Kim Steven, Kim Dong Sub, Moyle Hana, Heo Seong
Department of Mathematics and Statistics, California State University, Monterey Bay, Seaside, USA.
Department of Horticulture, Kongju National University, Yesan, Korea.
Plant Methods. 2023 Oct 11;19(1):106. doi: 10.1186/s13007-023-01084-0.
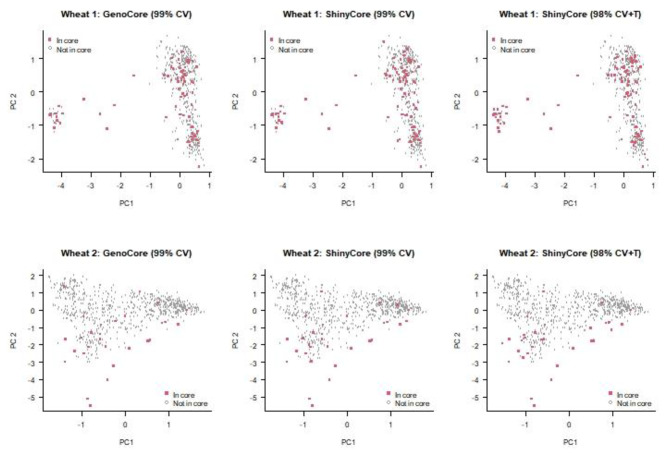
Managing and investigating all available genetic resources are challenging. As an alternative, breeders and researchers use core collection-a representative subset of the entire collection. A good core is characterized by high genetic diversity and low repetitiveness. Among the several available software, GenoCore uses a coverage criterion that does not require computationally expensive distance-based metrics.
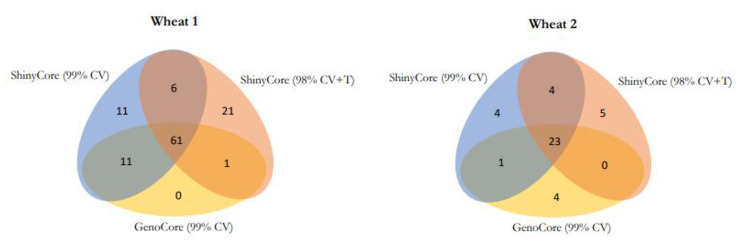
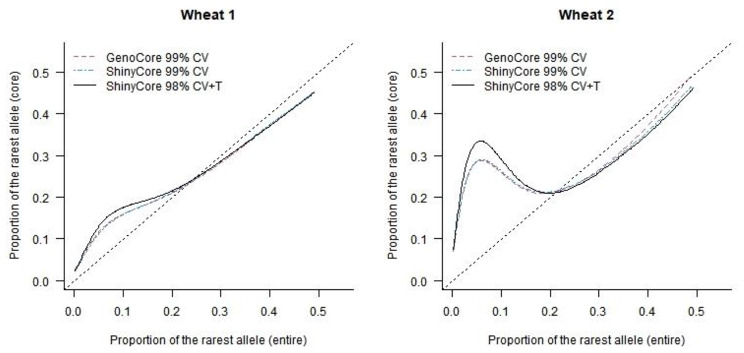
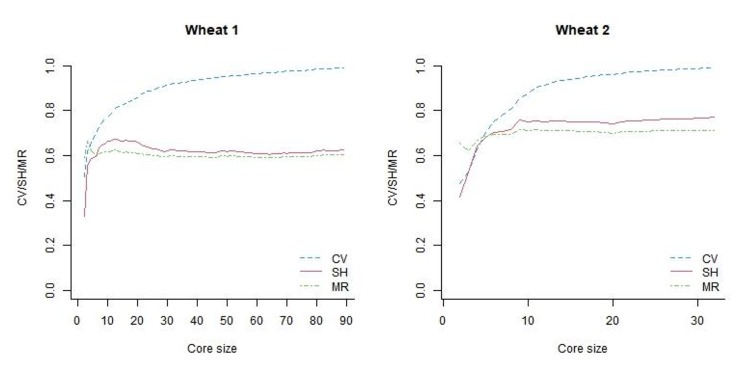
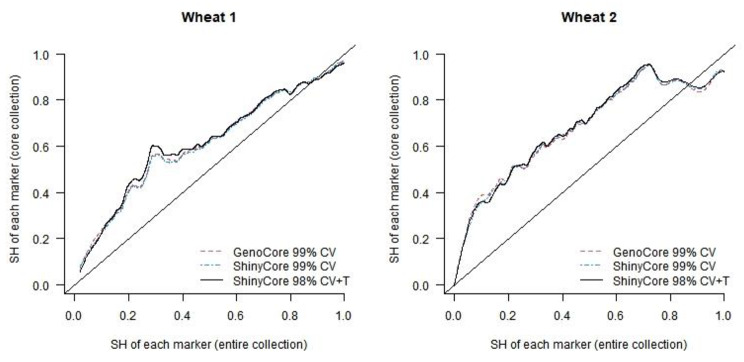
ShinyCore is a new method to select a core collection through two phases. The first phase uses the coverage criterion to quickly attain a fixed coverage, and the second phase uses a newly devised score (referred to as the rarity score) to further enhance diversity. It can attain a fixed coverage faster than a currently available algorithm devised for the coverage criterion, so it will benefit users who have big data. ShinyCore attains the minimum coverage specified by a user faster than GenoCore, and it then seeks to add entries with the rarest allele for each marker. Therefore, measures of genetic diversity and distance can be improved.
Although GenoCore is a fast algorithm, its implementation is difficult for those unfamiliar with R, ShinyCore can be easily implemented in Shiny with RStudio and an interactive web applet is available for those who are not familiar with programming languages.
管理和研究所有可用的遗传资源具有挑战性。作为一种替代方法,育种者和研究人员使用核心种质——整个种质库的一个具有代表性的子集。一个好的核心种质的特点是遗传多样性高且重复性低。在几种可用的软件中,GenoCore使用一种覆盖标准,该标准不需要基于距离的计算成本高昂的度量。
ShinyCore是一种通过两个阶段选择核心种质的新方法。第一阶段使用覆盖标准快速达到固定覆盖,第二阶段使用新设计的分数(称为稀有度分数)进一步提高多样性。它比目前为覆盖标准设计的算法更快地达到固定覆盖,因此将使拥有大数据的用户受益。ShinyCore比GenoCore更快地达到用户指定的最小覆盖,然后它会为每个标记寻找具有最稀有等位基因的条目。因此,可以提高遗传多样性和距离的度量。
尽管GenoCore是一种快速算法,但对于不熟悉R的人来说,它的实施很困难,ShinyCore可以很容易地在RStudio的Shiny中实现,并且为不熟悉编程语言的人提供了一个交互式网络小程序。