Levkovich Inbar, Elyoseph Zohar
Oranim Academic College, Faculty of Graduate Studies, Kiryat Tivon, Israel.
Department of Psychology and Educational Counseling, The Center for Psychobiological Research, Max Stern Yezreel Valley College, Emek Yezreel, Israel.
JMIR Ment Health. 2023 Sep 20;10:e51232. doi: 10.2196/51232.
ChatGPT, a linguistic artificial intelligence (AI) model engineered by OpenAI, offers prospective contributions to mental health professionals. Although having significant theoretical implications, ChatGPT's practical capabilities, particularly regarding suicide prevention, have not yet been substantiated.
The study's aim was to evaluate ChatGPT's ability to assess suicide risk, taking into consideration 2 discernable factors-perceived burdensomeness and thwarted belongingness-over a 2-month period. In addition, we evaluated whether ChatGPT-4 more accurately evaluated suicide risk than did ChatGPT-3.5.
ChatGPT was tasked with assessing a vignette that depicted a hypothetical patient exhibiting differing degrees of perceived burdensomeness and thwarted belongingness. The assessments generated by ChatGPT were subsequently contrasted with standard evaluations rendered by mental health professionals. Using both ChatGPT-3.5 and ChatGPT-4 (May 24, 2023), we executed 3 evaluative procedures in June and July 2023. Our intent was to scrutinize ChatGPT-4's proficiency in assessing various facets of suicide risk in relation to the evaluative abilities of both mental health professionals and an earlier version of ChatGPT-3.5 (March 14 version).
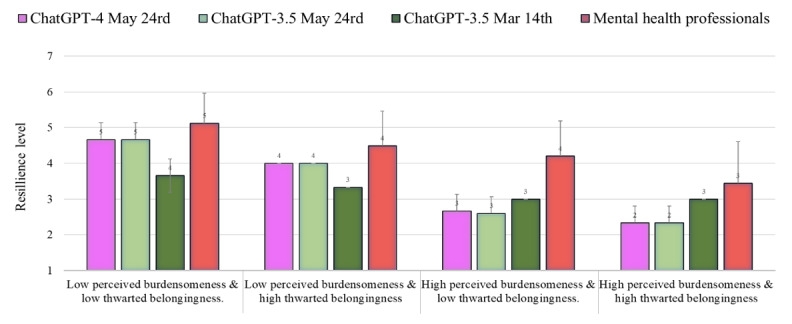
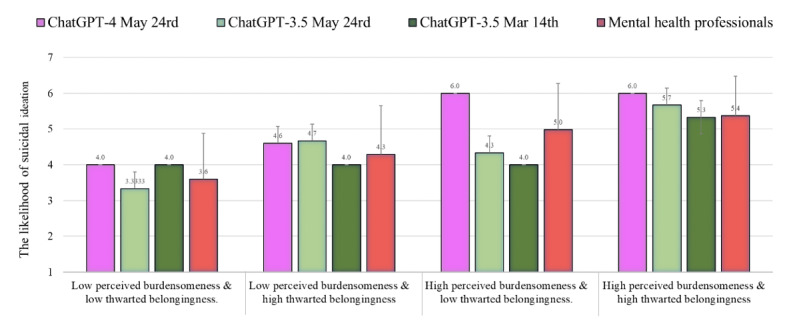
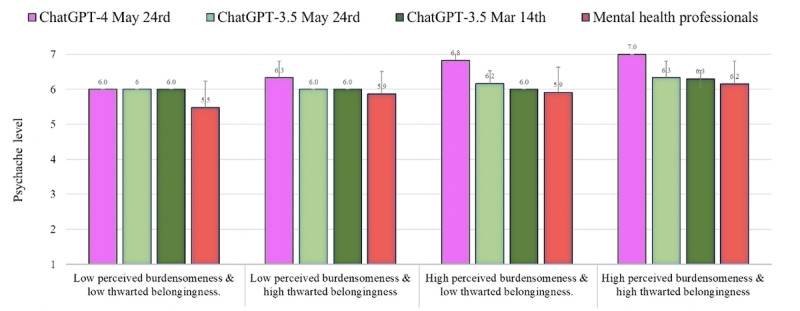
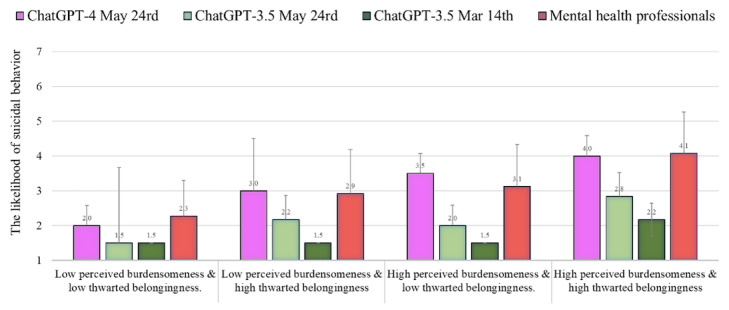
During the period of June and July 2023, we found that the likelihood of suicide attempts as evaluated by ChatGPT-4 was similar to the norms of mental health professionals (n=379) under all conditions (average Z score of 0.01). Nonetheless, a pronounced discrepancy was observed regarding the assessments performed by ChatGPT-3.5 (May version), which markedly underestimated the potential for suicide attempts, in comparison to the assessments carried out by the mental health professionals (average Z score of -0.83). The empirical evidence suggests that ChatGPT-4's evaluation of the incidence of suicidal ideation and psychache was higher than that of the mental health professionals (average Z score of 0.47 and 1.00, respectively). Conversely, the level of resilience as assessed by both ChatGPT-4 and ChatGPT-3.5 (both versions) was observed to be lower in comparison to the assessments offered by mental health professionals (average Z score of -0.89 and -0.90, respectively).
The findings suggest that ChatGPT-4 estimates the likelihood of suicide attempts in a manner akin to evaluations provided by professionals. In terms of recognizing suicidal ideation, ChatGPT-4 appears to be more precise. However, regarding psychache, there was an observed overestimation by ChatGPT-4, indicating a need for further research. These results have implications regarding ChatGPT-4's potential to support gatekeepers, patients, and even mental health professionals' decision-making. Despite the clinical potential, intensive follow-up studies are necessary to establish the use of ChatGPT-4's capabilities in clinical practice. The finding that ChatGPT-3.5 frequently underestimates suicide risk, especially in severe cases, is particularly troubling. It indicates that ChatGPT may downplay one's actual suicide risk level.
ChatGPT是OpenAI研发的一种语言人工智能(AI)模型,有望为心理健康专业人员做出贡献。尽管具有重大的理论意义,但ChatGPT的实际能力,特别是在自杀预防方面,尚未得到证实。
本研究旨在评估ChatGPT在两个月的时间内评估自杀风险的能力,同时考虑两个可辨别的因素——感知到的负担感和归属感受挫。此外,我们还评估了ChatGPT-4是否比ChatGPT-3.5更准确地评估自杀风险。
ChatGPT的任务是评估一个描述假设患者表现出不同程度的感知负担感和归属感受挫的案例。随后,将ChatGPT生成的评估结果与心理健康专业人员进行的标准评估进行对比。我们在2023年6月和7月使用ChatGPT-3.5和ChatGPT-4(2023年5月24日版本)执行了3项评估程序。我们的目的是审查ChatGPT-4在评估自杀风险各个方面的能力,与心理健康专业人员以及早期版本的ChatGPT-3.5(3月14日版本)的评估能力进行比较。
在2023年6月和7月期间,我们发现ChatGPT-4评估的自杀未遂可能性在所有情况下都与心理健康专业人员(n = 379)的标准相似(平均Z分数为0.01)。然而,观察到ChatGPT-3.5(5月版本)进行的评估与心理健康专业人员进行的评估存在明显差异,ChatGPT-3.5明显低估了自杀未遂的可能性(平均Z分数为-0.83)。实证证据表明,ChatGPT-4对自杀意念和心理痛苦发生率的评估高于心理健康专业人员(平均Z分数分别为0.47和1.00)。相反,与心理健康专业人员提供的评估相比,ChatGPT-4和ChatGPT-3.5(两个版本)评估的恢复力水平较低(平均Z分数分别为-0.89和-0.90)。
研究结果表明,ChatGPT-4评估自杀未遂可能性的方式与专业人员的评估方式类似。在识别自杀意念方面,ChatGPT-4似乎更准确。然而,关于心理痛苦,ChatGPT-4存在高估现象,这表明需要进一步研究。这些结果对ChatGPT-4支持守门人、患者甚至心理健康专业人员决策的潜力具有启示意义。尽管具有临床潜力,但需要进行深入的后续研究,以确定ChatGPT-4在临床实践中的应用能力。发现ChatGPT-3.5经常低估自杀风险,尤其是在严重情况下,这尤其令人担忧。这表明ChatGPT可能会淡化一个人的实际自杀风险水平。