Department of Computer Science, Brock University, St. Catharines, Canada.
Broad Institute of MIT and Harvard, Cambridge, Massachusetts, United States of America.
PLoS Comput Biol. 2023 Jul 5;19(7):e1010774. doi: 10.1371/journal.pcbi.1010774. eCollection 2023 Jul.
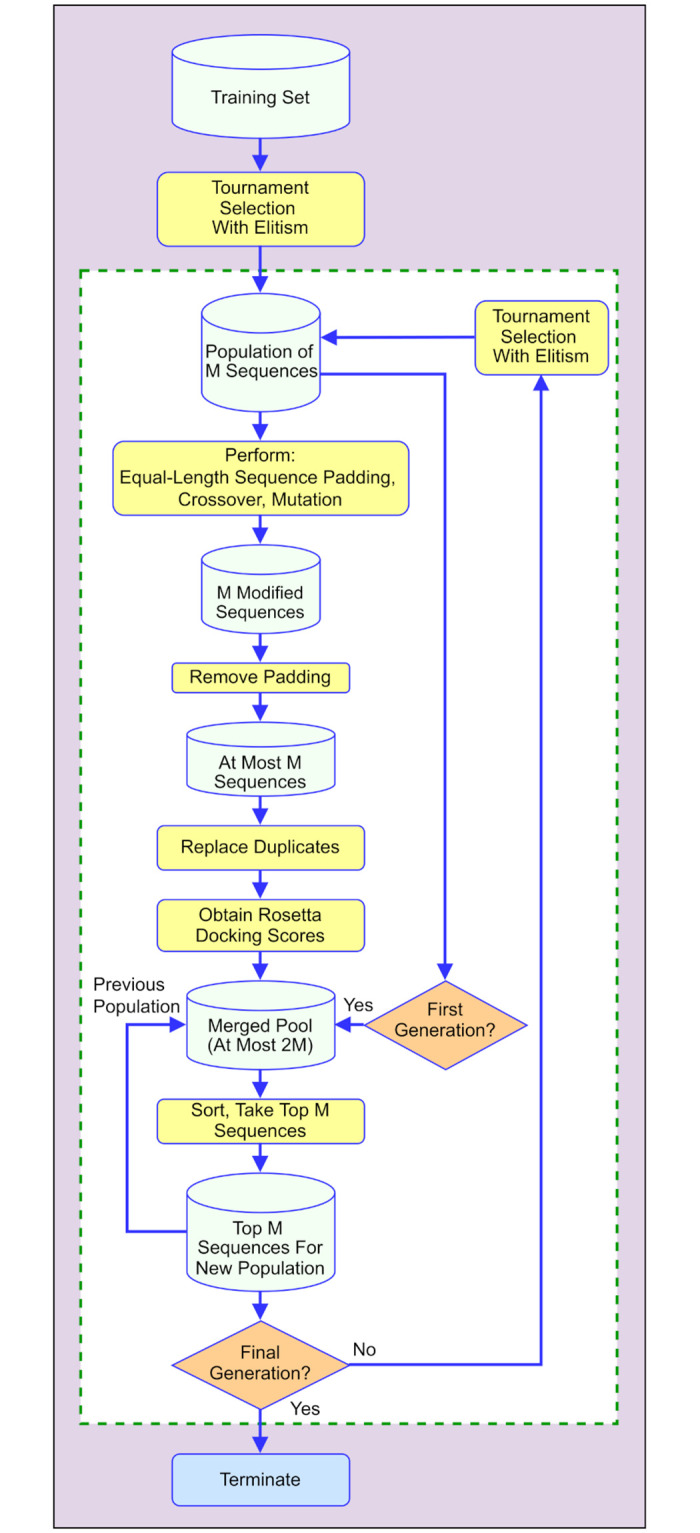
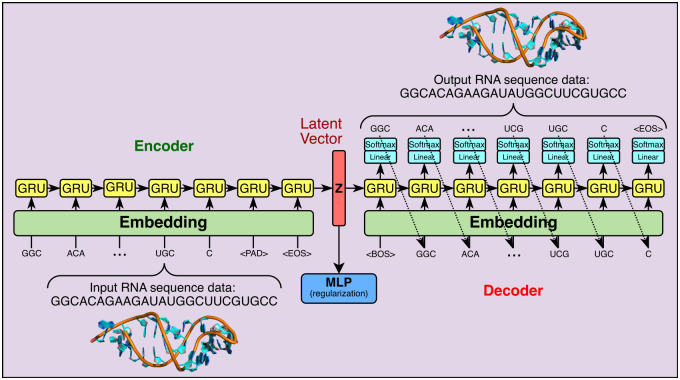
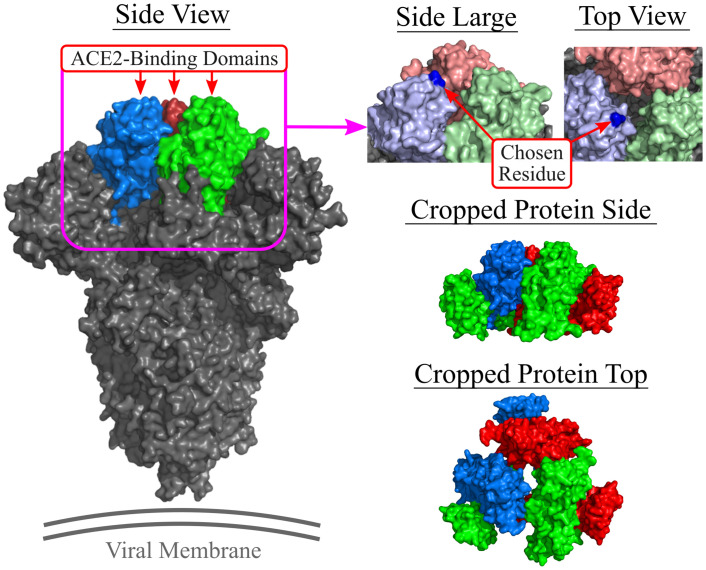
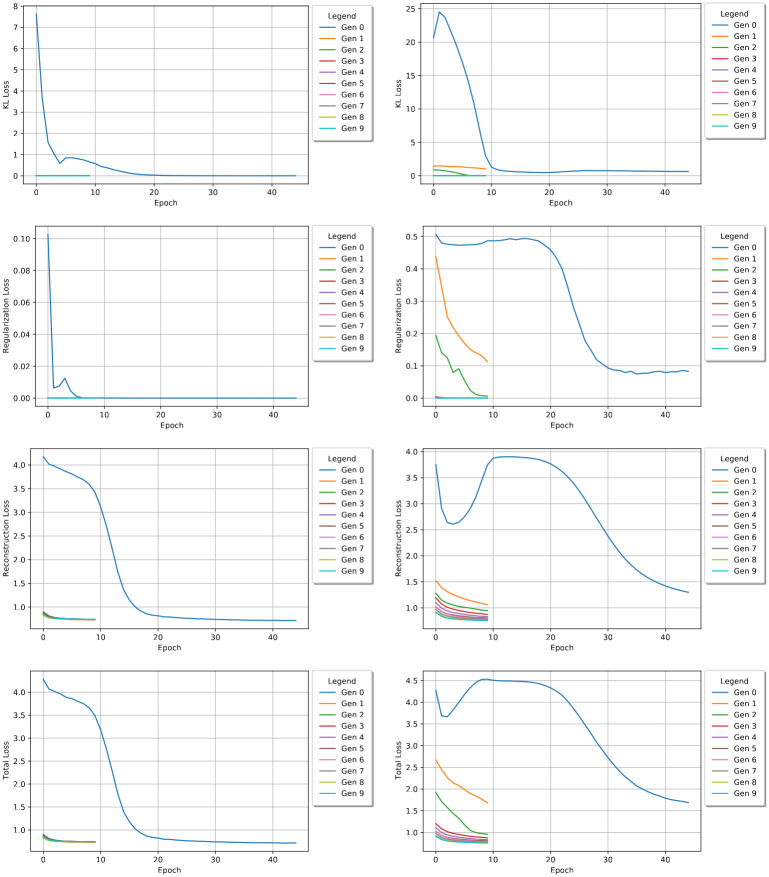
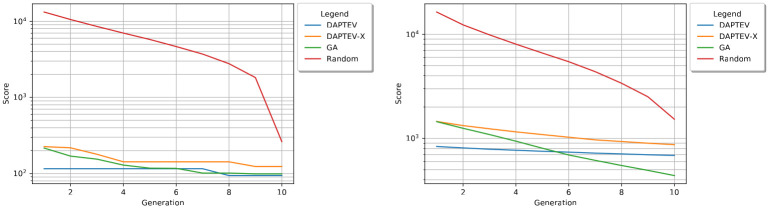
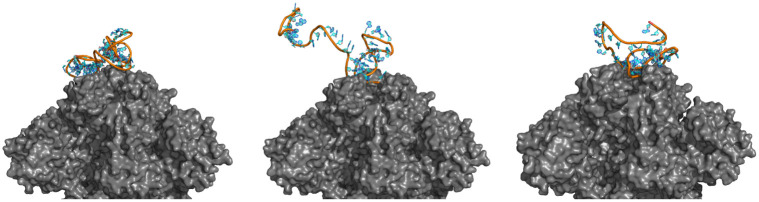
Typical drug discovery and development processes are costly, time consuming and often biased by expert opinion. Aptamers are short, single-stranded oligonucleotides (RNA/DNA) that bind to target proteins and other types of biomolecules. Compared with small-molecule drugs, aptamers can bind to their targets with high affinity (binding strength) and specificity (uniquely interacting with the target only). The conventional development process for aptamers utilizes a manual process known as Systematic Evolution of Ligands by Exponential Enrichment (SELEX), which is costly, slow, dependent on library choice and often produces aptamers that are not optimized. To address these challenges, in this research, we create an intelligent approach, named DAPTEV, for generating and evolving aptamer sequences to support aptamer-based drug discovery and development. Using the COVID-19 spike protein as a target, our computational results suggest that DAPTEV is able to produce structurally complex aptamers with strong binding affinities.
典型的药物发现和开发过程既昂贵又耗时,而且往往受到专家意见的影响。适体是短的、单链的寡核苷酸(RNA/DNA),可以与靶蛋白和其他类型的生物分子结合。与小分子药物相比,适体可以与靶标高亲和力(结合强度)和特异性(仅与靶标独特相互作用)结合。适体的常规开发过程利用一种称为指数富集的配体系统进化(SELEX)的手动过程,该过程既昂贵又缓慢,依赖于文库选择,并且经常产生未优化的适体。为了解决这些挑战,在这项研究中,我们创建了一种名为 DAPTEV 的智能方法,用于生成和进化适体序列,以支持基于适体的药物发现和开发。使用 COVID-19 刺突蛋白作为靶标,我们的计算结果表明,DAPTEV 能够产生具有强结合亲和力的结构复杂的适体。