Venkataramanan Revathy, Padhee Swati, Rao Saini Rohan, Kaoshik Ronak, Sundara Rajan Anirudh, Sheth Amit
Department of Computer Science, Artificial Intelligence Research Institute, University of South Carolina, Columbia, SC, United States.
Department of Computer Science, Wright State University, Dayton, OH, United States.
Front Big Data. 2023 Jul 24;6:1200840. doi: 10.3389/fdata.2023.1200840. eCollection 2023.
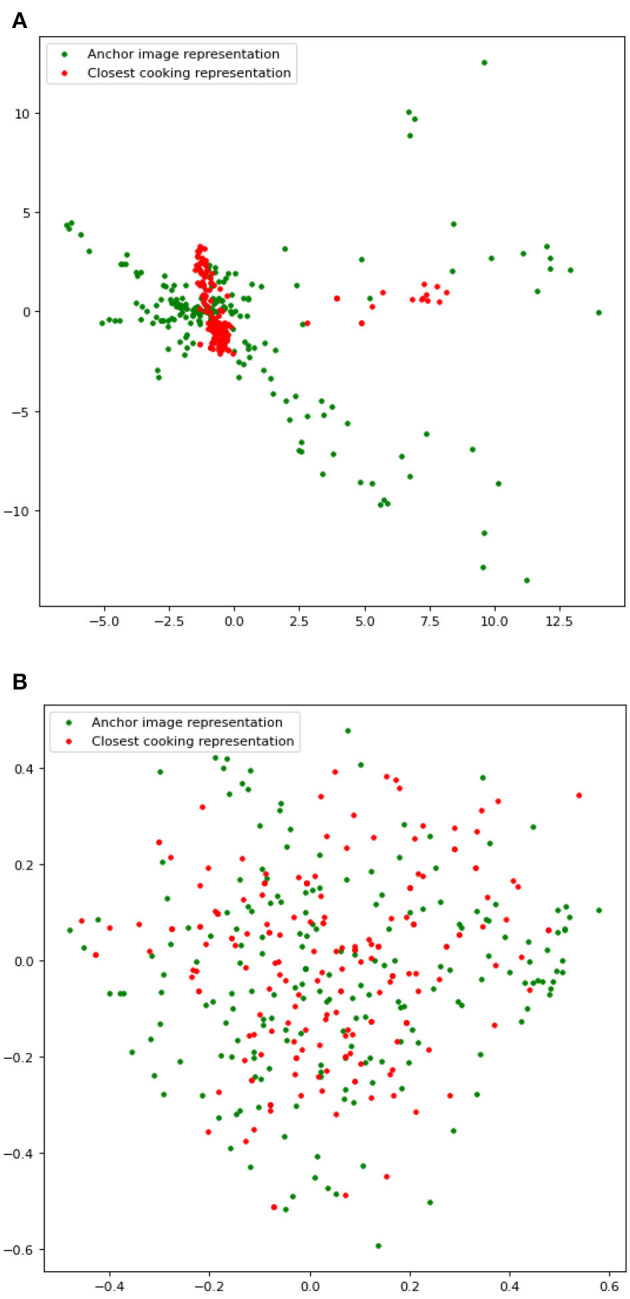
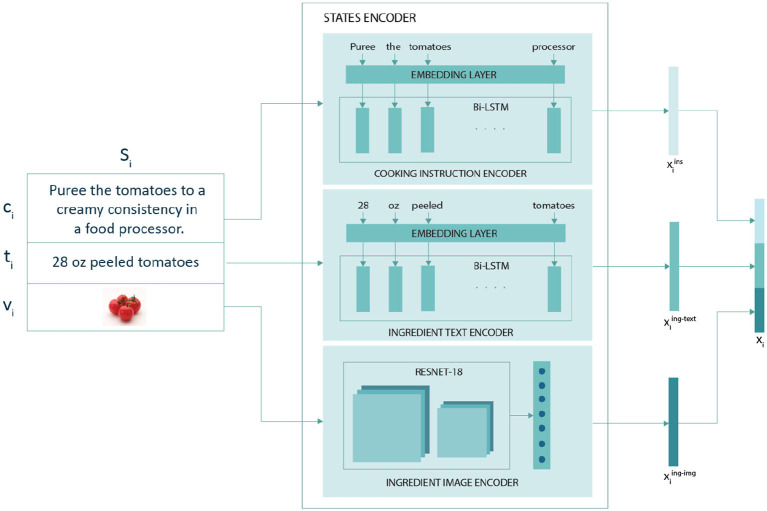
Cross-modal recipe retrieval has gained prominence due to its ability to retrieve a text representation given an image representation and vice versa. Clustering these recipe representations based on similarity is essential to retrieve relevant information about unknown food images. Existing studies cluster similar recipe representations in the latent space based on class names. Due to inter-class similarity and intraclass variation, associating a recipe with a class name does not provide sufficient knowledge about recipes to determine similarity. However, recipe title, ingredients, and cooking actions provide detailed knowledge about recipes and are a better determinant of similar recipes. In this study, we utilized this additional knowledge of recipes, such as ingredients and recipe title, to identify similar recipes, emphasizing attention especially on rare ingredients. To incorporate this knowledge, we propose a knowledge-infused multimodal cooking representation learning network, Ki-Cook, built on the procedural attribute of the cooking process. To the best of our knowledge, this is the first study to adopt a comprehensive recipe similarity determinant to identify and cluster similar recipe representations. The proposed network also incorporates ingredient images to learn multimodal cooking representation. Since the motivation for clustering similar recipes is to retrieve relevant information for an unknown food image, we evaluated the ingredient retrieval task. We performed an empirical analysis to establish that our proposed model improves the Coverage of Ground Truth by 12% and the Intersection Over Union by 10% compared to the baseline models. On average, the representations learned by our model contain an additional 15.33% of rare ingredients compared to the baseline models. Owing to this difference, our qualitative evaluation shows a 39% improvement in clustering similar recipes in the latent space compared to the baseline models, with an inter-annotator agreement of the Fleiss kappa score of 0.35.
跨模态食谱检索因其能够根据图像表示检索文本表示,反之亦然,而备受关注。基于相似性对这些食谱表示进行聚类对于检索未知食物图像的相关信息至关重要。现有研究基于类名在潜在空间中对相似的食谱表示进行聚类。由于类间相似性和类内变化,将食谱与类名关联并不能提供足够的食谱知识来确定相似性。然而,食谱标题、食材和烹饪步骤提供了关于食谱的详细知识,是相似食谱更好的决定因素。在本研究中,我们利用食谱的这些额外知识,如食材和食谱标题,来识别相似的食谱,特别关注稀有食材。为了纳入这些知识,我们提出了一种基于烹饪过程的过程属性构建的知识注入多模态烹饪表示学习网络Ki-Cook。据我们所知,这是第一项采用全面的食谱相似性决定因素来识别和聚类相似食谱表示的研究。所提出的网络还纳入了食材图像来学习多模态烹饪表示。由于聚类相似食谱的动机是为未知食物图像检索相关信息,我们评估了食材检索任务。我们进行了实证分析,以确定与基线模型相比,我们提出的模型将真实覆盖范围提高了12%,交并比提高了10%。平均而言,与基线模型相比,我们模型学习到的表示中稀有食材多了15.33%。由于这种差异,我们的定性评估表明,与基线模型相比,在潜在空间中聚类相似食谱的性能提高了39%,注释者间一致性的Fleiss kappa评分为0.35。