Lunghini Filippo, Fava Anna, Pisapia Vincenzo, Sacco Francesco, Iaconis Daniela, Beccari Andrea Rosario
EXSCALATE, Dompé Farmaceutici SpA, Via Tommaso de Amicis 95, 80123, Naples, Italy.
Professional Service Department, SAS Institute, Via Darwin 20/22, 20143, Milan, Italy.
J Cheminform. 2023 Jun 9;15(1):60. doi: 10.1186/s13321-023-00728-6.
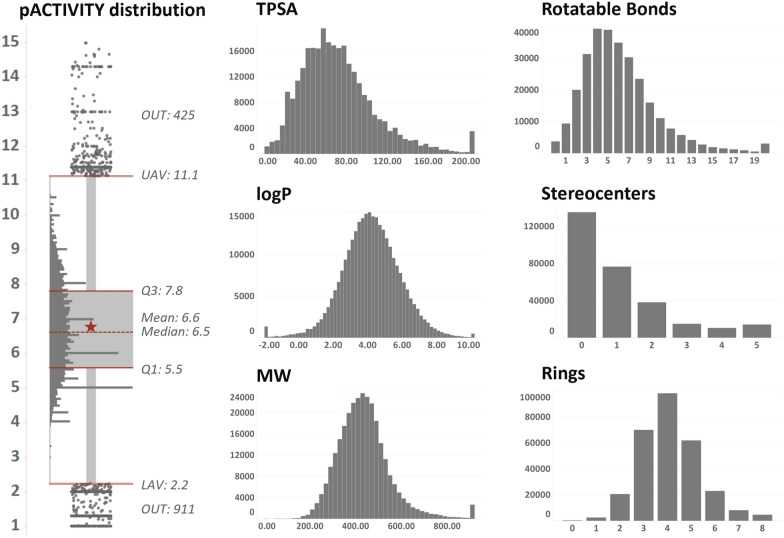
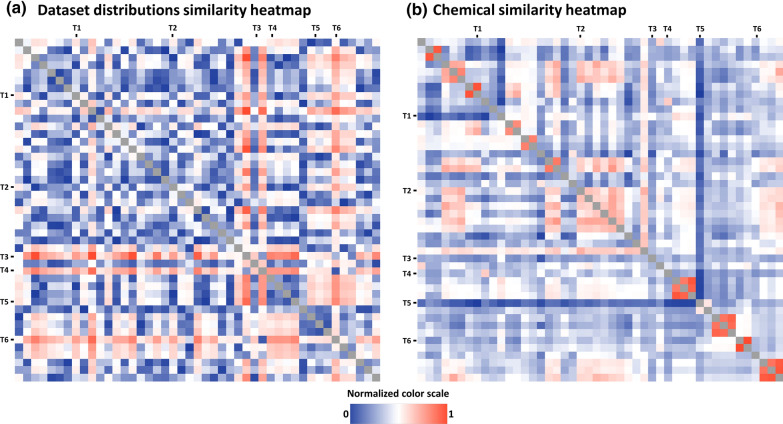
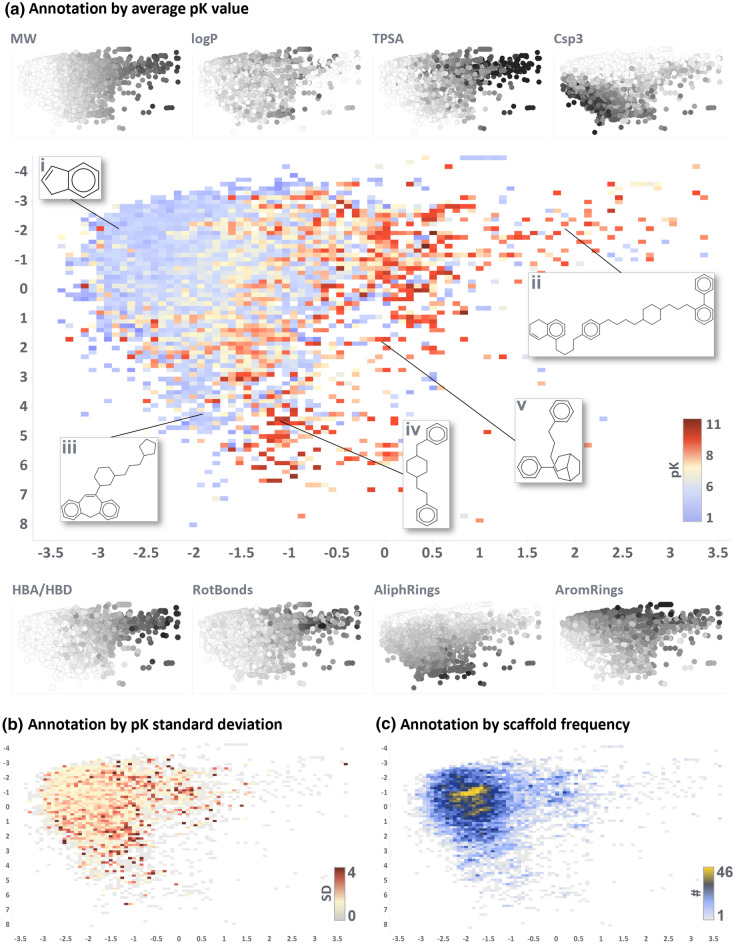
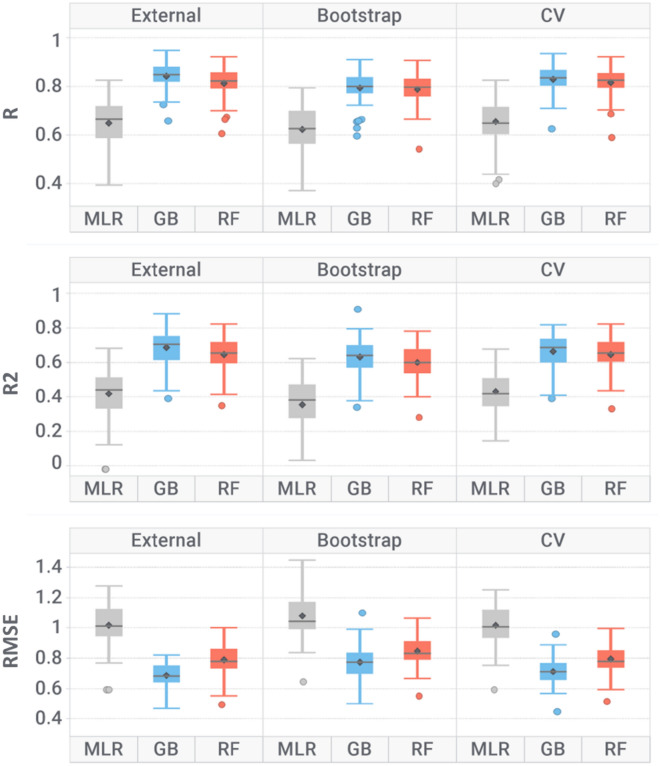
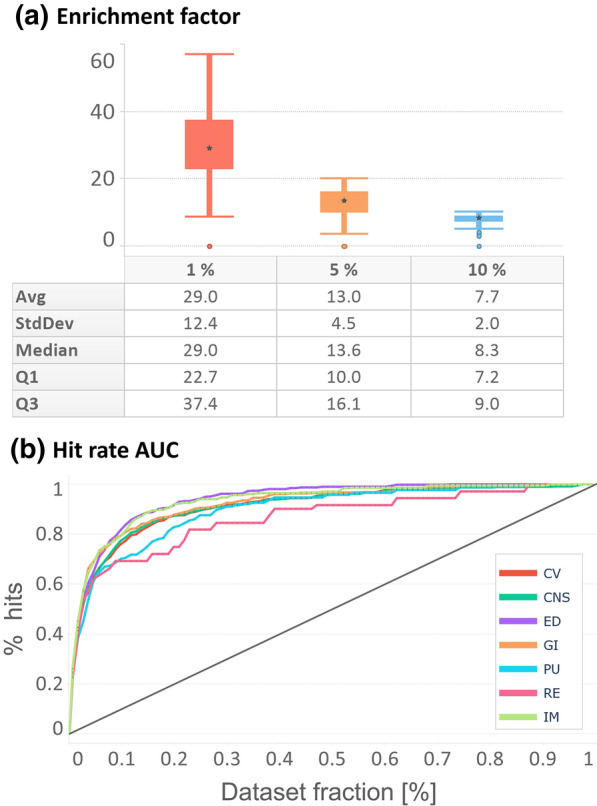
Off-target drug interactions are a major reason for candidate failure in the drug discovery process. Anticipating potential drug's adverse effects in the early stages is necessary to minimize health risks to patients, animal testing, and economical costs. With the constantly increasing size of virtual screening libraries, AI-driven methods can be exploited as first-tier screening tools to provide liability estimation for drug candidates. In this work we present ProfhEX, an AI-driven suite of 46 OECD-compliant machine learning models that can profile small molecules on 7 relevant liability groups: cardiovascular, central nervous system, gastrointestinal, endocrine, renal, pulmonary and immune system toxicities. Experimental affinity data was collected from public and commercial data sources. The entire chemical space comprised 289'202 activity data for a total of 210'116 unique compounds, spanning over 46 targets with dataset sizes ranging from 819 to 18896. Gradient boosting and random forest algorithms were initially employed and ensembled for the selection of a champion model. Models were validated according to the OECD principles, including robust internal (cross validation, bootstrap, y-scrambling) and external validation. Champion models achieved an average Pearson correlation coefficient of 0.84 (SD of 0.05), an R determination coefficient of 0.68 (SD = 0.1) and a root mean squared error of 0.69 (SD of 0.08). All liability groups showed good hit-detection power with an average enrichment factor at 5% of 13.1 (SD of 4.5) and AUC of 0.92 (SD of 0.05). Benchmarking against already existing tools demonstrated the predictive power of ProfhEX models for large-scale liability profiling. This platform will be further expanded with the inclusion of new targets and through complementary modelling approaches, such as structure and pharmacophore-based models. ProfhEX is freely accessible at the following address: https://profhex.exscalate.eu/ .
脱靶药物相互作用是药物研发过程中候选药物失败的主要原因。在早期阶段预测潜在药物的不良反应对于将患者健康风险、动物试验和经济成本降至最低至关重要。随着虚拟筛选库规模的不断扩大,人工智能驱动的方法可被用作一级筛选工具,为候选药物提供安全性评估。在这项工作中,我们展示了ProfhEX,这是一套由人工智能驱动的、符合经合组织标准的46个机器学习模型,可对小分子在7个相关安全性类别上进行分析:心血管、中枢神经系统、胃肠道、内分泌、肾脏、肺部和免疫系统毒性。实验亲和力数据来自公共和商业数据源。整个化学空间包含针对总共210116种独特化合物的289202条活性数据,涵盖46个靶点,数据集大小从819到18896不等。最初采用梯度提升和随机森林算法并进行集成,以选择最优模型。模型根据经合组织原则进行验证,包括强大的内部验证(交叉验证、自助法、y轴混淆)和外部验证。最优模型的平均皮尔逊相关系数为0.84(标准差为0.05),决定系数R为0.68(标准差 = 0.1),均方根误差为0.69(标准差为0.08)。所有安全性类别均显示出良好的命中检测能力,5%时的平均富集因子为13.1(标准差为4.5),曲线下面积为0.92(标准差为0.05)。与现有工具的基准测试证明了ProfhEX模型在大规模安全性分析方面的预测能力。该平台将通过纳入新靶点并采用互补建模方法(如基于结构和药效团的模型)进一步扩展。可通过以下网址免费访问ProfhEX:https://profhex.exscalate.eu/ 。