Litsa Eleni E, Chenthamarakshan Vijil, Das Payel, Kavraki Lydia E
Department of Computer Science, Rice University, Houston, TX, USA.
IBM Research, IBM Thomas J. Watson Research Center, Yorktown Heights, NY, USA.
Commun Chem. 2023 Jun 23;6(1):132. doi: 10.1038/s42004-023-00932-3.
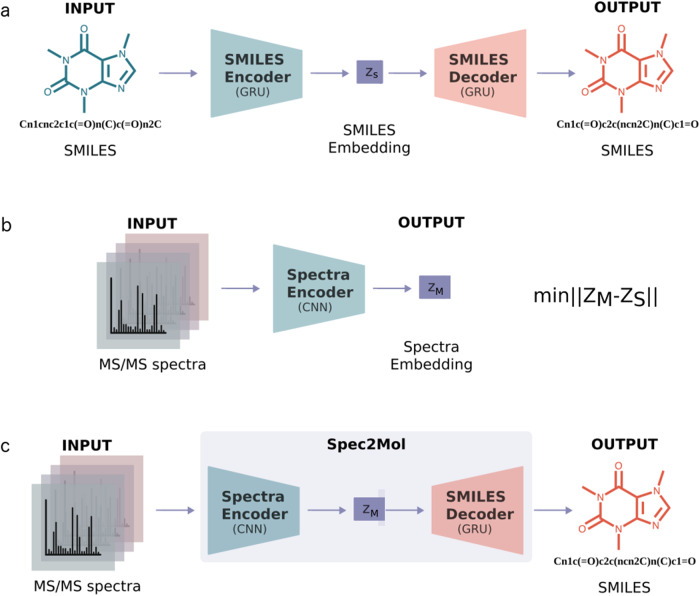
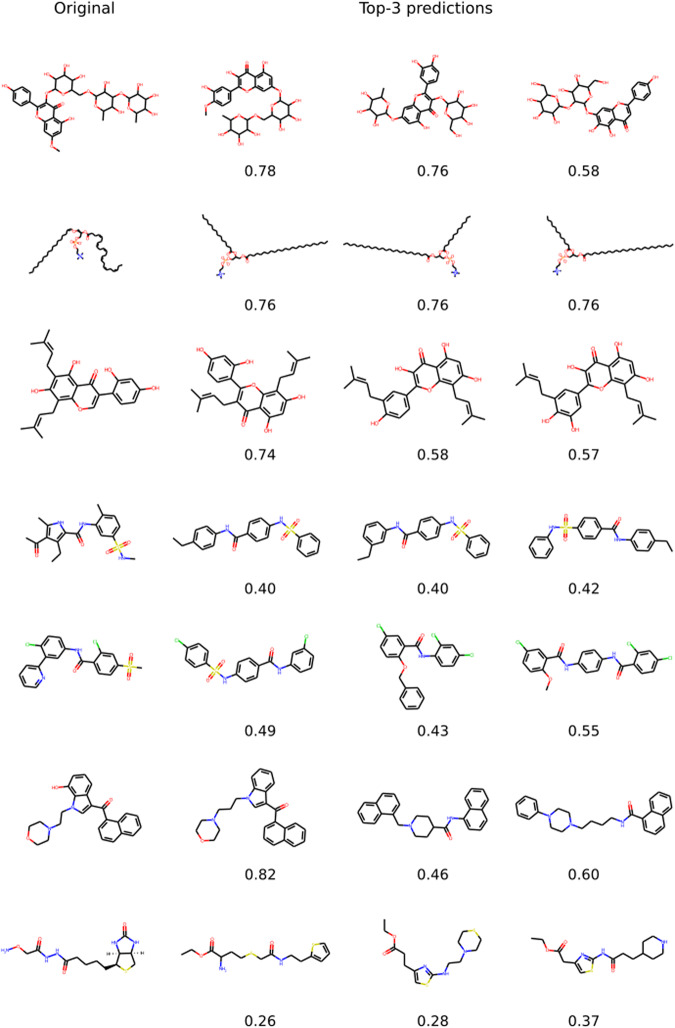
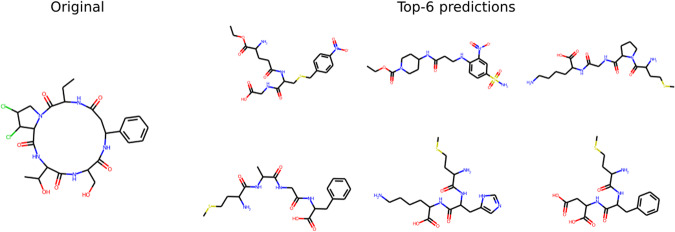
Elucidating the structure of a chemical compound is a fundamental task in chemistry with applications in multiple domains including drug discovery, precision medicine, and biomarker discovery. The common practice for elucidating the structure of a compound is to obtain a mass spectrum and subsequently retrieve its structure from spectral databases. However, these methods fail for novel molecules that are not present in the reference database. We propose Spec2Mol, a deep learning architecture for molecular structure recommendation given mass spectra alone. Spec2Mol is inspired by the Speech2Text deep learning architectures for translating audio signals into text. Our approach is based on an encoder-decoder architecture. The encoder learns the spectra embeddings, while the decoder, pre-trained on a massive dataset of chemical structures for translating between different molecular representations, reconstructs SMILES sequences of the recommended chemical structures. We have evaluated Spec2Mol by assessing the molecular similarity between the recommended structures and the original structure. Our analysis showed that Spec2Mol is able to identify the presence of key molecular substructures from its mass spectrum, and shows on par performance, when compared to existing fragmentation tree methods particularly when test structure information is not available during training or present in the reference database.
阐明化合物的结构是化学中的一项基础任务,在药物发现、精准医学和生物标志物发现等多个领域都有应用。阐明化合物结构的常见做法是获取质谱,随后从光谱数据库中检索其结构。然而,对于参考数据库中不存在的新分子,这些方法就失效了。我们提出了Spec2Mol,这是一种仅根据质谱就能进行分子结构推荐的深度学习架构。Spec2Mol的灵感来源于将音频信号转换为文本的Speech2Text深度学习架构。我们的方法基于编码器-解码器架构。编码器学习光谱嵌入,而解码器在大量化学结构数据集上进行预训练,用于在不同分子表示之间进行转换,从而重建推荐化学结构的SMILES序列。我们通过评估推荐结构与原始结构之间的分子相似性来评估Spec2Mol。我们的分析表明,Spec2Mol能够从其质谱中识别关键分子子结构的存在,并且与现有的碎片树方法相比,表现相当,特别是在训练期间没有测试结构信息或参考数据库中不存在测试结构信息的情况下。