Biologic Therapeutic Discovery, Amgen Research, Thousand Oaks, CA, USA.
Process Development, Amgen Operations, Thousand Oaks, CA, USA.
MAbs. 2023 Jan-Dec;15(1):2256745. doi: 10.1080/19420862.2023.2256745.
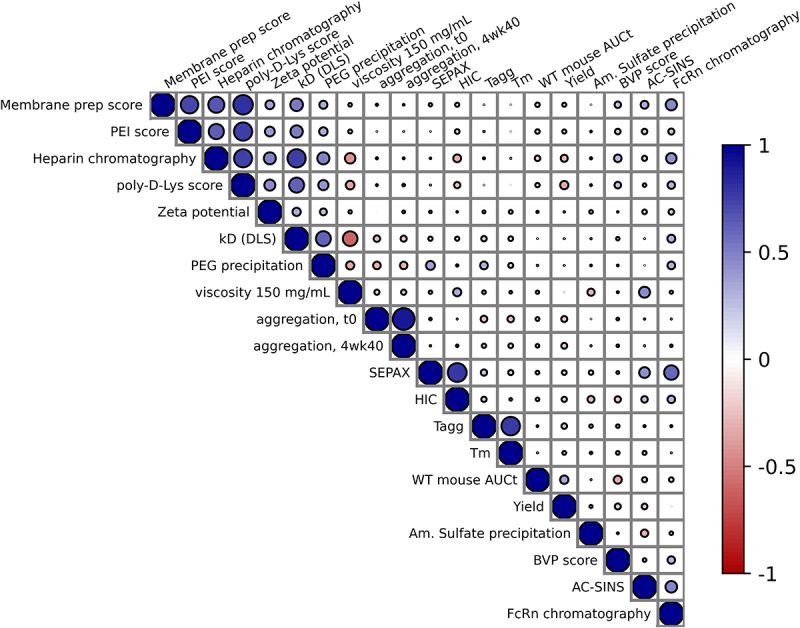
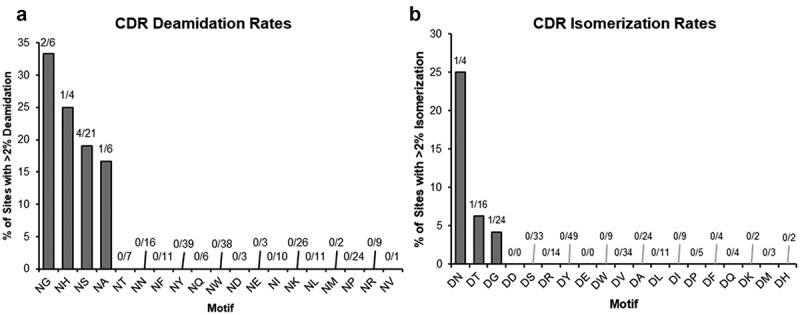
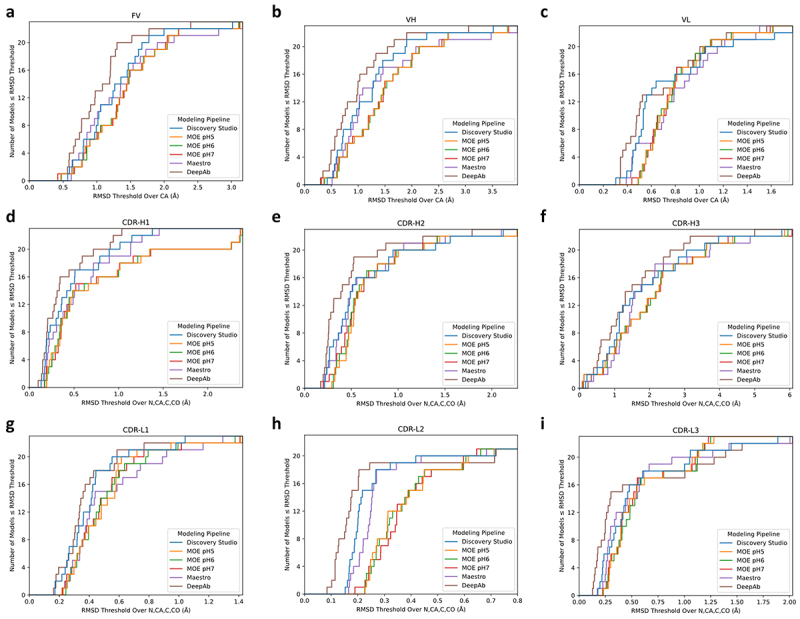
Biologic drug discovery pipelines are designed to deliver protein therapeutics that have exquisite functional potency and selectivity while also manifesting biophysical characteristics suitable for manufacturing, storage, and convenient administration to patients. The ability to use computational methods to predict biophysical properties from protein sequence, potentially in combination with high throughput assays, could decrease timelines and increase the success rates for therapeutic developability engineering by eliminating lengthy and expensive cycles of recombinant protein production and testing. To support development of high-quality predictive models for antibody developability, we designed a sequence-diverse panel of 83 effector functionless IgG1 antibodies displaying a range of biophysical properties, produced and formulated each protein under standard platform conditions, and collected a comprehensive package of analytical data, including in vitro assays and in vivo mouse pharmacokinetics. We used this robust training data set to build machine learning classifier models that can predict complex protein behavior from these data and features derived from predicted and/or experimental structures. Our models predict with 87% accuracy whether viscosity at 150 mg/mL is above or below a threshold of 15 centipoise (cP) and with 75% accuracy whether the area under the plasma drug concentration-time curve (AUC) in normal mouse is above or below a threshold of 3.9 × 10 h x ng/mL.
生物药物发现管道旨在提供具有精细功能效力和选择性的蛋白质治疗药物,同时还表现出适合制造、储存和方便患者给药的物理特性。能够使用计算方法从蛋白质序列预测物理特性,可能与高通量测定法结合使用,通过消除冗长和昂贵的重组蛋白生产和测试周期,缩短时间线并提高治疗可开发性工程的成功率。为了支持开发高质量的抗体可开发性预测模型,我们设计了一个由 83 种具有不同序列的效应功能缺失 IgG1 抗体组成的面板,这些抗体展示了一系列物理特性,在标准平台条件下生产和配制每种蛋白质,并收集了全面的分析数据,包括体外测定法和体内小鼠药代动力学。我们使用这个强大的训练数据集来构建机器学习分类器模型,这些模型可以根据这些数据以及从预测和/或实验结构中得出的特征来预测复杂的蛋白质行为。我们的模型以 87%的准确度预测 150mg/mL 时的粘度是否高于或低于 15 厘泊(cP)的阈值,以 75%的准确度预测正常小鼠中的血浆药物浓度-时间曲线下面积(AUC)是否高于或低于 3.9×10 h x ng/mL 的阈值。