Surodina Svitlana, Lam Ching, Grbich Svetislav, Milne-Ives Madison, van Velthoven Michelle, Meinert Edward
Skein Ltd, London, United Kingdom.
Department of Informatics, King's College London, London, United Kingdom.
JMIRx Med. 2021 Jun 11;2(2):e25560. doi: 10.2196/25560.
Researching people with herpes simplex virus (HSV) is challenging because of poor data quality, low user engagement, and concerns around stigma and anonymity.
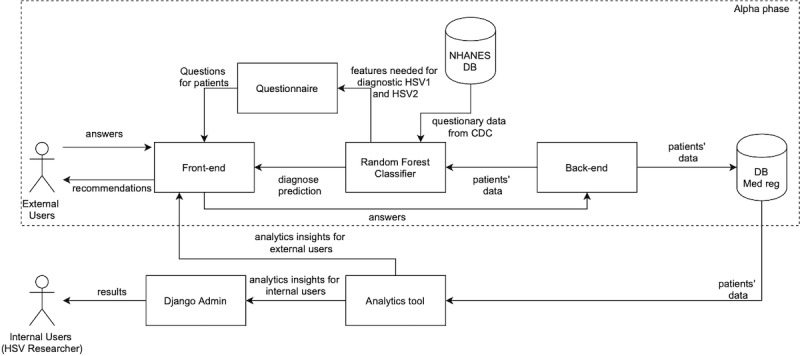
This project aimed to improve data collection for a real-world HSV registry by identifying predictors of HSV infection and selecting a limited number of relevant questions to ask new registry users to determine their level of HSV infection risk.
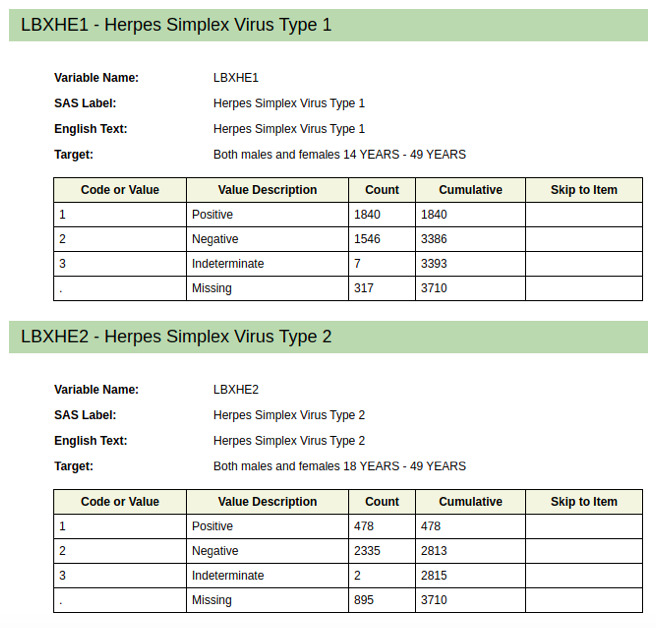
The US National Health and Nutrition Examination Survey (NHANES, 2015-2016) database includes the confirmed HSV type 1 and type 2 (HSV-1 and HSV-2, respectively) status of American participants (14-49 years) and a wealth of demographic and health-related data. The questionnaires and data sets from this survey were used to form two data sets: one for HSV-1 and one for HSV-2. These data sets were used to train and test a model that used a random forest algorithm (devised using Python) to minimize the number of anonymous lifestyle-based questions needed to identify risk groups for HSV.
The model selected a reduced number of questions from the NHANES questionnaire that predicted HSV infection risk with high accuracy scores of 0.91 and 0.96 and high recall scores of 0.88 and 0.98 for the HSV-1 and HSV-2 data sets, respectively. The number of questions was reduced from 150 to an average of 40, depending on age and gender. The model, therefore, provided high predictability of risk of infection with minimal required input.
This machine learning algorithm can be used in a real-world evidence registry to collect relevant lifestyle data and identify individuals' levels of risk of HSV infection. A limitation is the absence of real user data and integration with electronic medical records, which would enable model learning and improvement. Future work will explore model adjustments, anonymization options, explicit permissions, and a standardized data schema that meet the General Data Protection Regulation, Health Insurance Portability and Accountability Act, and third-party interface connectivity requirements.
由于数据质量差、用户参与度低以及对耻辱感和匿名性的担忧,对单纯疱疹病毒(HSV)感染者进行研究具有挑战性。
本项目旨在通过识别HSV感染的预测因素并选择有限数量的相关问题来询问新的登记用户,以确定其HSV感染风险水平,从而改善真实世界HSV登记处的数据收集情况。
美国国家健康与营养检查调查(NHANES,2015 - 2016)数据库包含美国参与者(14 - 49岁)确诊的1型和2型单纯疱疹病毒(分别为HSV - 1和HSV - 2)状态以及大量人口统计学和健康相关数据。本次调查的问卷和数据集用于形成两个数据集:一个用于HSV - 1,一个用于HSV - 2。这些数据集用于训练和测试一个使用随机森林算法(用Python设计)的模型,以尽量减少识别HSV风险群体所需的基于匿名生活方式的问题数量。
该模型从NHANES问卷中选择了数量减少的问题,对于HSV - 1和HSV - 2数据集,预测HSV感染风险的准确率分别为0.91和0.96,召回率分别为0.88和0.98。问题数量从150个减少到平均40个,具体取决于年龄和性别。因此,该模型以最少的所需输入提供了高感染风险预测能力。
这种机器学习算法可用于真实世界证据登记处,以收集相关生活方式数据并识别个体的HSV感染风险水平。一个局限性是缺乏真实用户数据以及与电子病历的整合,而这将有助于模型学习和改进。未来的工作将探索模型调整、匿名化选项、明确权限以及符合《通用数据保护条例》、《健康保险流通与责任法案》和第三方接口连接要求的标准化数据模式。