Wang Yitian, Xiong Jiacheng, Xiao Fu, Zhang Wei, Cheng Kaiyang, Rao Jingxin, Niu Buying, Tong Xiaochu, Qu Ning, Zhang Runze, Wang Dingyan, Chen Kaixian, Li Xutong, Zheng Mingyue
Drug Discovery and Design Center, State Key Laboratory of Drug Research, Shanghai Institute of Materia Medica, Chinese Academy of Sciences, 555 Zuchongzhi Road, Shanghai, 201203, China.
University of Chinese Academy of Sciences, No. 19A Yuquan Road, Beijing, 100049, China.
J Cheminform. 2023 Sep 5;15(1):76. doi: 10.1186/s13321-023-00754-4.
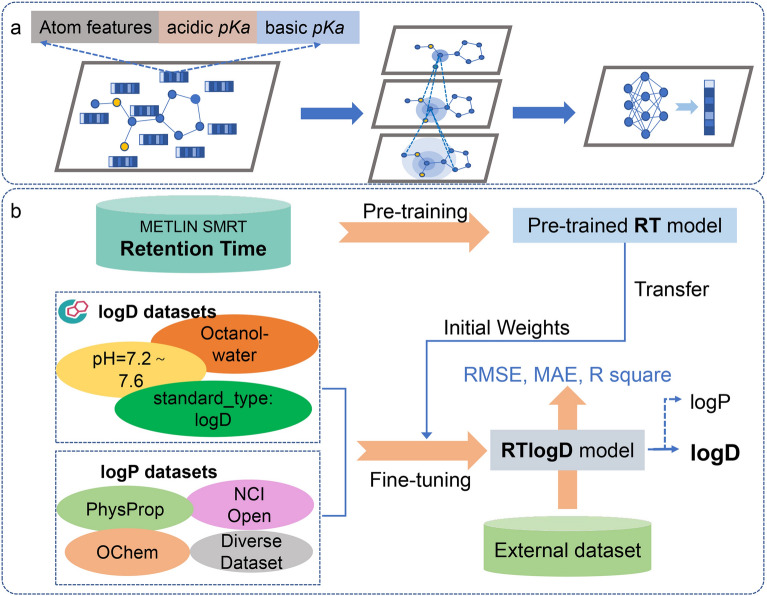
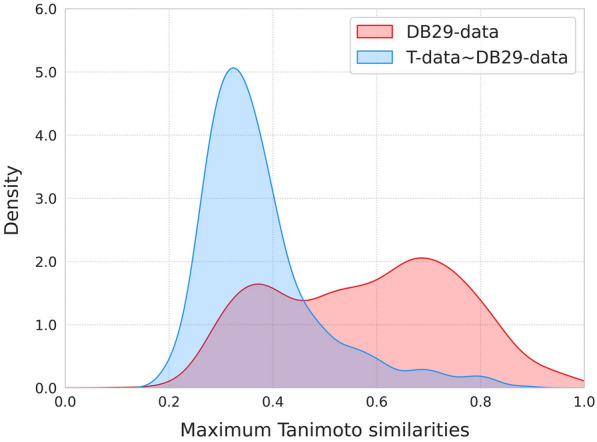
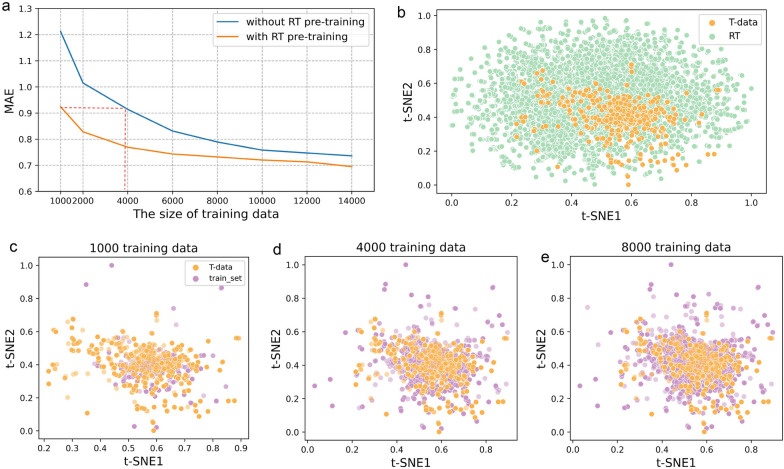
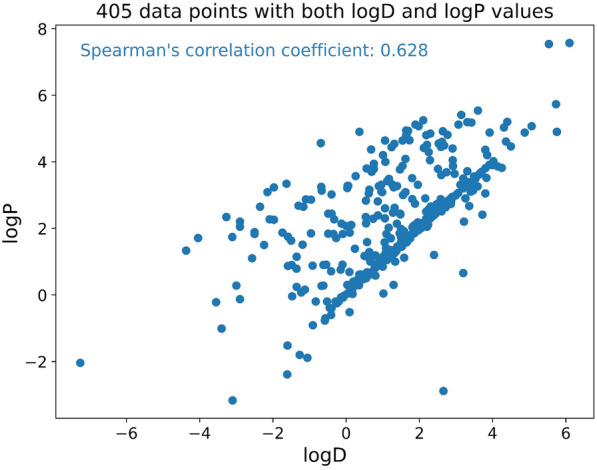
Lipophilicity is a fundamental physical property that significantly affects various aspects of drug behavior, including solubility, permeability, metabolism, distribution, protein binding, and toxicity. Accurate prediction of lipophilicity, measured by the logD7.4 value (the distribution coefficient between n-octanol and buffer at physiological pH 7.4), is crucial for successful drug discovery and design. However, the limited availability of data for logD modeling poses a significant challenge to achieving satisfactory generalization capability. To address this challenge, we have developed a novel logD7.4 prediction model called RTlogD, which leverages knowledge from multiple sources. RTlogD combines pre-training on a chromatographic retention time (RT) dataset since the RT is influenced by lipophilicity. Additionally, microscopic pKa values are incorporated as atomic features, providing valuable insights into ionizable sites and ionization capacity. Furthermore, logP is integrated as an auxiliary task within a multitask learning framework. We conducted ablation studies and presented a detailed analysis, showcasing the effectiveness and interpretability of RT, pKa, and logP in the RTlogD model. Notably, our RTlogD model demonstrated superior performance compared to commonly used algorithms and prediction tools. These results underscore the potential of the RTlogD model to improve the accuracy and generalization of logD prediction in drug discovery and design. In summary, the RTlogD model addresses the challenge of limited data availability in logD modeling by leveraging knowledge from RT, microscopic pKa, and logP. Incorporating these factors enhances the predictive capabilities of our model, and it holds promise for real-world applications in drug discovery and design scenarios.
亲脂性是一种基本物理性质,对药物行为的各个方面都有显著影响,包括溶解度、渗透性、代谢、分布、蛋白质结合和毒性。通过logD7.4值(正辛醇与生理pH值7.4的缓冲液之间的分配系数)来衡量,准确预测亲脂性对于成功的药物发现和设计至关重要。然而,用于logD建模的数据有限,这对实现令人满意的泛化能力构成了重大挑战。为应对这一挑战,我们开发了一种名为RTlogD的新型logD7.4预测模型,该模型利用了来自多个来源的知识。RTlogD结合了对色谱保留时间(RT)数据集的预训练,因为RT受亲脂性影响。此外,微观pKa值作为原子特征被纳入,为可电离位点和电离能力提供了有价值的见解。此外,logP被整合为多任务学习框架中的一项辅助任务。我们进行了消融研究并给出了详细分析,展示了RT、pKa和logP在RTlogD模型中的有效性和可解释性。值得注意的是,我们的RTlogD模型与常用算法和预测工具相比表现出卓越的性能。这些结果强调了RTlogD模型在提高药物发现和设计中logD预测的准确性和泛化能力方面的潜力。总之,RTlogD模型通过利用来自RT、微观pKa和logP的知识,解决了logD建模中数据可用性有限的挑战。纳入这些因素增强了我们模型的预测能力,并且它在药物发现和设计场景的实际应用中具有前景。