Oncology Data Science, Merck Healthcare KGaA, Darmstadt, Germany.
Faculty of Biosciences, Heidelberg University, Heidelberg, Germany.
Front Immunol. 2023 Aug 4;14:1194745. doi: 10.3389/fimmu.2023.1194745. eCollection 2023.
Robust immune cell gene expression signatures are central to the analysis of single cell studies. Nearly all known sets of immune cell signatures have been derived by making use of only single gene expression datasets. Utilizing the power of multiple integrated datasets could lead to high-quality immune cell signatures which could be used as superior inputs to machine learning-based cell type classification approaches.
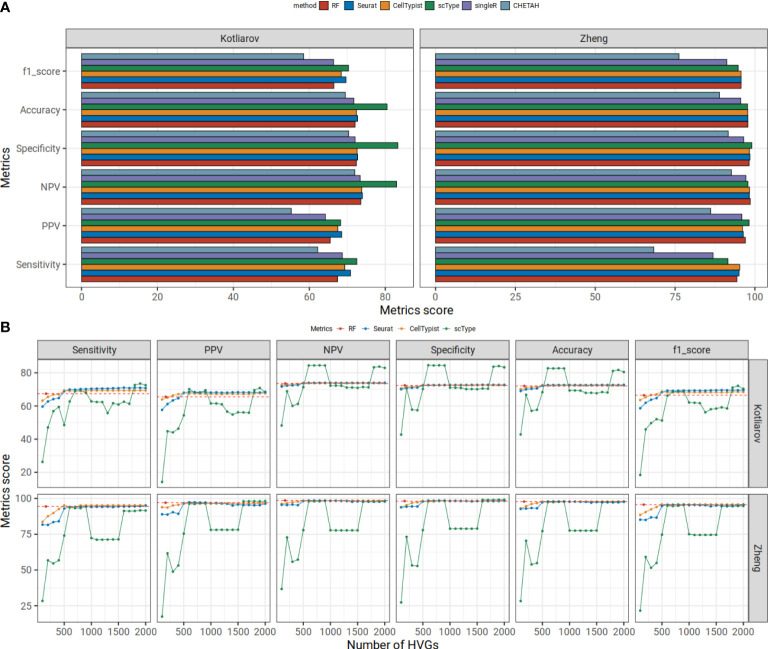
We established a novel workflow for the discovery of immune cell type signatures based primarily on gene-versus-gene expression similarity. It leverages multiple datasets, here seven single cell expression datasets from six different cancer types and resulted in eleven immune cell type-specific gene expression signatures. We used these to train random forest classifiers for immune cell type assignment for single-cell RNA-seq datasets. We obtained similar or better prediction results compared to commonly used methods for cell type assignment in independent benchmarking datasets. Our gene signature set yields higher prediction scores than other published immune cell type gene sets in random forest-based cell type classification. We further demonstrate how our approach helps to avoid bias in downstream statistical analyses by re-analysis of a published IFN stimulation experiment.
We demonstrated the quality of our immune cell signatures and their strong performance in a random forest-based cell typing approach. We argue that classifying cells based on our comparably slim sets of genes accompanied by a random forest-based approach not only matches or outperforms widely used published approaches. It also facilitates unbiased downstream statistical analyses of differential gene expression between cell types for significantly more genes compared to previous cell classification algorithms.
强大的免疫细胞基因表达特征是单细胞研究分析的核心。几乎所有已知的免疫细胞特征集都是通过仅利用单个基因表达数据集推导出来的。利用多个集成数据集的力量可以产生高质量的免疫细胞特征集,这些特征集可以作为基于机器学习的细胞类型分类方法的更好输入。
我们建立了一种基于基因-基因表达相似性的新型免疫细胞类型特征发现工作流程。它利用了多个数据集,这里有来自六种不同癌症类型的七个单细胞表达数据集,最终得到了十一个免疫细胞类型特异性基因表达特征。我们使用这些特征来训练随机森林分类器,用于单细胞 RNA-seq 数据集的免疫细胞类型分配。与在独立基准数据集上用于细胞类型分配的常用方法相比,我们获得了相似或更好的预测结果。与其他已发表的免疫细胞类型基因集相比,我们的基因特征集在基于随机森林的细胞类型分类中产生了更高的预测分数。我们进一步通过重新分析已发表的 IFN 刺激实验,证明了我们的方法如何有助于避免下游统计分析中的偏差。
我们证明了我们的免疫细胞特征的质量及其在基于随机森林的细胞分型方法中的出色表现。我们认为,基于我们相对较少的基因集和基于随机森林的方法对细胞进行分类,不仅与广泛使用的已发表方法相匹配或优于这些方法,而且还促进了更具统计学意义的细胞类型之间差异基因表达的下游无偏统计分析,相比以前的细胞分类算法,可分析的基因数量显著增加。