Carolina Garcia-Vidal, MD, PhD. Infectious Diseases Department, Hospital Clínic-IDIBAPS, Carrer de Villarroel 170, 08036, Barcelona, Spain.
Rev Esp Quimioter. 2023 Dec;36(6):592-596. doi: 10.37201/req/032.2023. Epub 2023 Aug 12.
Clinical data on which artificial intelligence (AI) algorithms are trained and tested provide the basis to improve diagnosis or treatment of infectious diseases (ID). We aimed to identify important data for ID research to prioritise efforts being undertaken in AI programmes.
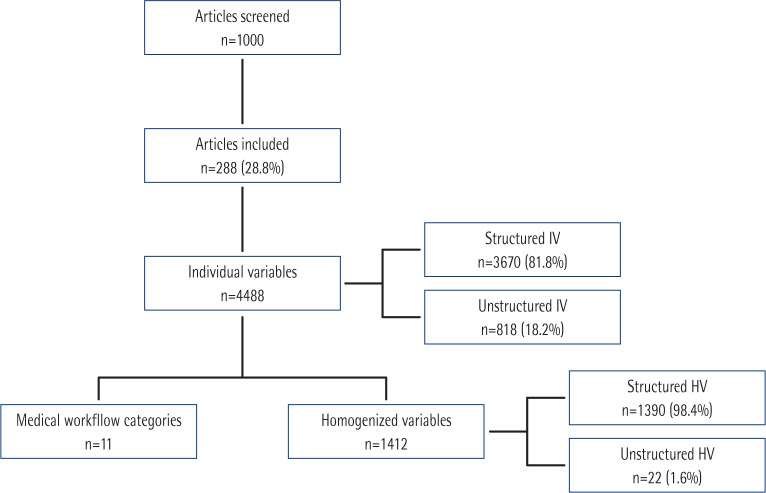
We searched for 1,000 articlesfrom high-impact ID journals on PubMed, selecting 288 of the latest articles from 10 top journals. We classified them into structured or unstructured data. Variables were homogenised and grouped into the following categories: epidemiology, admission, demographics, comorbidities, clinical manifestations, laboratory, microbiology, other diagnoses, treatment, outcomes and other non-categorizable variables.
4,488 individual variables were collected, from the 288 articles. 3,670 (81.8%) variables were classified as structured data whilst 818 (18.2%) as unstructured data. From the structured data, 2,319 (63.2%) variables were classified as direct-retrievable from electronic health records-whilst 1,351 (36.8%) were indirect. The most frequent unstructured data were related to clinical manifestations and were repeated across articles. Data on demographics, comorbidities and microbiology constituted the most frequent group of variables.
This article identified that structured variables have comprised the most important data in research to generate knowledge in the field of ID. Extracting these data should be a priority when a medical centre intends to start an AI programme for ID. We also documented that the most important unstructured data in this field are those related to clinical manifestations. Such data could easily undergo some structuring with the use of semi-structured medical records focusing on a few symptoms.
人工智能 (AI) 算法所训练和测试的临床数据为改善传染病 (ID) 的诊断或治疗提供了依据。我们旨在确定 ID 研究的重要数据,以优先考虑 AI 计划中正在进行的工作。
我们在 PubMed 上搜索了 1000 篇高影响力的 ID 期刊文章,从 10 种顶级期刊中选择了最新的 288 篇文章。我们将它们分为结构化或非结构化数据。变量进行了同质化处理,并分为以下几类:流行病学、入院、人口统计学、合并症、临床表现、实验室、微生物学、其他诊断、治疗、结局和其他不可分类变量。
从 288 篇文章中收集了 4488 个个体变量。288 篇文章中有 3670 个(81.8%)变量被归类为结构化数据,818 个(18.2%)为非结构化数据。从结构化数据中,2319 个(63.2%)变量被归类为可直接从电子健康记录中检索,而 1351 个(36.8%)为间接变量。最常见的非结构化数据与临床表现有关,并在文章中重复出现。人口统计学、合并症和微生物学数据构成了变量中最常见的组。
本文确定了结构化变量构成了 ID 领域产生知识的研究中最重要的数据。当医疗中心打算为 ID 启动 AI 计划时,提取这些数据应是优先事项。我们还记录了该领域最重要的非结构化数据是与临床表现相关的数据。这些数据可以通过使用半结构化医疗记录聚焦于少数症状来轻松进行一些结构化处理。