Australian Institute for Microbiology and Infection, University of Technology Sydney, Ultimo, NSW, Australia.
Centre for Computational Evolution, The University of Auckland, Auckland, New Zealand.
Genome Biol Evol. 2023 Jun 1;15(6). doi: 10.1093/gbe/evad099.
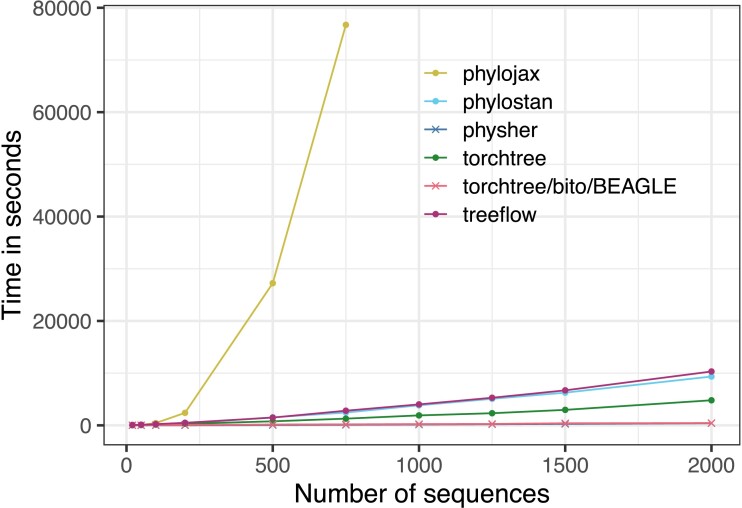
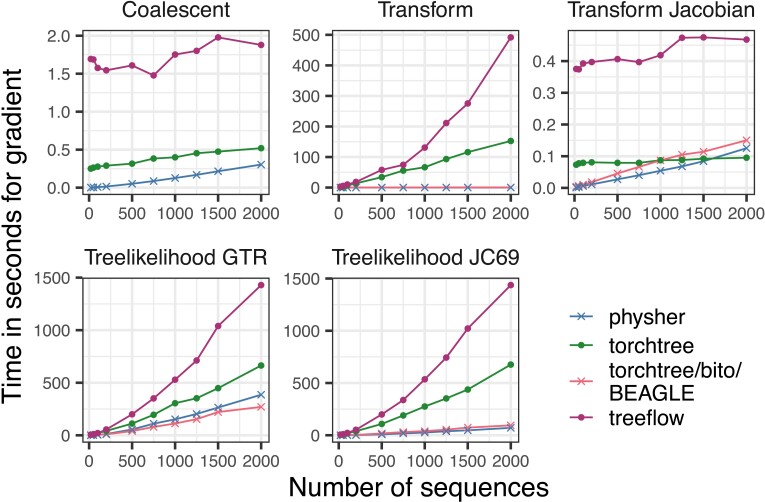
Gradients of probabilistic model likelihoods with respect to their parameters are essential for modern computational statistics and machine learning. These calculations are readily available for arbitrary models via "automatic differentiation" implemented in general-purpose machine-learning libraries such as TensorFlow and PyTorch. Although these libraries are highly optimized, it is not clear if their general-purpose nature will limit their algorithmic complexity or implementation speed for the phylogenetic case compared to phylogenetics-specific code. In this paper, we compare six gradient implementations of the phylogenetic likelihood functions, in isolation and also as part of a variational inference procedure. We find that although automatic differentiation can scale approximately linearly in tree size, it is much slower than the carefully implemented gradient calculation for tree likelihood and ratio transformation operations. We conclude that a mixed approach combining phylogenetic libraries with machine learning libraries will provide the optimal combination of speed and model flexibility moving forward.
概率模型似然相对于其参数的梯度对于现代计算统计学和机器学习至关重要。这些计算可以通过在 TensorFlow 和 PyTorch 等通用机器学习库中实现的“自动微分”来轻松地为任意模型完成。尽管这些库经过了高度优化,但与特定于系统发育学的代码相比,它们的通用性是否会限制其算法复杂度或在系统发育学情况下的实现速度尚不清楚。在本文中,我们比较了六个用于系统发育似然函数的梯度实现,分别孤立地和作为变分推断过程的一部分进行比较。我们发现,尽管自动微分可以在树大小上大致呈线性扩展,但它比针对树似然和比值变换操作精心实现的梯度计算要慢得多。我们得出结论,一种结合系统发育学库和机器学习库的混合方法将为未来的速度和模型灵活性提供最佳组合。