National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, USA.
School of Biomedical Informatics, UTHealth, Houston, USA.
BMC Med Inform Decis Mak. 2020 Apr 30;20(Suppl 1):73. doi: 10.1186/s12911-020-1044-0.
Capturing sentence semantics plays a vital role in a range of text mining applications. Despite continuous efforts on the development of related datasets and models in the general domain, both datasets and models are limited in biomedical and clinical domains. The BioCreative/OHNLP2018 organizers have made the first attempt to annotate 1068 sentence pairs from clinical notes and have called for a community effort to tackle the Semantic Textual Similarity (BioCreative/OHNLP STS) challenge.
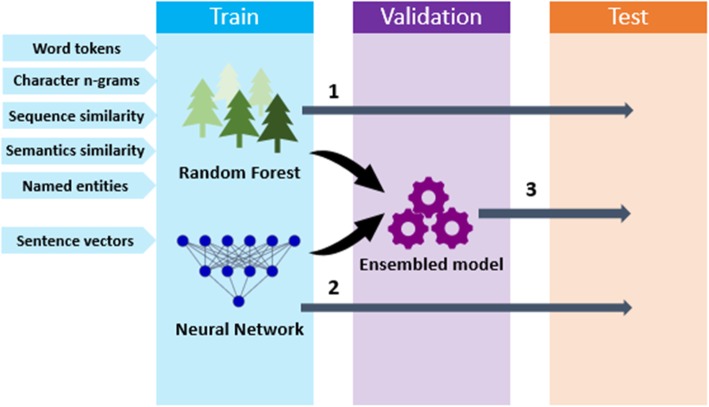
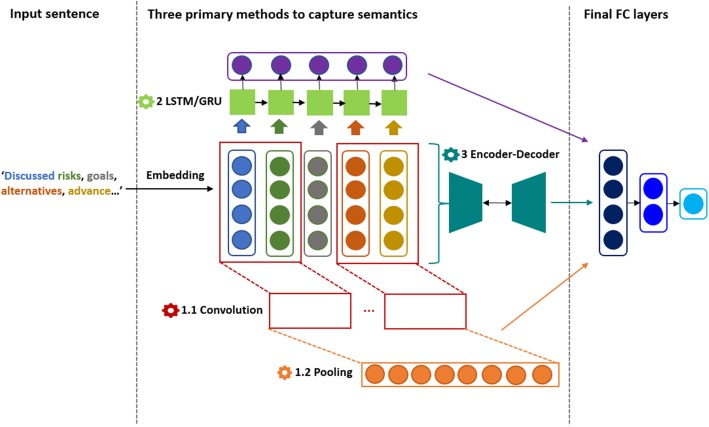
We developed models using traditional machine learning and deep learning approaches. For the post challenge, we focused on two models: the Random Forest and the Encoder Network. We applied sentence embeddings pre-trained on PubMed abstracts and MIMIC-III clinical notes and updated the Random Forest and the Encoder Network accordingly.
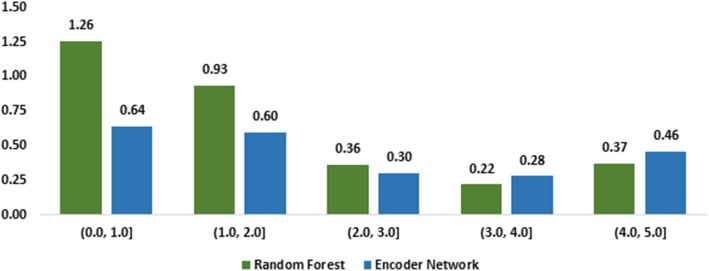
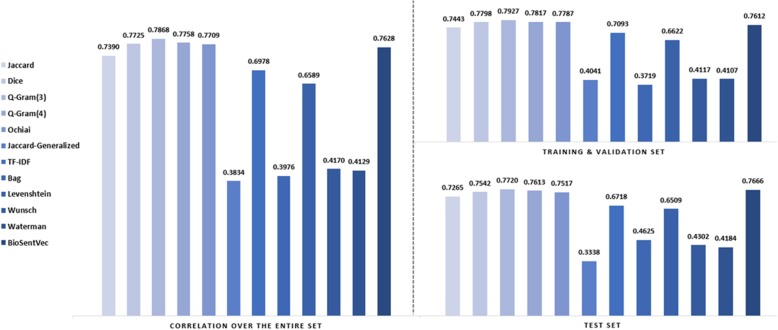
The official results demonstrated our best submission was the ensemble of eight models. It achieved a Person correlation coefficient of 0.8328 - the highest performance among 13 submissions from 4 teams. For the post challenge, the performance of both Random Forest and the Encoder Network was improved; in particular, the correlation of the Encoder Network was improved by ~ 13%. During the challenge task, no end-to-end deep learning models had better performance than machine learning models that take manually-crafted features. In contrast, with the sentence embeddings pre-trained on biomedical corpora, the Encoder Network now achieves a correlation of ~ 0.84, which is higher than the original best model. The ensembled model taking the improved versions of the Random Forest and Encoder Network as inputs further increased performance to 0.8528.
Deep learning models with sentence embeddings pre-trained on biomedical corpora achieve the highest performance on the test set. Through error analysis, we find that end-to-end deep learning models and traditional machine learning models with manually-crafted features complement each other by finding different types of sentences. We suggest a combination of these models can better find similar sentences in practice.
捕捉句子语义在一系列文本挖掘应用中起着至关重要的作用。尽管在一般领域中不断努力开发相关数据集和模型,但这些数据集和模型在生物医学和临床领域都受到限制。BioCreative/OHNLP2018 组织者首次尝试对来自临床记录的 1068 对句子进行注释,并呼吁社区共同努力应对语义文本相似性(BioCreative/OHNLP STS)挑战。
我们使用传统的机器学习和深度学习方法开发模型。对于后期挑战,我们专注于两个模型:随机森林和编码器网络。我们应用了在 PubMed 摘要和 MIMIC-III 临床记录上预训练的句子嵌入,并相应地更新了随机森林和编码器网络。
官方结果表明,我们的最佳提交是八个模型的集成。它实现了 0.8328 的人员相关系数-在来自 4 个团队的 13 个提交中表现最好。对于后期挑战,随机森林和编码器网络的性能都得到了提高;特别是,编码器网络的相关性提高了约 13%。在挑战任务中,没有端到端的深度学习模型比采用人工制作特征的机器学习模型表现更好。相比之下,使用生物医学语料库预训练的句子嵌入,编码器网络现在实现了约 0.84 的相关性,高于原始最佳模型。集成模型将经过改进的随机森林和编码器网络作为输入,进一步将性能提高到 0.8528。
使用生物医学语料库预训练的句子嵌入的深度学习模型在测试集上实现了最高性能。通过错误分析,我们发现端到端的深度学习模型和采用人工制作特征的传统机器学习模型通过找到不同类型的句子来互补。我们建议在实践中结合这些模型可以更好地找到相似的句子。