Developmental Neurosciences Research & Teaching Department, UCL Great Ormond Street Institute of Child Health, London, UK.
Department of Neuropsychology, Great Ormond Street Hospital, London, UK.
Epilepsia. 2023 Aug;64(8):2014-2026. doi: 10.1111/epi.17637. Epub 2023 Jun 16.
The accurate prediction of seizure freedom after epilepsy surgery remains challenging. We investigated if (1) training more complex models, (2) recruiting larger sample sizes, or (3) using data-driven selection of clinical predictors would improve our ability to predict postoperative seizure outcome using clinical features. We also conducted the first substantial external validation of a machine learning model trained to predict postoperative seizure outcome.
We performed a retrospective cohort study of 797 children who had undergone resective or disconnective epilepsy surgery at a tertiary center. We extracted patient information from medical records and trained three models-a logistic regression, a multilayer perceptron, and an XGBoost model-to predict 1-year postoperative seizure outcome on our data set. We evaluated the performance of a recently published XGBoost model on the same patients. We further investigated the impact of sample size on model performance, using learning curve analysis to estimate performance at samples up to N = 2000. Finally, we examined the impact of predictor selection on model performance.
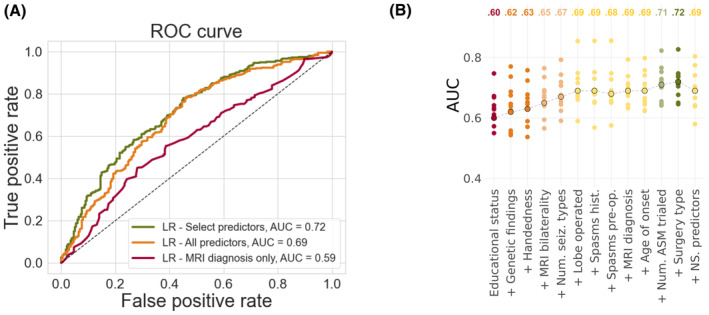
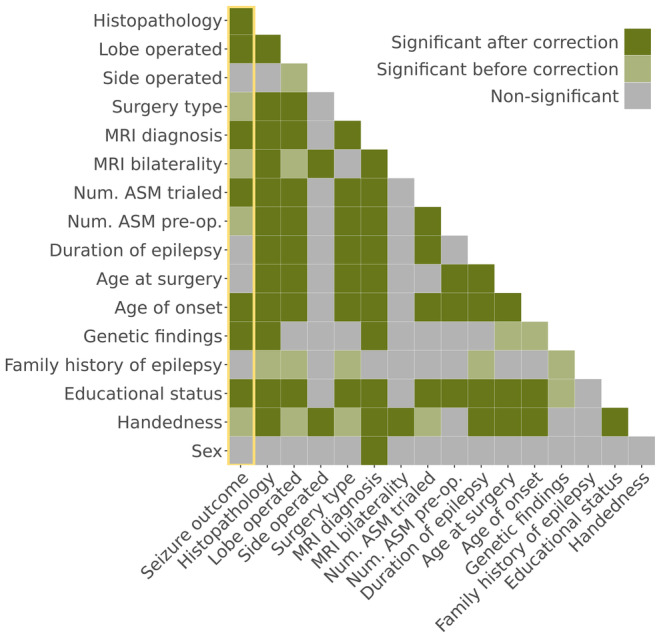
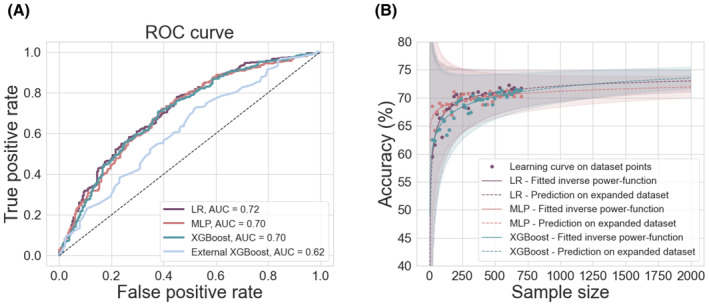
Our logistic regression achieved an accuracy of 72% (95% confidence interval [CI] = 68%-75%, area under the curve [AUC] = .72), whereas our multilayer perceptron and XGBoost both achieved accuracies of 71% (95% CI = 67%-74%, AUC = .70; 95% CI = 68%-75%, AUC = .70). There was no significant difference in performance between our three models (all p > .4) and they all performed better than the external XGBoost, which achieved an accuracy of 63% (95% CI = 59%-67%, AUC = .62; p = .005, p = .01, p = .01) on our data. All models showed improved performance with increasing sample size, but limited improvements beyond our current sample. The best model performance was achieved with data-driven feature selection.
We show that neither the deployment of complex machine learning models nor the assembly of thousands of patients alone is likely to generate significant improvements in our ability to predict postoperative seizure freedom. We instead propose that improved feature selection alongside collaboration, data standardization, and model sharing is required to advance the field.
癫痫手术后准确预测无癫痫发作仍然具有挑战性。我们研究了以下三种方法是否能提高利用临床特征预测术后癫痫发作结局的能力:(1)训练更复杂的模型;(2)招募更大的样本量;(3)使用数据驱动的临床预测因子选择。我们还首次对一个旨在预测术后癫痫发作结局的机器学习模型进行了大规模的外部验证。
我们对在一家三级中心接受切除或离断性癫痫手术的 797 例儿童进行了回顾性队列研究。我们从病历中提取患者信息,并在我们的数据集上训练了三个模型——逻辑回归、多层感知机和 XGBoost 模型,以预测 1 年的术后癫痫发作结局。我们评估了在同一患者中使用最近发表的 XGBoost 模型的性能。我们还通过学习曲线分析进一步研究了样本量对模型性能的影响,估计了样本量高达 N=2000 时的性能。最后,我们研究了预测因子选择对模型性能的影响。
我们的逻辑回归模型的准确率为 72%(95%置信区间[CI]为 68%75%,曲线下面积[AUC]为.72),而我们的多层感知机和 XGBoost 模型的准确率均为 71%(95%CI为 67%74%,AUC为.70;95%CI为 68%75%,AUC为.70)。我们的三个模型之间的性能没有显著差异(均 p>.4),并且都优于外部的 XGBoost,后者在我们的数据上的准确率为 63%(95%CI为 59%67%,AUC为.62;p=.005,p=.01,p=.01)。所有模型的性能均随着样本量的增加而提高,但在我们目前的样本量之外,提高有限。最佳模型性能是通过数据驱动的特征选择实现的。
我们表明,复杂的机器学习模型的部署或仅数千名患者的汇集都不太可能显著提高我们预测术后无癫痫发作的能力。相反,我们提出需要改进特征选择,同时进行合作、数据标准化和模型共享,以推动该领域的发展。