Zhang Tingting, Huang Zonghai, Wang Yaqiang, Wen Chuanbiao, Peng Yangzhi, Ye Ying
Chengdu University of Traditional Chinese Medicine, Chengdu, China.
Chengdu University of Information Technology, Chengdu, China.
Evid Based Complement Alternat Med. 2022 May 13;2022:1679589. doi: 10.1155/2022/1679589. eCollection 2022.
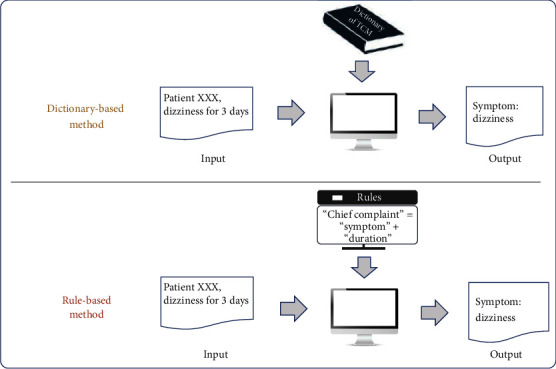
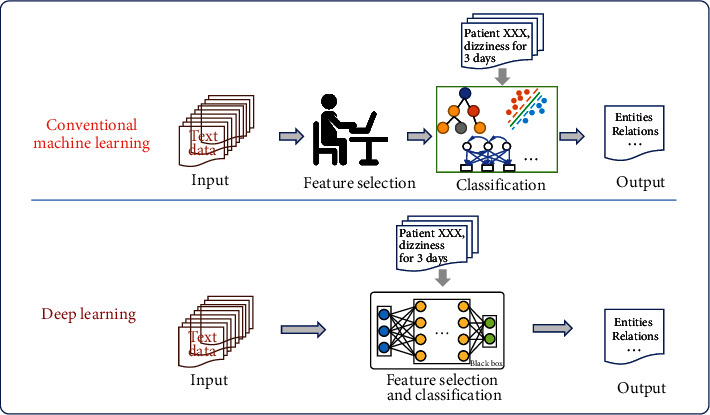
The practice of traditional Chinese medicine (TCM) began several thousand years ago, and the knowledge of practitioners is recorded in paper and electronic versions of case notes, manuscripts, and books in multiple languages. Developing a method of information extraction (IE) from these sources to generate a cohesive data set would be a great contribution to the medical field. The goal of this study was to perform a systematic review of the status of IE from TCM sources over the last 10 years.
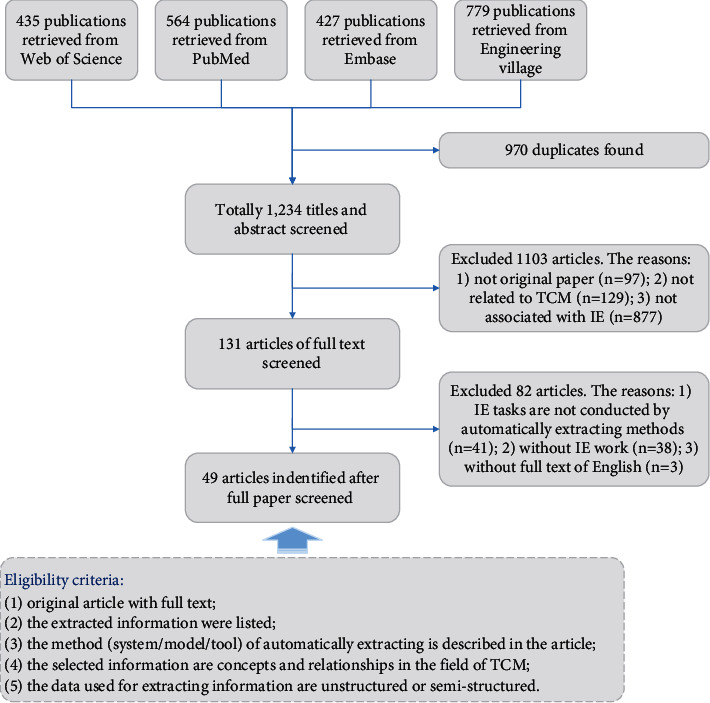
We conducted a search of four literature databases for articles published from 2010 to 2021 that focused on the use of natural language processing (NLP) methods to extract information from unstructured TCM text data. Two reviewers and one adjudicator contributed to article search, article selection, data extraction, and synthesis processes.
We retrieved 1234 records, 49 of which met our inclusion criteria. We used the articles to (i) assess the key tasks of IE in the TCM domain, (ii) summarize the challenges to extracting information from TCM text data, and (iii) identify effective frameworks, models, and key findings of TCM IE through classification.
Our analysis showed that IE from TCM text data has improved over the past decade. However, the extraction of TCM text still faces some challenges involving the lack of gold standard corpora, nonstandardized expressions, and multiple types of relations. In the future, IE work should be promoted by extracting more existing entities and relations, constructing gold standard data sets, and exploring IE methods based on a small amount of labeled data. Furthermore, fine-grained and interpretable IE technologies are necessary for further exploration.
中医实践始于数千年前,从业者的知识记录在纸质和电子版本的病例记录、手稿以及多种语言的书籍中。开发一种从这些来源提取信息(IE)以生成连贯数据集的方法将对医学领域做出巨大贡献。本研究的目的是对过去10年从中医来源进行信息提取的现状进行系统综述。
我们在四个文献数据库中搜索了2010年至2021年发表的文章,这些文章聚焦于使用自然语言处理(NLP)方法从非结构化中医文本数据中提取信息。两名评审员和一名裁决员参与了文章搜索、文章筛选、数据提取和综合过程。
我们检索到1234条记录,其中49条符合我们的纳入标准。我们利用这些文章来(i)评估中医领域信息提取的关键任务,(ii)总结从中医文本数据中提取信息的挑战,以及(iii)通过分类识别中医信息提取的有效框架、模型和关键发现。
我们的分析表明,过去十年中从中医文本数据进行的信息提取有所改进。然而,中医文本的提取仍面临一些挑战,包括缺乏金标准语料库、表达不规范以及多种关系类型。未来,应通过提取更多现有实体和关系、构建金标准数据集以及探索基于少量标注数据的信息提取方法来推动信息提取工作。此外,还需要细粒度且可解释的信息提取技术进行进一步探索。