Centre for Research into Ecological and Environmental Modelling, University of St Andrews, St Andrews, UK.
Wildlife Conservation Research Unit, Department of Biology, University of Oxford, Oxford, UK.
Proc Biol Sci. 2023 Sep 27;290(2007):20231261. doi: 10.1098/rspb.2023.1261.
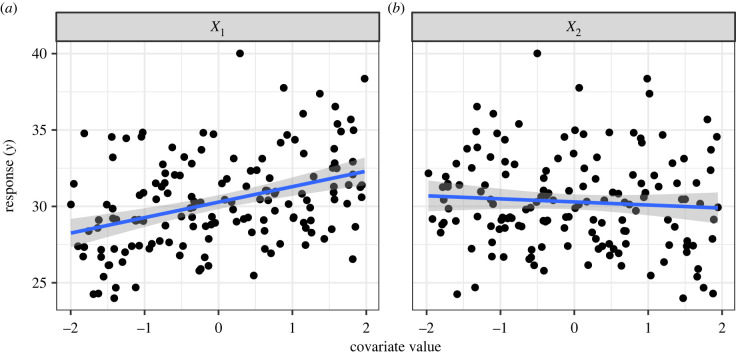
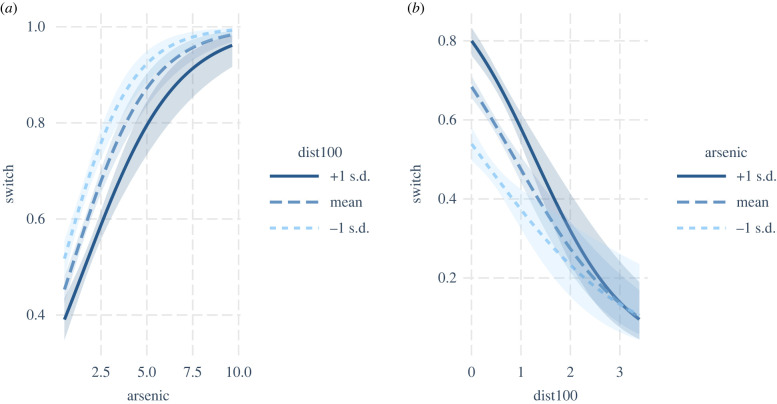
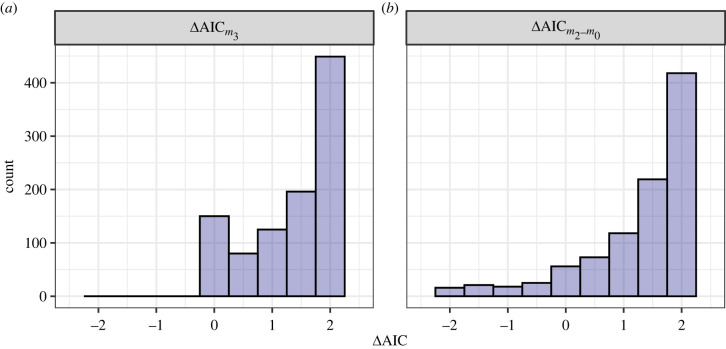
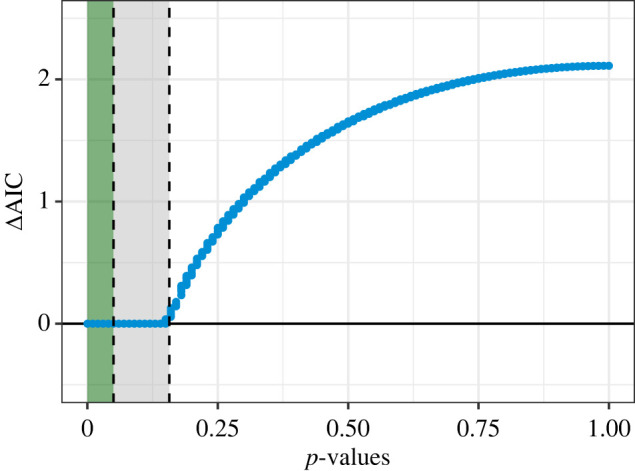
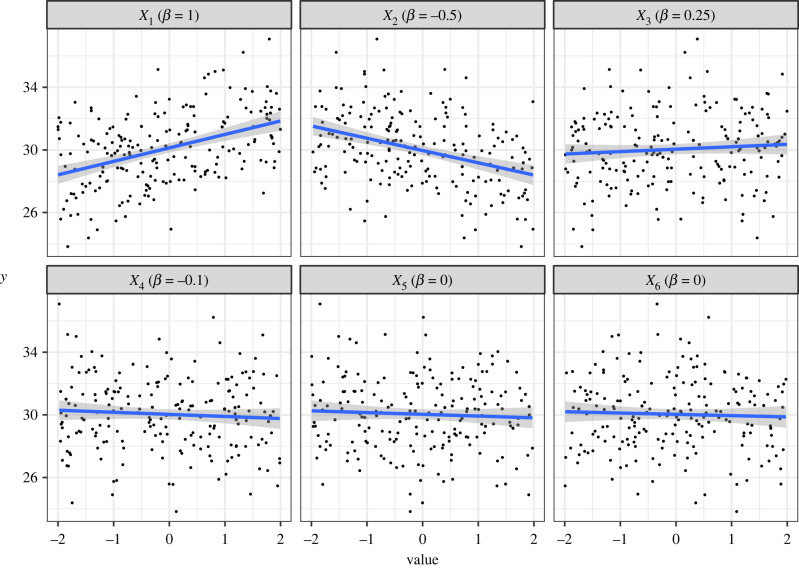
The various debates around model selection paradigms are important, but in lieu of a consensus, there is a demonstrable need for a deeper appreciation of existing approaches, at least among the end-users of statistics and model selection tools. In the ecological literature, the Akaike information criterion (AIC) dominates model selection practices, and while it is a relatively straightforward concept, there exists what we perceive to be some common misunderstandings around its application. Two specific questions arise with surprising regularity among colleagues and students when interpreting and reporting AIC model tables. The first is related to the issue of 'pretending' variables, and specifically a muddled understanding of what this means. The second is related to -values and what constitutes statistical support when using AIC. There exists a wealth of technical literature describing AIC and the relationship between -values and AIC differences. Here, we complement this technical treatment and use simulation to develop some intuition around these important concepts. In doing so we aim to promote better statistical practices when it comes to using, interpreting and reporting models selected when using AIC.
围绕模型选择范式的各种争论很重要,但在没有共识的情况下,至少在统计学和模型选择工具的最终用户中,显然需要更深入地了解现有方法。在生态学文献中,赤池信息量准则(AIC)主导着模型选择实践,尽管它是一个相对简单的概念,但在其应用方面存在着我们认为是一些常见的误解。当解释和报告 AIC 模型表时,同事和学生经常会问到两个具体问题。第一个问题与“假装”变量有关,特别是对这意味着什么的理解比较混乱。第二个问题与 - 值有关,以及在使用 AIC 时什么构成统计支持。有大量的技术文献描述了 AIC 以及 - 值和 AIC 差异之间的关系。在这里,我们补充了这种技术处理方法,并使用模拟来围绕这些重要概念发展一些直觉。这样做的目的是在使用 AIC 选择模型时,促进更好的统计实践,包括使用、解释和报告模型。