Yao Yongna
School of Information and Electronic Engineering, Shangqiu Institute of Technology, Shangqiu, China.
PeerJ Comput Sci. 2023 Jul 25;9:e1466. doi: 10.7717/peerj-cs.1466. eCollection 2023.
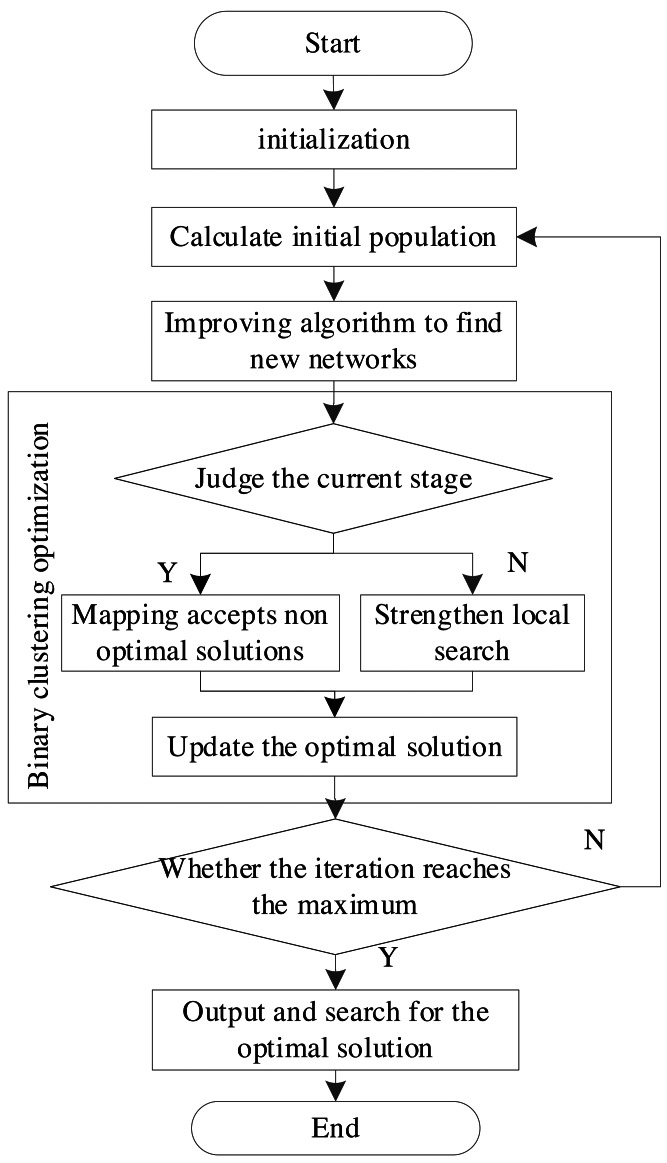
With the continuous development of new technologies, the scale of training data is also expanding. Machine learning algorithms are gradually beginning to be studied and applied in places where the scale of data is relatively large. Because the current structure of learning algorithms only focus on the identification of dependencies and ignores the direction of dependencies, it causes multiple labeled samples not to identify categories. Multiple labels need to be classified using techniques such as machine learning and then applied to solve the problem. In the environment of more training data, it is very meaningful to explore the structure extension to identify the dependencies between attributes and take into account the direction of dependencies. In this article, Bayesian network structure learning, analysis of the shortcomings of traditional algorithms, and binary evolutionary algorithm are applied to the randomized algorithm to generate the initial population. In the optimization process of the algorithm, it uses a Bayesian network to do a local search and uses a depth-first algorithm to break the loop. Finally, it finds a higher score for the network structure. In the simulation experiment, the classic data sets, ALARM and INSURANCE, are introduced to verify the effectiveness of the algorithm. Compared with NOTEARS and the Expectation-Maximization (EM) algorithm, the weight evaluation index of this article was 4.5% and 7.3% better than other schemes. The clustering effect was improved by 13.5% and 15.2%. The smallest error and the highest accuracy are also better than other schemes. The discussion of Bayesian reasoning in this article has very important theoretical and practical significance. This article further improves the Bayesian network structure and optimizes the performance of the classifier, which plays a very important role in promoting the expansion of the network structure and provides innovative thinking.
随着新技术的不断发展,训练数据的规模也在不断扩大。机器学习算法逐渐开始在数据规模相对较大的地方得到研究和应用。由于当前学习算法的结构仅专注于依赖关系的识别而忽略了依赖关系的方向,导致多个标记样本无法识别类别。需要使用机器学习等技术对多个标签进行分类,然后应用于解决该问题。在更多训练数据的环境下,探索结构扩展以识别属性之间的依赖关系并考虑依赖关系的方向具有非常重要的意义。在本文中,将贝叶斯网络结构学习、传统算法的缺点分析以及二进制进化算法应用于随机算法以生成初始种群。在算法的优化过程中,使用贝叶斯网络进行局部搜索,并使用深度优先算法打破循环。最后,为网络结构找到了更高的分数。在仿真实验中,引入了经典数据集ALARM和INSURANCE来验证算法的有效性。与NOTEARS和期望最大化(EM)算法相比,本文的权重评估指标分别比其他方案高4.5%和7.3%。聚类效果提高了13.5%和15.2%。最小误差和最高准确率也优于其他方案。本文对贝叶斯推理的讨论具有非常重要的理论和实践意义。本文进一步改进了贝叶斯网络结构,优化了分类器的性能,对推动网络结构的扩展起到了非常重要的作用,并提供了创新思路。