to match the performance of qualified primary care physicians in the AKT. Validated high-performance models may serve as assistants or autonomous clinical tools to ameliorate the general practice workforce crisis.
在专门任务中展现出人类水平表现的大型语言模型正在涌现;例如生成式预训练变换器3.5,它是ChatGPT处理的基础。需要进行严格试验以了解新兴技术的能力,从而引导创新造福患者和从业者。
在此,我们以皇家全科医师学院应用知识测试(AKT)为媒介,评估ChatGPT在初级保健中的优势和劣势。
AKT问题来自基于网络的题库和两份AKT练习题。总共向ChatGPT输入了674个独特的AKT问题,记录模型的答案并与皇家全科医师学院提供的正确答案进行比较。每个问题在单独的ChatGPT会话中输入两次,比较重复试验的答案以评估一致性。通过参考2018年至2022年考官报告来衡量题目难度。记录ChatGPT给出的新颖解释,即问题或多个答案选项中未输入的信息。从题目、难度、问题来源和新颖的模型输出方面分析表现,以探索ChatGPT的优势和劣势。
ChatGPT的平均总体表现为60.17%,低于过去两年的平均及格分数(70.42%)。不同来源的准确率存在差异(P = 0.04和0.06)。ChatGPT的表现因题目类别而异(P = 0.02和0.02),但这种差异与难度无关(斯皮尔曼ρ = -0.241和 -0.238;P = 0.19和0.20)。ChatGPT提供新颖解释的倾向不影响准确率(P > 0.99和0.23)。
大型语言模型正在接近人类专家水平的表现,不过仍需要进一步发展以在AKT中达到合格初级保健医生的表现。经过验证的高性能模型可作为助手或自主临床工具,以缓解全科医疗劳动力危机。