Division of Hand, Plastic and Aesthetic Surgery, Ludwig-Maximilians University Munich, Ziemssenstrasse 5, 80336, Munich, Germany.
Department of Otolaryngology, Head and Neck Surgery, School of Medicine, Technical University of Munich (TUM), Ismaningerstrasse 22, 81675, Munich, Germany.
Ann Biomed Eng. 2024 Jun;52(6):1542-1545. doi: 10.1007/s10439-023-03338-3. Epub 2023 Aug 8.
The use of AI-powered technology, particularly OpenAI's ChatGPT, holds significant potential to reshape healthcare and medical education. Despite existing studies on the performance of ChatGPT in medical licensing examinations across different nations, a comprehensive, multinational analysis using rigorous methodology is currently lacking. Our study sought to address this gap by evaluating the performance of ChatGPT on six different national medical licensing exams and investigating the relationship between test question length and ChatGPT's accuracy.
We manually inputted a total of 1,800 test questions (300 each from US, Italian, French, Spanish, UK, and Indian medical licensing examination) into ChatGPT, and recorded the accuracy of its responses.
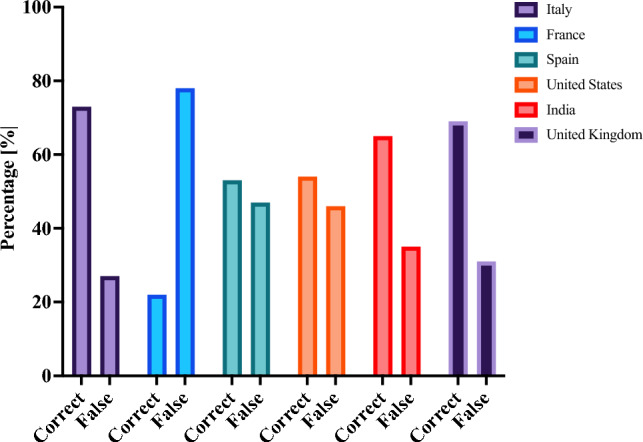
We found significant variance in ChatGPT's test accuracy across different countries, with the highest accuracy seen in the Italian examination (73% correct answers) and the lowest in the French examination (22% correct answers). Interestingly, question length correlated with ChatGPT's performance in the Italian and French state examinations only. In addition, the study revealed that questions requiring multiple correct answers, as seen in the French examination, posed a greater challenge to ChatGPT.
Our findings underscore the need for future research to further delineate ChatGPT's strengths and limitations in medical test-taking across additional countries and to develop guidelines to prevent AI-assisted cheating in medical examinations.
人工智能技术的应用,特别是 OpenAI 的 ChatGPT,具有重塑医疗保健和医学教育的巨大潜力。尽管已经有研究探讨了 ChatGPT 在不同国家的医学执照考试中的表现,但目前缺乏全面、多国家的分析,且使用严格的方法。我们的研究旨在通过评估 ChatGPT 在六项不同国家的医学执照考试中的表现,并调查测试问题长度与 ChatGPT 的准确性之间的关系,来填补这一空白。
我们手动将总共 1800 个测试问题(每个国家 300 个,包括美国、意大利、法国、西班牙、英国和印度的医学执照考试)输入 ChatGPT,并记录其回答的准确性。
我们发现 ChatGPT 在不同国家的考试准确性存在显著差异,意大利考试的准确性最高(73%的正确答案),法国考试的准确性最低(22%的正确答案)。有趣的是,问题长度仅与意大利和法国国家考试中的 ChatGPT 表现相关。此外,该研究表明,需要多个正确答案的问题,如法国考试中的问题,对 ChatGPT 构成了更大的挑战。
我们的发现强调了未来研究的必要性,以进一步阐明 ChatGPT 在其他国家的医学考试中的优势和局限性,并制定防止医学考试中人工智能辅助作弊的指南。