Singh Noor Pratap, Love Michael I, Patro Rob
Department of Computer Science, University of Maryland, College Park, MD, USA.
Department of Biostatistics, University of North Carolina, Chapel Hill, NC, USA.
iScience. 2023 May 25;26(6):106961. doi: 10.1016/j.isci.2023.106961. eCollection 2023 Jun 16.
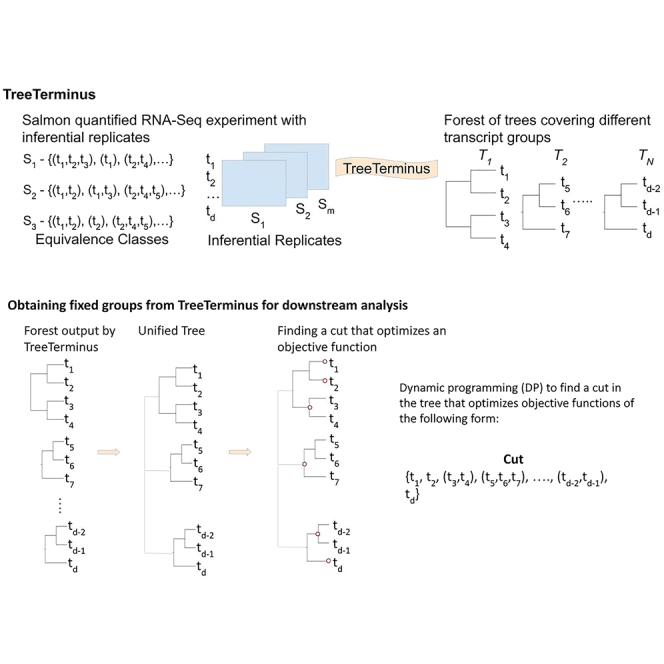
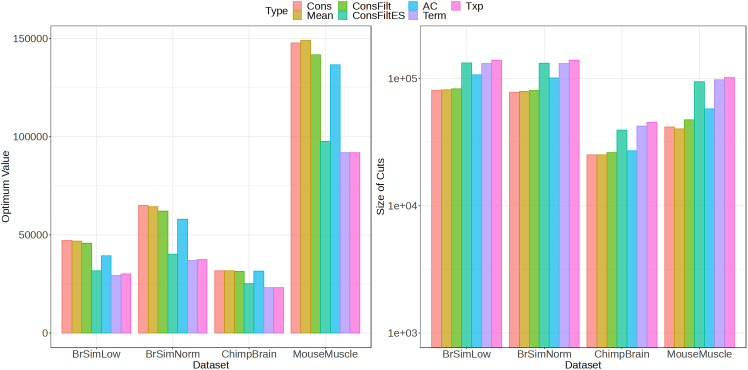
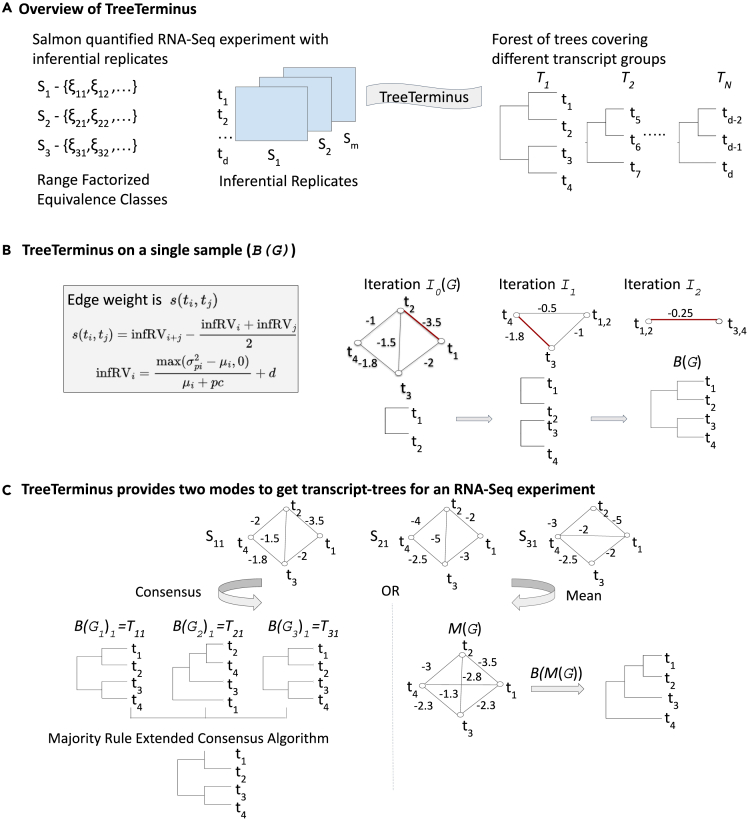
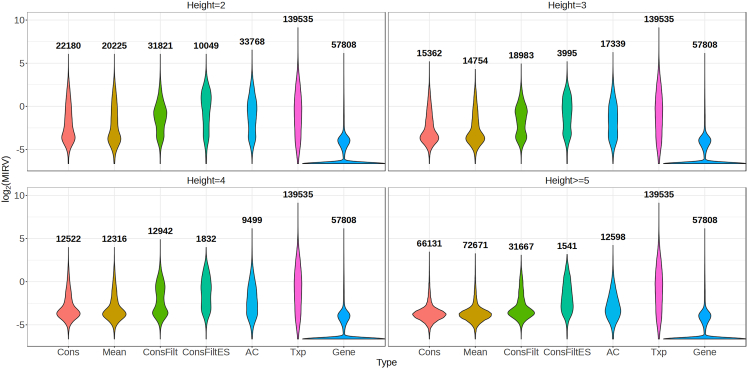
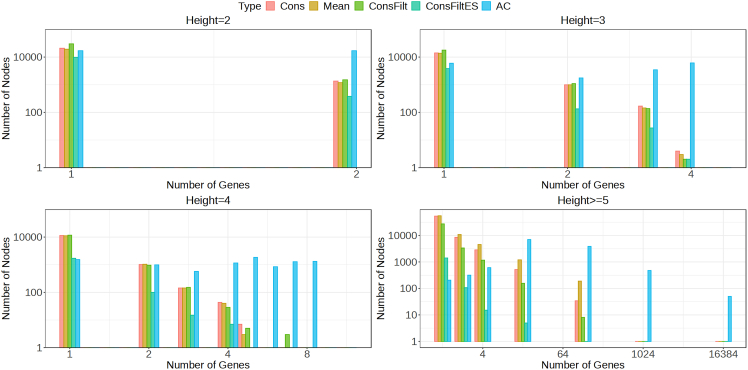
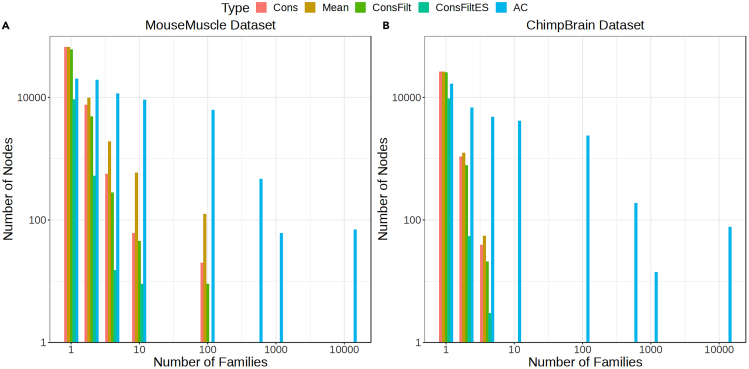
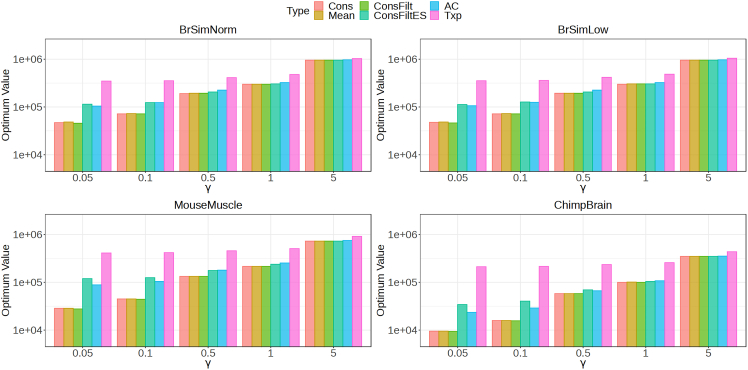
A certain degree of uncertainty is always associated with the transcript abundance estimates. The uncertainty may make many downstream analyses, such as differential testing, difficult for certain transcripts. Conversely, gene-level analysis, though less ambiguous, is often too coarse-grained. We introduce TreeTerminus, a data-driven approach for grouping transcripts into a tree structure where leaves represent individual transcripts and internal nodes represent an aggregation of a transcript set. TreeTerminus constructs trees such that, on average, the inferential uncertainty decreases as we ascend the tree topology. The tree provides the flexibility to analyze data at nodes that are at different levels of resolution in the tree and can be tuned depending on the analysis of interest. We evaluated TreeTerminus on two simulated and two experimental datasets and observed an improved performance compared to transcripts (leaves) and other methods under several different metrics.
转录本丰度估计总是伴随着一定程度的不确定性。这种不确定性可能会使许多下游分析(如差异检测)对某些转录本来说变得困难。相反,基因水平的分析虽然不那么模糊,但往往过于粗粒度。我们引入了TreeTerminus,这是一种数据驱动的方法,用于将转录本分组为树状结构,其中叶节点代表单个转录本,内部节点代表转录本集的聚合。TreeTerminus构建的树使得平均而言,随着我们沿着树的拓扑结构向上,推断的不确定性会降低。该树提供了在树中不同分辨率级别的节点上分析数据的灵活性,并且可以根据感兴趣的分析进行调整。我们在两个模拟数据集和两个实验数据集上对TreeTerminus进行了评估,并观察到在几种不同指标下,与转录本(叶节点)和其他方法相比,其性能有所提高。