Bhavnani Suresh K, Zhang Weibin, Bao Daniel, Raji Mukaila, Ajewole Veronica, Hunter Rodney, Kuo Yong-Fang, Schmidt Susanne, Pappadis Monique R, Smith Elise, Bokov Alex, Reistetter Timothy, Visweswaran Shyam, Downer Brian
School of Public and Population Health, University of Texas Medical Branch, Galveston, TX, USA.
Institute for Translational Sciences, University of Texas Medical Branch, Galveston, TX, USA.
medRxiv. 2023 Aug 11:2023.01.27.23285125. doi: 10.1101/2023.01.27.23285125.
Social determinants of health (SDoH), such as financial resources and housing stability, account for between 30-55% of people's health outcomes. While many studies have identified strong associations among specific SDoH and health outcomes, most people experience multiple SDoH that impact their daily lives. Analysis of this complexity requires the integration of personal, clinical, social, and environmental information from a large cohort of individuals that have been traditionally underrepresented in research, which is only recently being made available through the research program. However, little is known about the range and response of SDoH in , and how they co-occur to form subtypes, which are critical for designing targeted interventions.
To address two research questions: (1) What is the range and response to survey questions related to SDoH in the dataset? (2) How do SDoH co-occur to form subtypes, and what are their risk for adverse health outcomes?
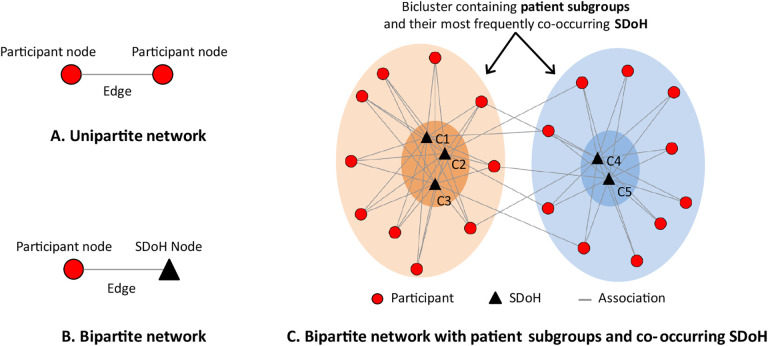
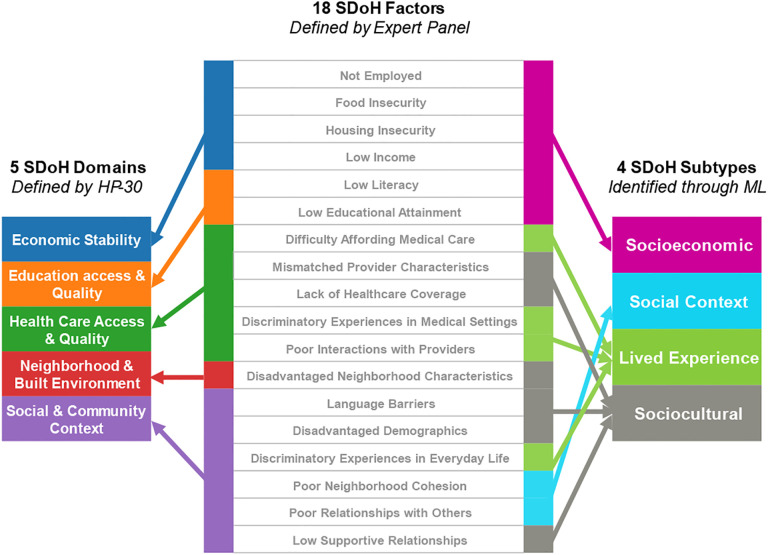
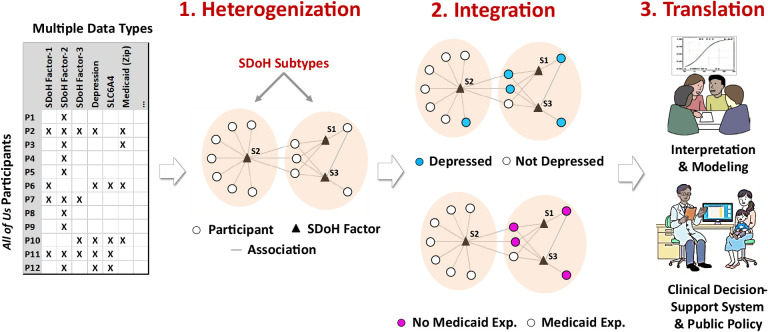
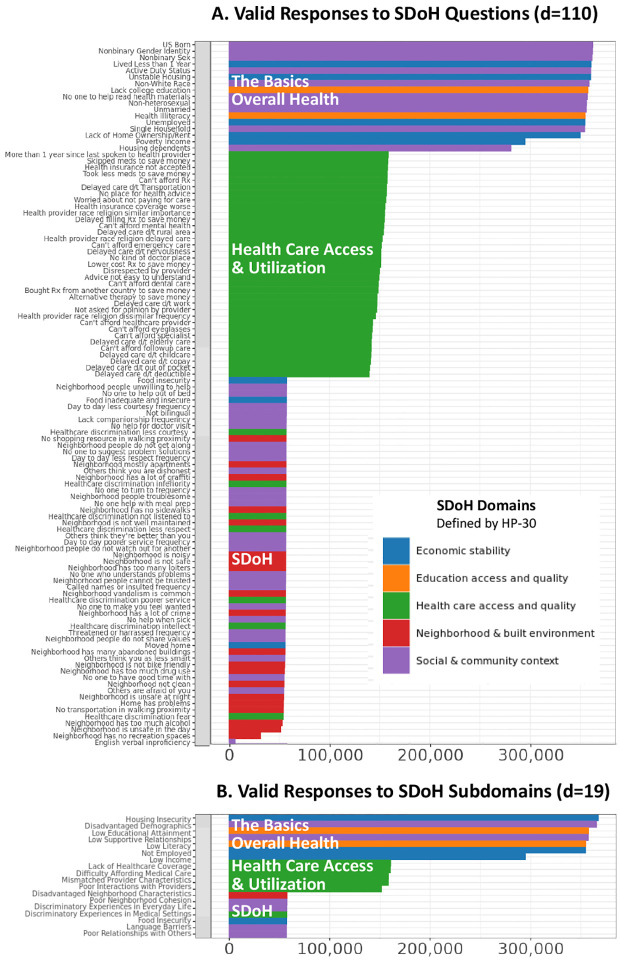
For Question-1, an expert panel analyzed the range of SDoH questions across the surveys with respect to the 5 domains in (, and analyzed their responses across the full data (n=372,397, V6). For Question-2, we used the following steps: (1) due to the missingness across the surveys, selected all participants with valid and complete SDoH data, and used inverse probability weighting to adjust their imbalance in demographics compared to the full data; (2) an expert panel grouped the SDoH questions into SDoH factors for enabling a more consistent granularity; (3) used bipartite modularity maximization to identify SDoH biclusters, their significance, and their replicability; (4) measured the association of each bicluster to three outcomes (depression, delayed medical care, emergency room visits in the last year) using multiple data types (surveys, electronic health records, and zip codes mapped to Medicaid expansion states); and (5) the expert panel inferred the subtype labels, potential mechanisms that precipitate adverse health outcomes, and interventions to prevent them.
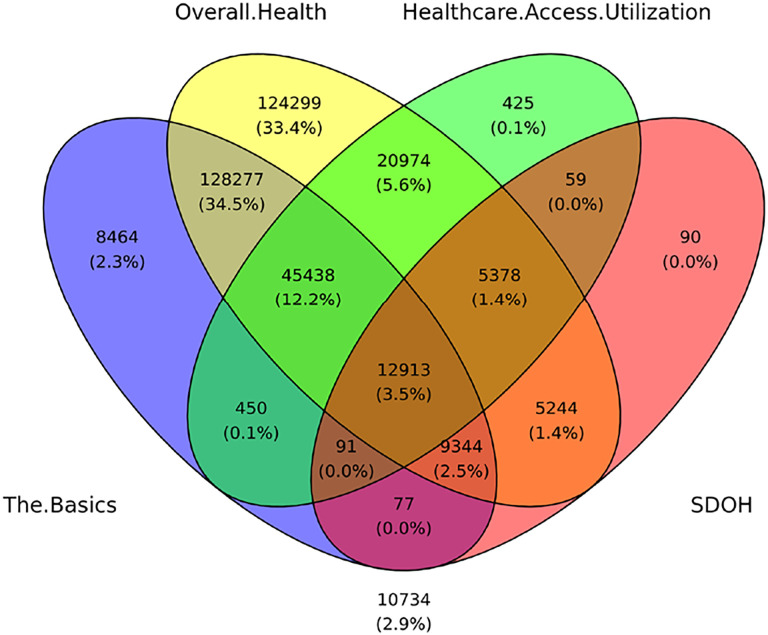
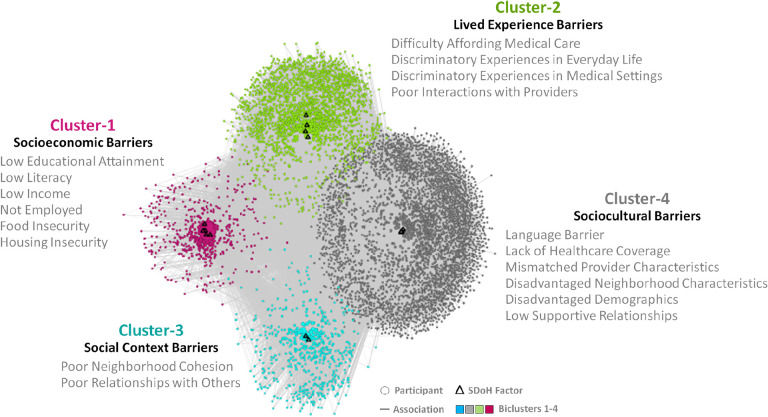
For Question-1, we identified 110 SDoH questions across 4 surveys, which covered all 5 domains in . However, the results also revealed a large degree of missingness in survey responses (1.76%-84.56%), with later surveys having significantly fewer responses compared to earlier ones, and significant differences in race, ethnicity, and age of participants of those that completed the surveys with SDoH questions, compared to those in the full dataset. Furthermore, as the SDoH questions varied in granularity, they were categorized by an expert panel into 18 SDoH factors. For Question-2, the subtype analysis (n=12,913, d=18) identified 4 biclusters with significant biclusteredness (Q=0.13, random-Q=0.11, z=7.5, <0.001), and significant replication (Real-RI=0.88, Random-RI=0.62, <.001). Furthermore, there were statistically significant associations between specific subtypes and the outcomes, and with Medicaid expansion, each with meaningful interpretations and potential targeted interventions. For example, the subtype included the SDoH factors , and , and had a significantly higher odds ratio (OR=4.2, CI=3.5-5.1, -corr<.001) for depression, when compared to the subtype . Individuals that match this subtype profile could be screened early for depression and referred to social services for addressing combinations of SDoH such as and . Finally, the identified subtypes spanned one or more domains revealing the difference between the current knowledge-based SDoH domains, and the data-driven subtypes.
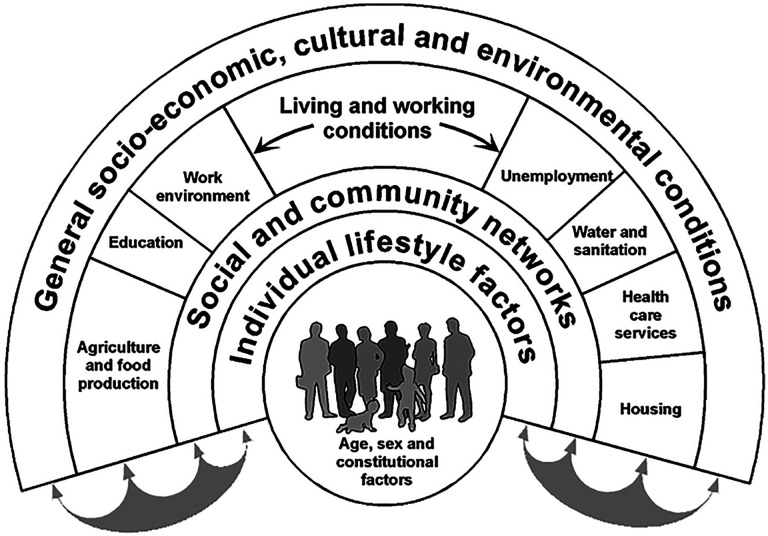
The results revealed that the SDoH subtypes not only had statistically significant clustering and replicability, but also had significant associations with critical adverse health outcomes, which had translational implications for designing targeted SDoH interventions, decision-support systems to alert clinicians of potential risks, and for public policies. Furthermore, these SDoH subtypes spanned multiple SDoH domains defined by revealing the complexity of SDoH in the real-world, and aligning with influential SDoH conceptual models such as by Dahlgren-Whitehead. However, the high-degree of missingness warrants repeating the analysis as the data becomes more complete. Consequently we designed our machine learning code to be generalizable and scalable, and made it available on the workbench, which can be used to periodically rerun the analysis as the dataset grows for analyzing subtypes related to SDoH, and beyond.
健康的社会决定因素(SDoH),如财务资源和住房稳定性,在人们的健康结果中占比30%-55%。虽然许多研究已经确定了特定的SDoH与健康结果之间的紧密关联,但大多数人会经历多种影响其日常生活的SDoH。对这种复杂性进行分析需要整合来自大量个体的个人、临床、社会和环境信息,而这些个体在传统研究中代表性不足,直到最近通过研究项目才得以获取相关数据。然而,关于SDoH在[具体地区]的范围和反应,以及它们如何共同出现形成亚型,我们知之甚少,而这些对于设计有针对性的干预措施至关重要。
解决两个研究问题:(1)在[具体地区]数据集中,与SDoH相关的调查问题的范围和反应是什么?(2)SDoH如何共同出现形成亚型,以及它们出现不良健康结果的风险是什么?
对于问题1,一个专家小组分析了各项调查中SDoH问题在[具体地区]的5个领域([领域名称])的范围,并分析了所有[具体地区]数据(n = 372,397,版本6)中的回答。对于问题2,我们采用了以下步骤:(1)由于各项调查中存在数据缺失,我们选择了所有拥有有效且完整的SDoH数据的参与者,并使用逆概率加权来调整他们与完整数据相比在人口统计学上的不平衡;(2)一个专家小组将SDoH问题分组为SDoH因素,以实现更一致的粒度;(3)使用二分模块最大化来识别SDoH双聚类、它们的显著性和可重复性;(4)使用多种数据类型(调查、电子健康记录以及映射到医疗补助扩展州的邮政编码)测量每个双聚类与三个结果(抑郁、延迟医疗护理、去年的急诊就诊)之间的关联;(5)专家小组推断亚型标签、促成不良健康结果的潜在机制以及预防这些结果的干预措施。
对于问题1,我们在4项调查中识别出110个SDoH问题,这些问题涵盖了[具体地区]的所有5个领域。然而,结果还显示调查回答中存在大量缺失(1.76%-84.56%),后期调查的回答明显少于早期调查,并且完成SDoH问题调查的参与者在种族、民族和年龄方面与完整[具体地区]数据集的参与者存在显著差异。此外,由于SDoH问题在粒度上有所不同,专家小组将它们分类为18个SDoH因素。对于问题2,亚型分析(n = 12,913,维度 = 18)识别出4个具有显著双聚类性的双聚类(Q = 0.13,随机Q = 0.11,z = 7.5,p < 0.001),并且具有显著的可重复性(实际RI = 0.88,随机RI = 0.62,p <.001)。此外,特定亚型与结果之间以及与医疗补助扩展之间存在统计学上的显著关联,每种关联都有有意义的解释和潜在的针对性干预措施。例如,亚型[亚型名称]包括SDoH因素[因素名称1]、[因素名称2]和[因素名称3],与亚型[另一亚型名称]相比,患抑郁症的优势比显著更高(OR = 4.2,CI = 3.5 - 5.1,校正p <.001)。符合此亚型特征的个体可以早期筛查抑郁症,并转介到社会服务部门,以解决诸如[因素名称1]和[因素名称2]等SDoH的组合问题。最后,识别出的亚型跨越一个或多个[具体地区]领域,揭示了当前基于知识的SDoH领域与数据驱动的亚型之间的差异。
结果表明,SDoH亚型不仅具有统计学上的显著聚类性和可重复性,而且与关键的不良健康结果存在显著关联,这对于设计有针对性的SDoH干预措施、提醒临床医生潜在风险的决策支持系统以及公共政策具有转化意义。此外,这些SDoH亚型跨越了由[具体地区]定义的多个SDoH领域,揭示了现实世界中SDoH的复杂性,并与诸如达尔格伦 - 怀特黑德等有影响力的SDoH概念模型相一致。然而,高度的缺失性使得有必要在数据变得更完整时重复进行分析。因此,我们设计的机器学习代码具有通用性和可扩展性,并在[具体工作平台]上提供,随着数据集的增长,可用于定期重新运行分析,以分析与SDoH相关的亚型及其他内容。