Modern Management and Information Technology, College of Arts, Media and Technology, Chiang Mai University, Chiang Mai, 50200, Thailand.
Center for Research Innovation and Biomedical Informatics, Faculty of Medical Technology, Mahidol University, Bangkok, 10700, Thailand.
BMC Bioinformatics. 2023 Jul 28;24(1):301. doi: 10.1186/s12859-023-05421-x.
The identification of tumor T cell antigens (TTCAs) is crucial for providing insights into their functional mechanisms and utilizing their potential in anticancer vaccines development. In this context, TTCAs are highly promising. Meanwhile, experimental technologies for discovering and characterizing new TTCAs are expensive and time-consuming. Although many machine learning (ML)-based models have been proposed for identifying new TTCAs, there is still a need to develop a robust model that can achieve higher rates of accuracy and precision.
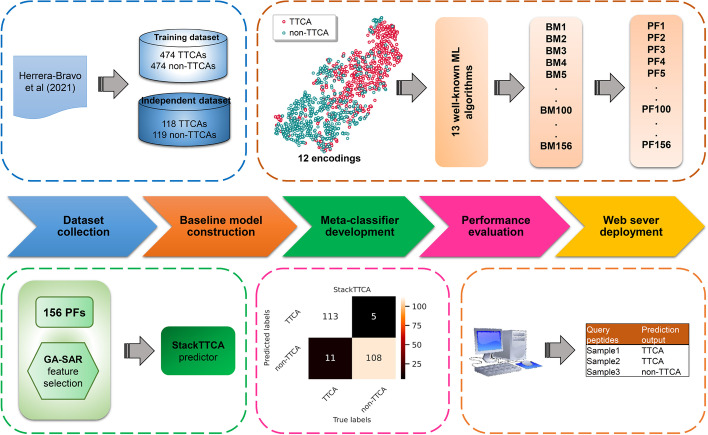
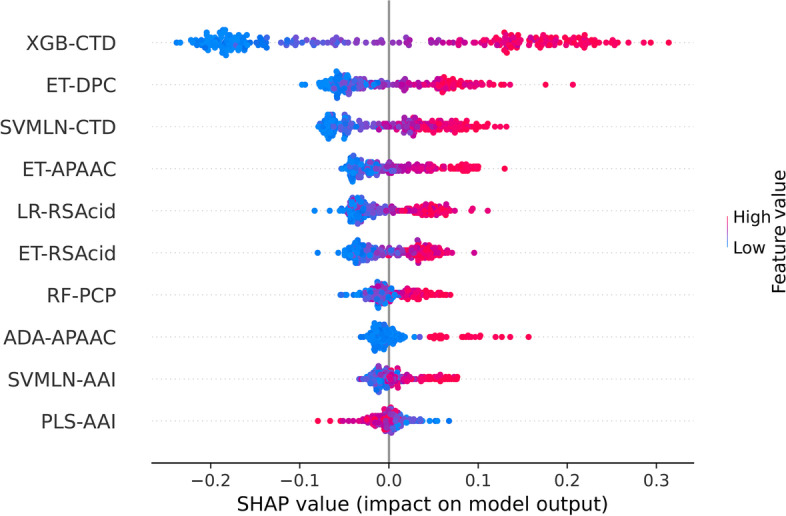
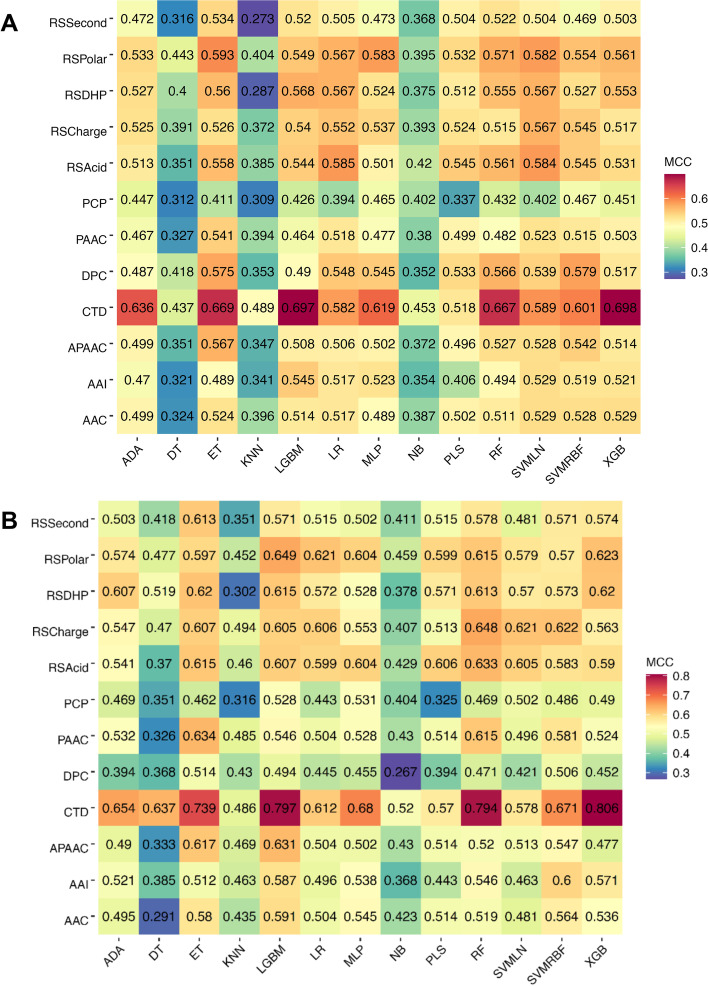
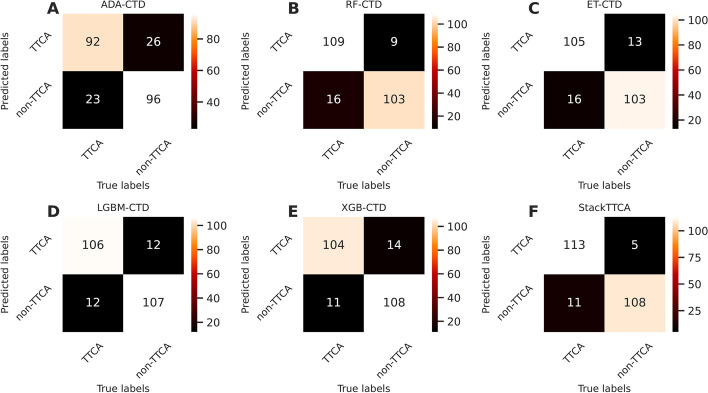
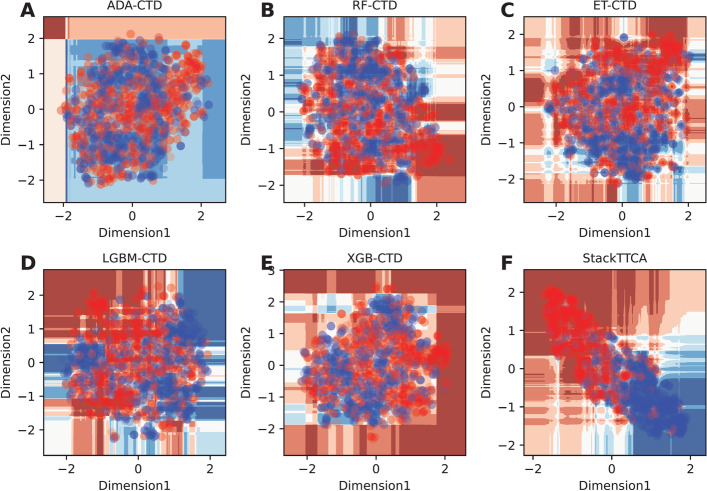
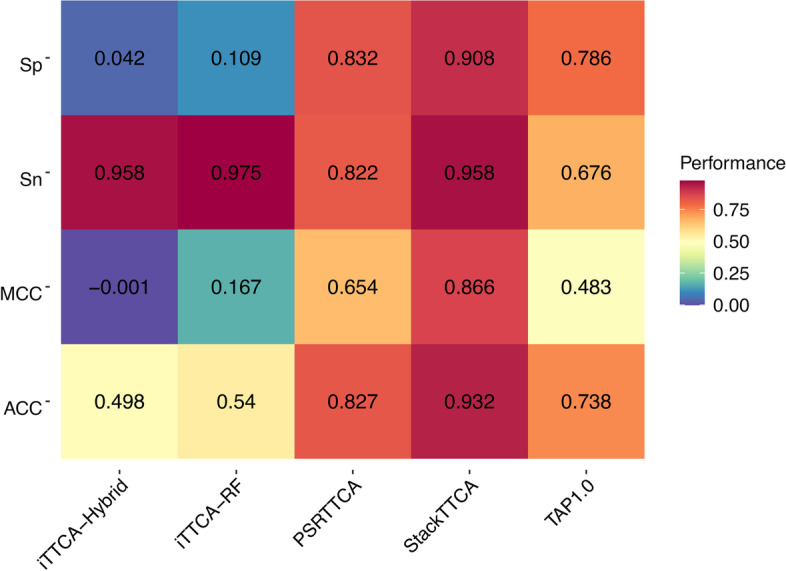
In this study, we propose a new stacking ensemble learning-based framework, termed StackTTCA, for accurate and large-scale identification of TTCAs. Firstly, we constructed 156 different baseline models by using 12 different feature encoding schemes and 13 popular ML algorithms. Secondly, these baseline models were trained and employed to create a new probabilistic feature vector. Finally, the optimal probabilistic feature vector was determined based the feature selection strategy and then used for the construction of our stacked model. Comparative benchmarking experiments indicated that StackTTCA clearly outperformed several ML classifiers and the existing methods in terms of the independent test, with an accuracy of 0.932 and Matthew's correlation coefficient of 0.866.
In summary, the proposed stacking ensemble learning-based framework of StackTTCA could help to precisely and rapidly identify true TTCAs for follow-up experimental verification. In addition, we developed an online web server ( http://2pmlab.camt.cmu.ac.th/StackTTCA ) to maximize user convenience for high-throughput screening of novel TTCAs.
鉴定肿瘤 T 细胞抗原(TTCAs)对于深入了解其功能机制以及利用其在抗癌疫苗开发中的潜力至关重要。在这种情况下,TTCAs 极具前景。同时,发现和表征新 TTCAs 的实验技术既昂贵又耗时。尽管已经提出了许多基于机器学习(ML)的模型来识别新的 TTCAs,但仍需要开发一个能够实现更高准确率和精度的稳健模型。
在这项研究中,我们提出了一种新的基于堆叠集成学习的框架,称为 StackTTCA,用于准确和大规模鉴定 TTCAs。首先,我们使用 12 种不同的特征编码方案和 13 种流行的 ML 算法构建了 156 种不同的基线模型。其次,对这些基线模型进行训练并用于创建新的概率特征向量。最后,根据特征选择策略确定最佳概率特征向量,并将其用于构建我们的堆叠模型。与几个 ML 分类器和现有方法的比较基准实验表明,StackTTCA 在独立测试中明显优于其他方法,准确率为 0.932,马修斯相关系数为 0.866。
总之,所提出的基于堆叠集成学习的 StackTTCA 框架可以帮助精确快速地识别真正的 TTCAs,以便进行后续的实验验证。此外,我们开发了一个在线网络服务器(http://2pmlab.camt.cmu.ac.th/StackTTCA),以最大限度地提高用户便利性,用于新型 TTCAs 的高通量筛选。