Zhao Changheng, Wang Dan, Teng Jun, Yang Cheng, Zhang Xinyi, Wei Xianming, Zhang Qin
Shandong Provincial Key Laboratory of Animal Biotechnology and Disease Control and Prevention, College of Animal Science and Veterinary Medicine, Shandong Agricultural University, Tai'an, 271018, China.
J Anim Sci Biotechnol. 2023 Jun 1;14(1):85. doi: 10.1186/s40104-023-00880-x.
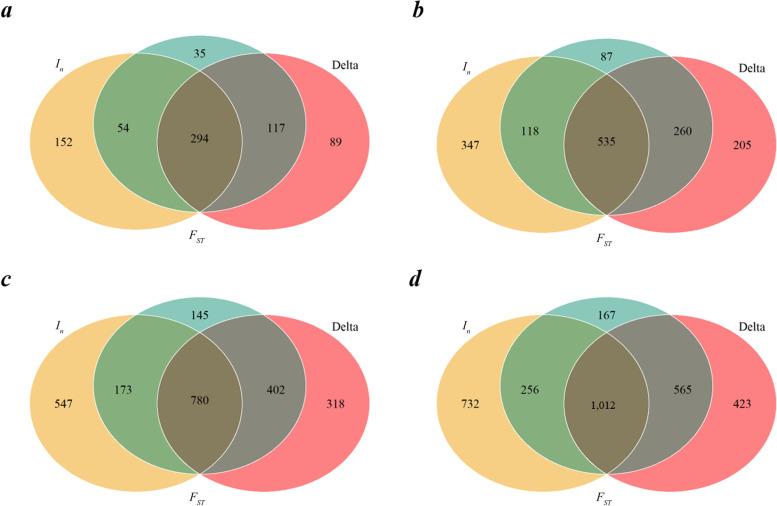
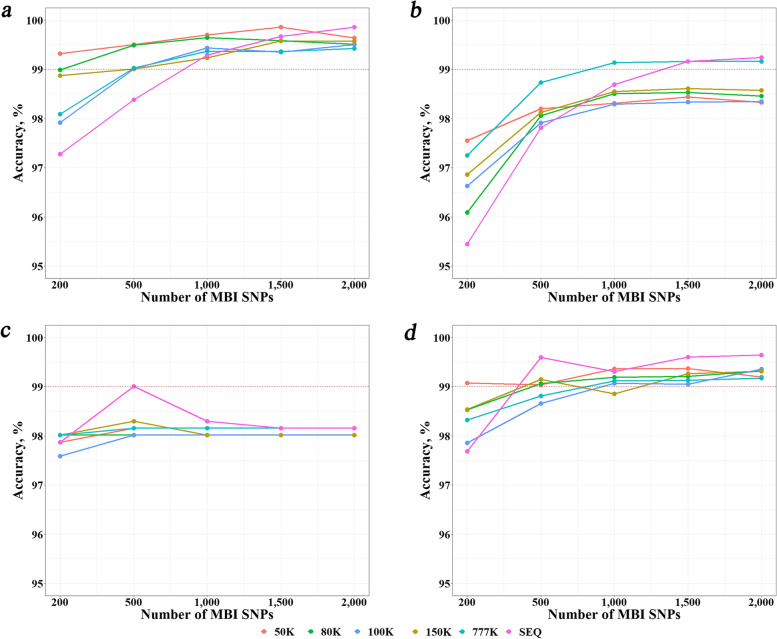
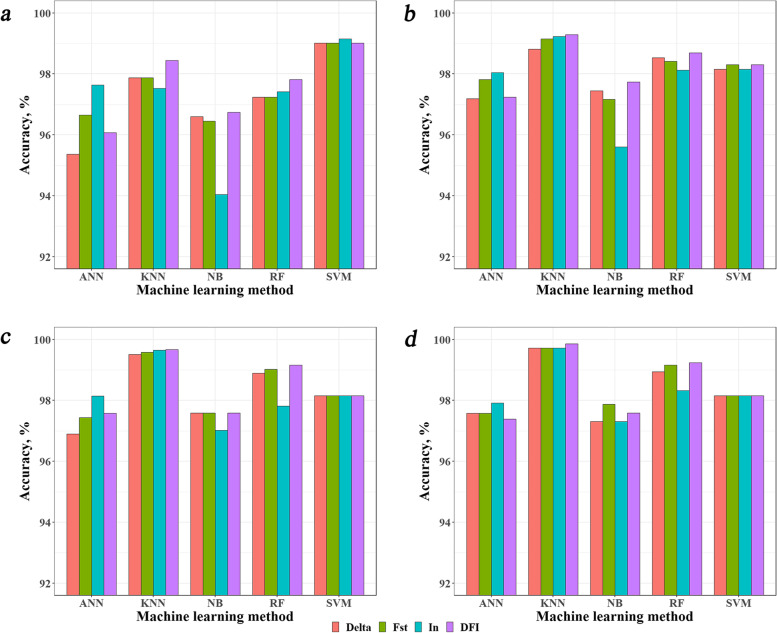
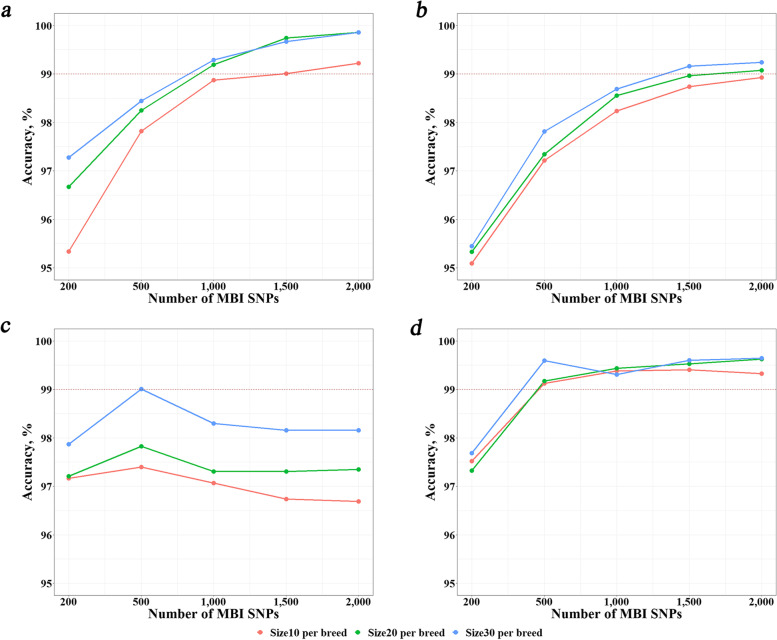
Breed identification is useful in a variety of biological contexts. Breed identification usually involves two stages, i.e., detection of breed-informative SNPs and breed assignment. For both stages, there are several methods proposed. However, what is the optimal combination of these methods remain unclear. In this study, using the whole genome sequence data available for 13 cattle breeds from Run 8 of the 1,000 Bull Genomes Project, we compared the combinations of three methods (Delta, F, and I) for breed-informative SNP detection and five machine learning methods (KNN, SVM, RF, NB, and ANN) for breed assignment with respect to different reference population sizes and difference numbers of most breed-informative SNPs. In addition, we evaluated the accuracy of breed identification using SNP chip data of different densities.
We found that all combinations performed quite well with identification accuracies over 95% in all scenarios. However, there was no combination which performed the best and robust across all scenarios. We proposed to integrate the three breed-informative detection methods, named DFI, and integrate the three machine learning methods, KNN, SVM, and RF, named KSR. We found that the combination of these two integrated methods outperformed the other combinations with accuracies over 99% in most cases and was very robust in all scenarios. The accuracies from using SNP chip data were only slightly lower than that from using sequence data in most cases.
The current study showed that the combination of DFI and KSR was the optimal strategy. Using sequence data resulted in higher accuracies than using chip data in most cases. However, the differences were generally small. In view of the cost of genotyping, using chip data is also a good option for breed identification.
品种鉴定在多种生物学背景下都很有用。品种鉴定通常涉及两个阶段,即品种信息性单核苷酸多态性(SNP)的检测和品种归属。对于这两个阶段,都提出了几种方法。然而,这些方法的最佳组合仍不清楚。在本研究中,我们使用来自1000头公牛基因组计划第8轮的13个牛品种的全基因组序列数据,针对不同的参考群体大小和最多品种信息性SNP的差异数量,比较了三种品种信息性SNP检测方法(Delta、F和I)与五种品种归属机器学习方法(KNN、SVM、RF、NB和ANN)的组合。此外,我们使用不同密度的SNP芯片数据评估了品种鉴定的准确性。
我们发现所有组合在所有情况下的鉴定准确率都超过95%,表现都相当不错。然而,没有一种组合在所有情况下都是表现最佳且稳健的。我们建议整合三种品种信息性检测方法,命名为DFI,并整合三种机器学习方法KNN、SVM和RF,命名为KSR。我们发现这两种整合方法的组合在大多数情况下的准确率超过99%,优于其他组合,并且在所有情况下都非常稳健。在大多数情况下,使用SNP芯片数据的准确率仅略低于使用序列数据的准确率。
当前研究表明,DFI和KSR的组合是最佳策略。在大多数情况下,使用序列数据比使用芯片数据的准确率更高。然而,差异通常较小。鉴于基因分型的成本,使用芯片数据也是品种鉴定的一个不错选择。