Center for Reproductive Medicine, Department of Gynecology and Obstetrics, Nanfang Hospital, Southern Medical University, Guangzhou, 510515, China.
BMC Med Inform Decis Mak. 2023 Jul 18;23(1):126. doi: 10.1186/s12911-023-02239-8.
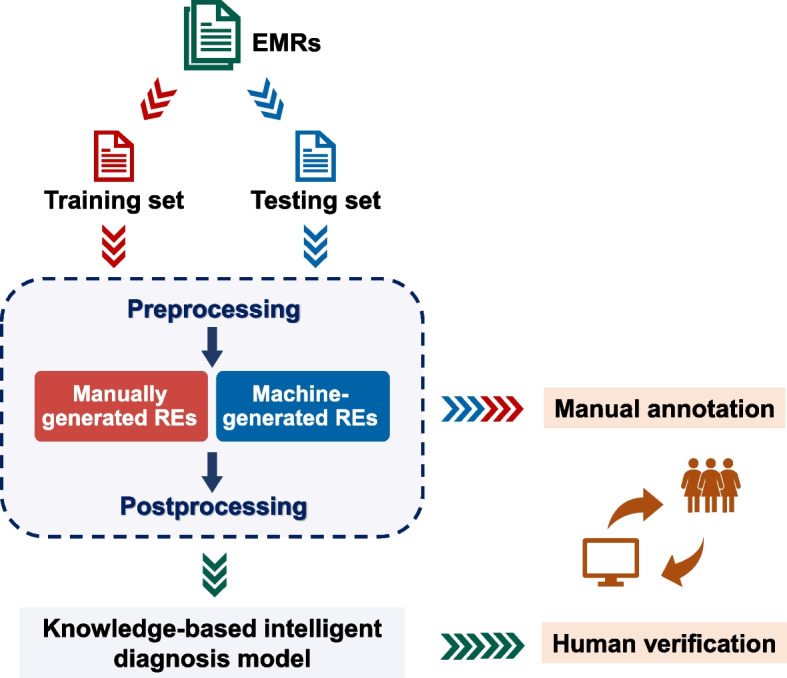
The ovarian reserve is a reservoir for reproductive potential. In clinical practice, early detection and treatment of premature ovarian decline characterized by abnormal ovarian reserve tests is regarded as a critical measure to prevent infertility. However, the relevant data are typically stored in an unstructured format in a hospital's electronic medical record (EMR) system, and their retrieval requires tedious manual abstraction by domain experts. Computational tools are therefore needed to reduce the workload.
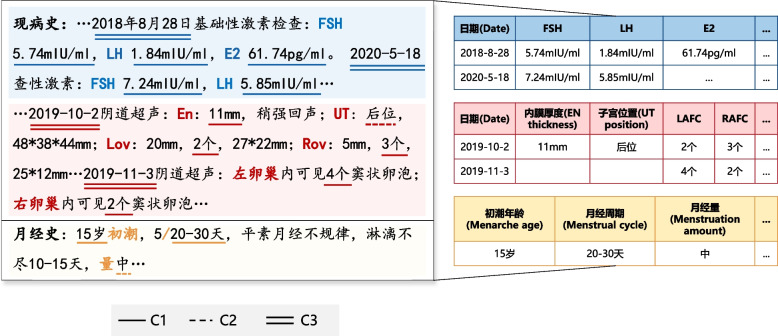
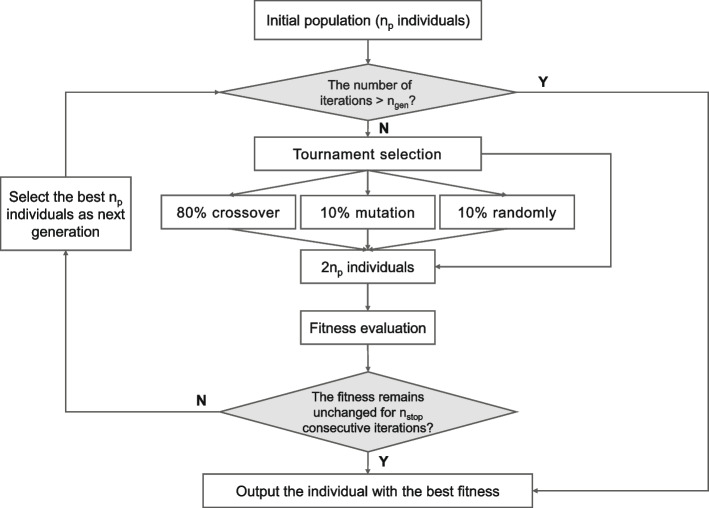
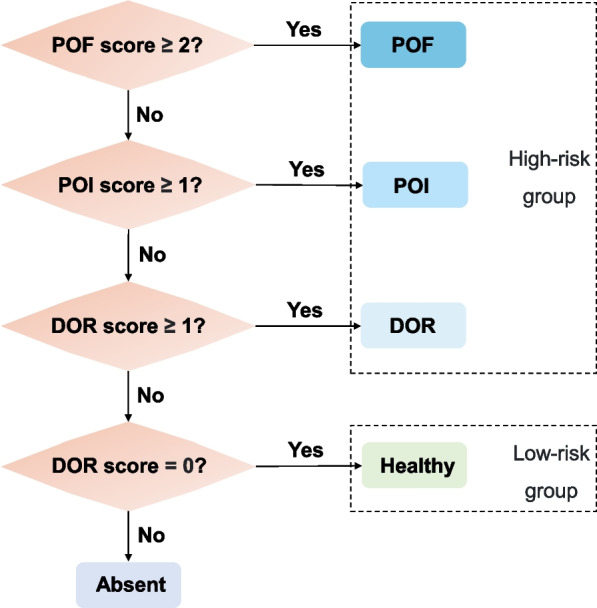
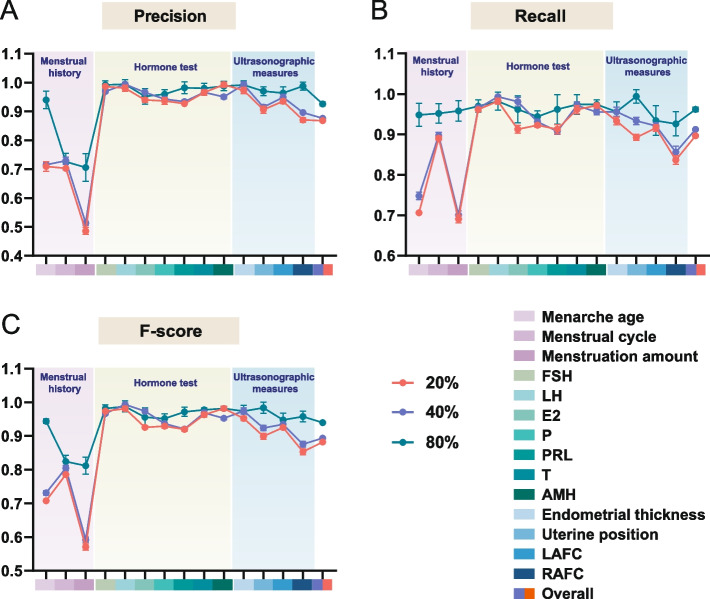
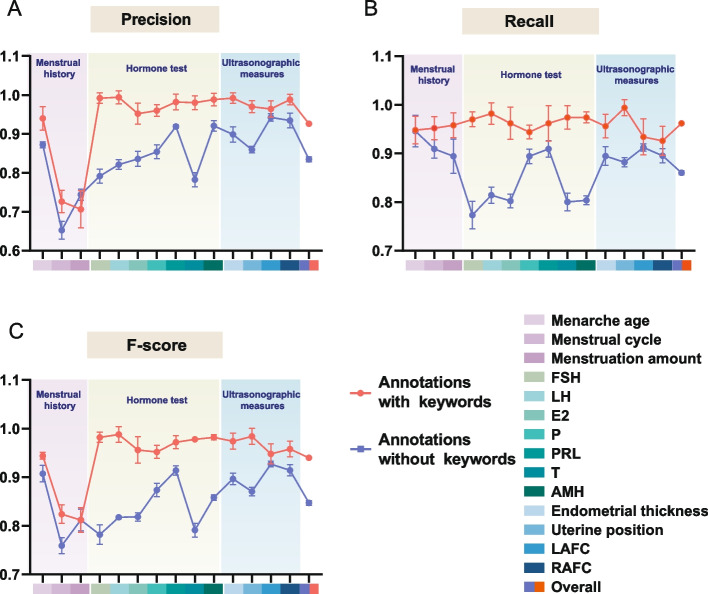
We presented RegEMR, an artificial intelligence tool composed of a rule-based natural language processing (NLP) extractor and a knowledge-based disease scoring model, to automatize the screening procedure of premature ovarian decline using Chinese reproductive EMRs. We used regular expressions (REs) as a text mining method and explored whether REs automatically synthesized by the genetic programming-based online platform RegexGenerator + + could be as effective as manually formulated REs. We also investigated how the representativeness of the learning corpus affected the performance of machine-generated REs. Additionally, we translated the clinical diagnostic criteria into a programmable disease diagnostic model for disease scoring and risk stratification. Four hundred outpatient medical records were collected from a Chinese fertility center. Manual review served as the gold standard, and fivefold cross-validation was used for evaluation.
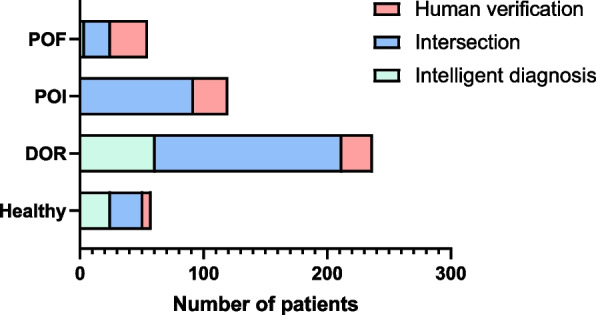
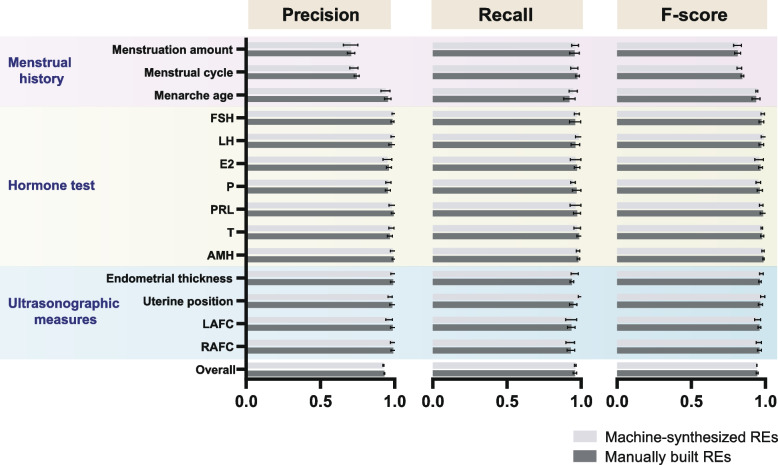
The overall F-score of manually built REs was 0.9444 (95% CI 0.9373 to 0.9515), with no significant difference (paired t test p > 0.05) compared with machine-generated REs that could be affected by training set sizes and annotation portions. The extractor performed effectively in automatically tracing the dynamic changes in hormone levels (F-score 0.9518-0.9884) and ultrasonographic measures (F-score 0.9472-0.9822). Applying the extracted information to the proposed diagnostic model, the program obtained an accuracy of 0.98 and a sensitivity of 0.93 in risk screening. For each specific disease, the automatic diagnosis in 76% of patients was consistent with that of the clinical diagnosis, and the kappa coefficient was 0.63.
A Chinese NLP system named RegEMR was developed to automatically identify high risk of early ovarian aging and diagnose related diseases from Chinese reproductive EMRs. We hope that this system can aid EMR-based data collection and clinical decision support in fertility centers.
卵巢储备是生殖潜能的储备库。在临床实践中,早期发现和治疗以卵巢储备试验异常为特征的卵巢早衰被认为是预防不孕的关键措施。然而,相关数据通常以医院电子病历(EMR)系统中的非结构化格式存储,需要由领域专家进行繁琐的手动提取。因此,需要计算工具来减少工作量。
我们提出了 RegEMR,这是一个由基于规则的自然语言处理(NLP)提取器和基于知识的疾病评分模型组成的人工智能工具,用于使用中文生殖 EMR 自动化卵巢早衰的筛查程序。我们使用正则表达式(RE)作为文本挖掘方法,并探索了基于遗传编程的在线平台 RegexGenerator++自动合成的 RE 是否与手动制定的 RE 一样有效。我们还研究了学习语料库的代表性如何影响机器生成的 RE 的性能。此外,我们将临床诊断标准翻译成可编程疾病诊断模型,用于疾病评分和风险分层。从一家中国生育中心收集了 400 份门诊病历。手动审查作为金标准,采用五重交叉验证进行评估。
手动构建的 RE 的总体 F 分数为 0.9444(95%CI 0.9373 至 0.9515),与机器生成的 RE 没有显著差异(配对 t 检验 p>0.05),机器生成的 RE 可能受训练集大小和注释部分的影响。提取器在自动跟踪激素水平的动态变化(F 分数 0.9518-0.9884)和超声测量方面表现出色(F 分数 0.9472-0.9822)。将提取的信息应用于提出的诊断模型,该程序在风险筛查中获得了 0.98 的准确率和 0.93 的敏感性。对于每种特定疾病,76%的患者的自动诊断与临床诊断一致,kappa 系数为 0.63。
开发了一种名为 RegEMR 的中文 NLP 系统,用于从中文生殖 EMR 中自动识别早期卵巢老化的高风险并诊断相关疾病。我们希望该系统能够为生育中心的基于 EMR 的数据收集和临床决策支持提供帮助。