Yu Feiyang, Endo Mark, Krishnan Rayan, Pan Ian, Tsai Andy, Reis Eduardo Pontes, Fonseca Eduardo Kaiser Ururahy Nunes, Lee Henrique Min Ho, Abad Zahra Shakeri Hossein, Ng Andrew Y, Langlotz Curtis P, Venugopal Vasantha Kumar, Rajpurkar Pranav
Department of Computer Science, Stanford University, Stanford, CA 94305, USA.
Department of Radiology, Brigham and Women's Hospital, Boston, MA 02115, USA.
Patterns (N Y). 2023 Aug 3;4(9):100802. doi: 10.1016/j.patter.2023.100802. eCollection 2023 Sep 8.
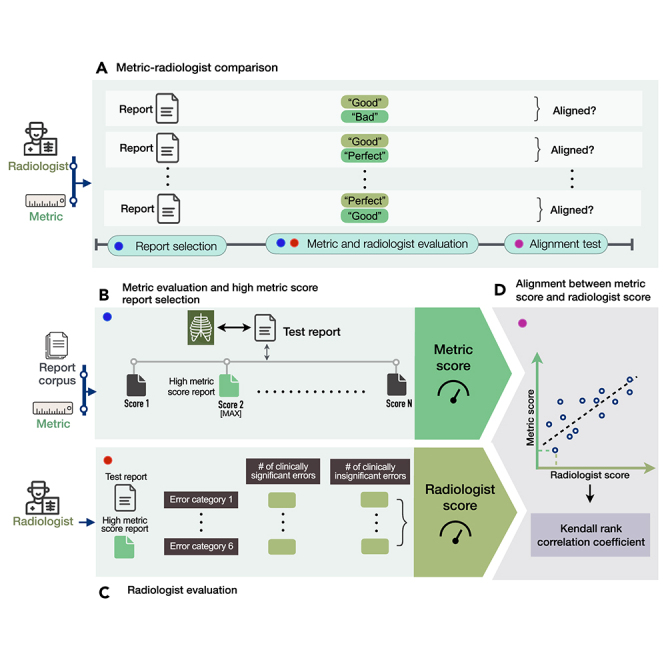
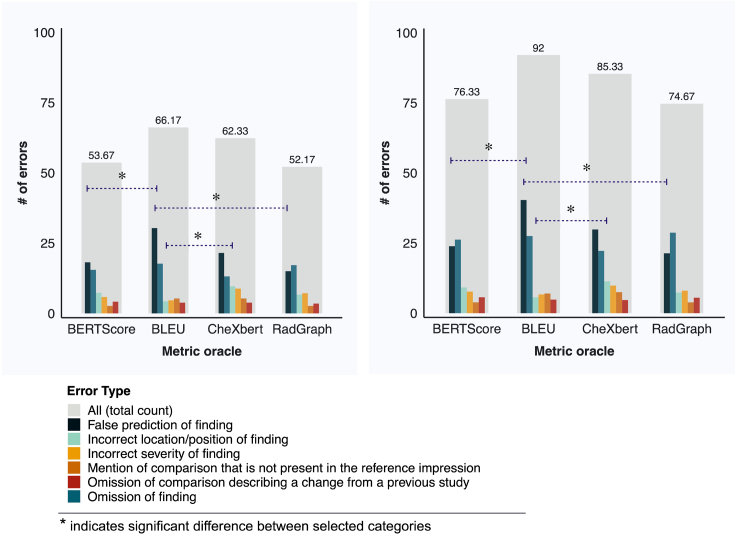
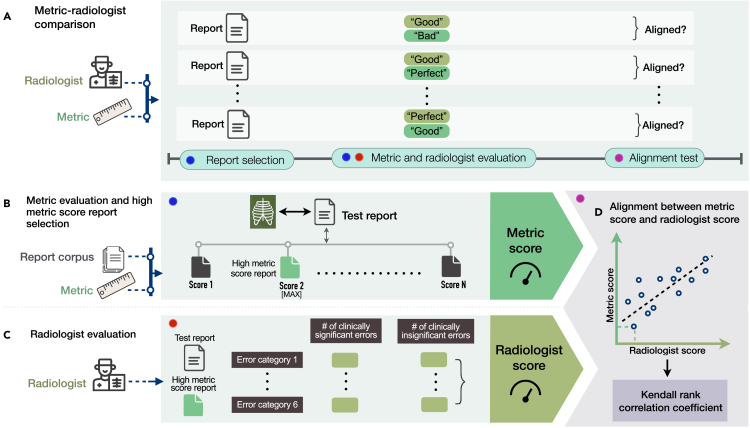
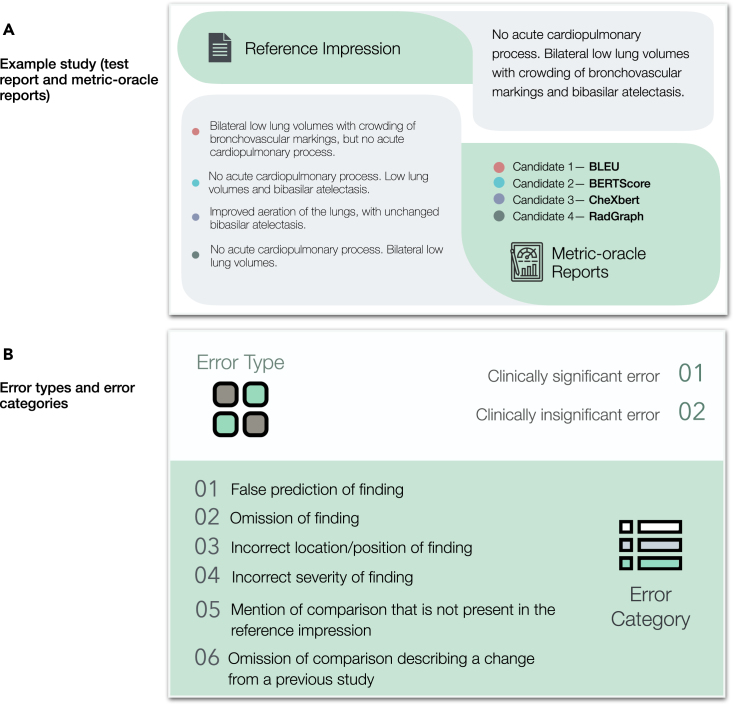
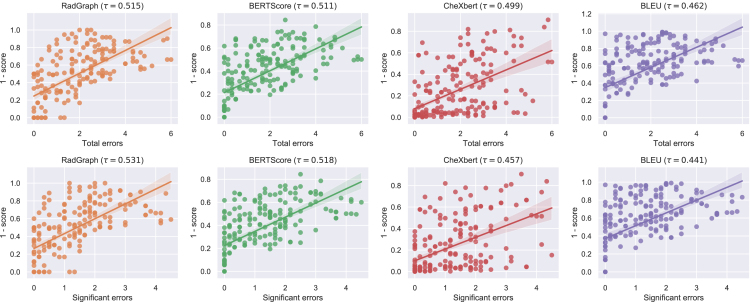
Artificial intelligence (AI) models for automatic generation of narrative radiology reports from images have the potential to enhance efficiency and reduce the workload of radiologists. However, evaluating the correctness of these reports requires metrics that can capture clinically pertinent differences. In this study, we investigate the alignment between automated metrics and radiologists' scoring of errors in report generation. We address the limitations of existing metrics by proposing new metrics, RadGraph F1 and RadCliQ, which demonstrate stronger correlation with radiologists' evaluations. In addition, we analyze the failure modes of the metrics to understand their limitations and provide guidance for metric selection and interpretation. This study establishes RadGraph F1 and RadCliQ as meaningful metrics for guiding future research in radiology report generation.
用于根据图像自动生成叙述性放射学报告的人工智能(AI)模型有提高效率和减轻放射科医生工作量的潜力。然而,评估这些报告的正确性需要能够捕捉临床相关差异的指标。在本研究中,我们调查了自动指标与放射科医生对报告生成错误的评分之间的一致性。我们通过提出新的指标RadGraph F1和RadCliQ来解决现有指标的局限性,这两个指标与放射科医生的评估显示出更强的相关性。此外,我们分析了指标的失败模式以了解其局限性,并为指标的选择和解释提供指导。本研究将RadGraph F1和RadCliQ确立为指导未来放射学报告生成研究的有意义的指标。