Msaouel Pavlos, Lee Juhee, Thall Peter F
Department of Genitourinary Medical Oncology, The University of Texas MD Anderson Cancer Center, Houston, TX 77030, USA.
Department of Translational Molecular Pathology, The University of Texas MD Anderson Cancer Center, Houston, TX 77030, USA.
Cancers (Basel). 2023 Sep 22;15(19):4674. doi: 10.3390/cancers15194674.
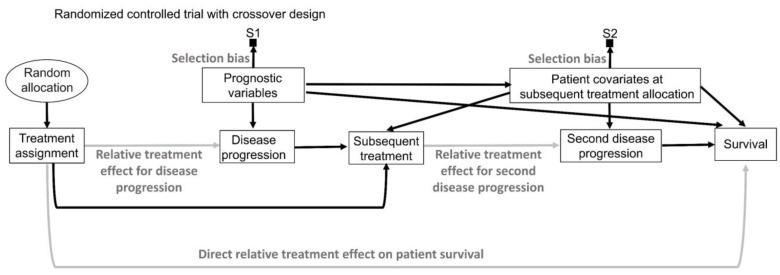
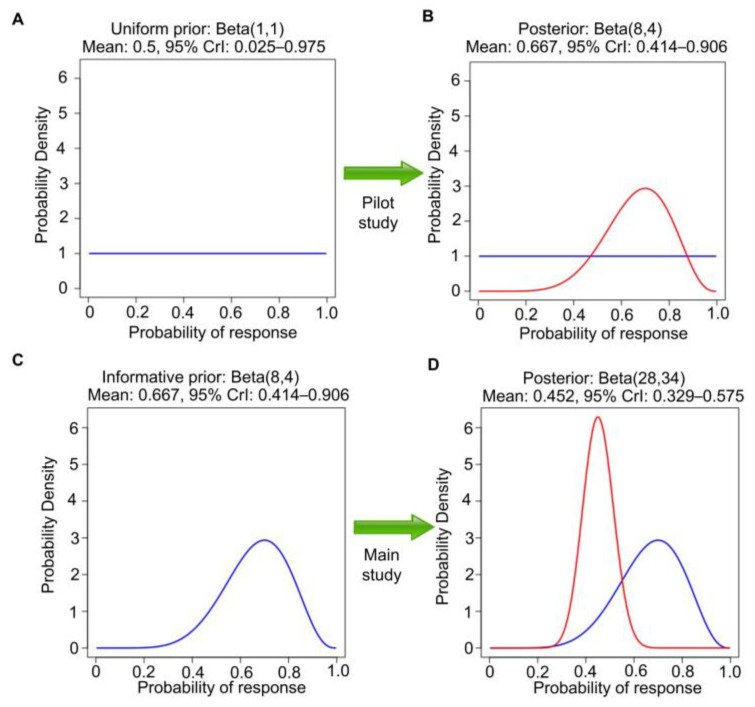
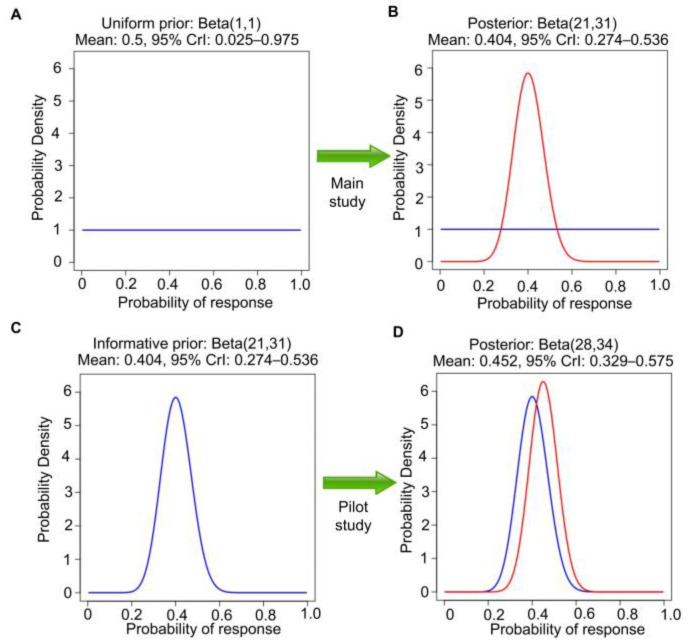
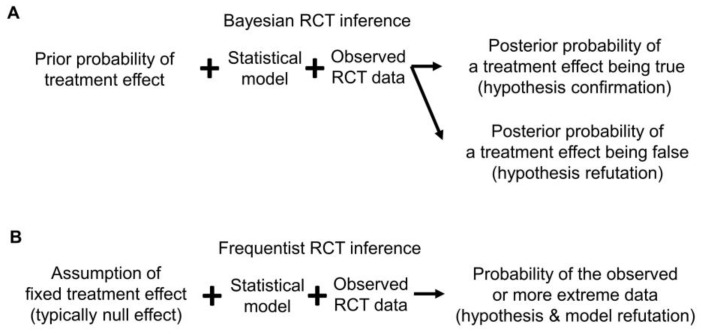
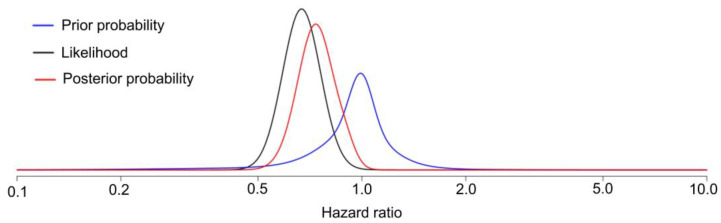
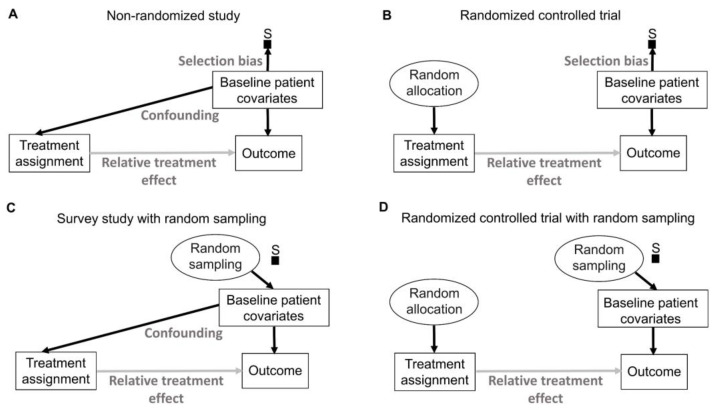
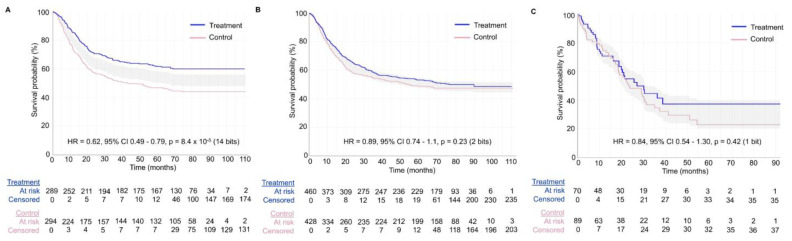
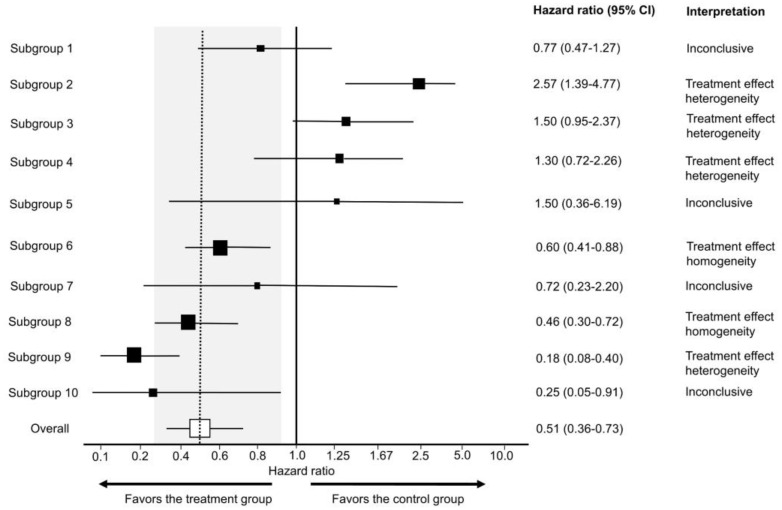
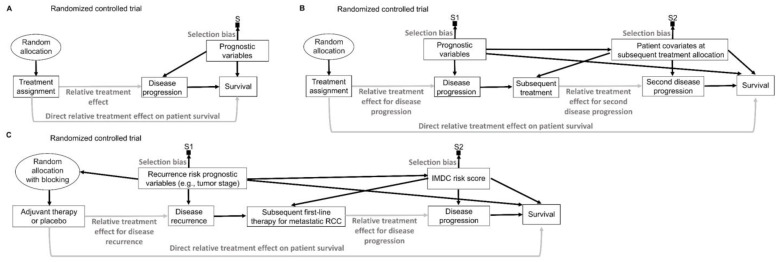
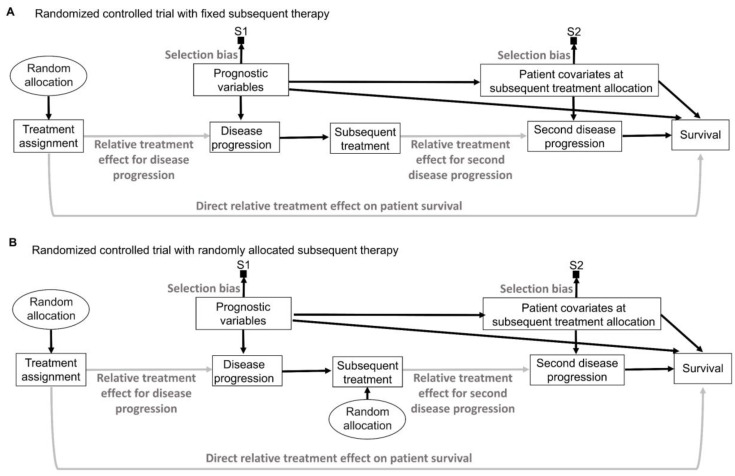
This article describes rationales and limitations for making inferences based on data from randomized controlled trials (RCTs). We argue that obtaining a representative random sample from a patient population is impossible for a clinical trial because patients are accrued sequentially over time and thus comprise a convenience sample, subject only to protocol entry criteria. Consequently, the trial's sample is unlikely to represent a definable patient population. We use causal diagrams to illustrate the difference between random allocation of interventions within a clinical trial sample and true simple or stratified random sampling, as executed in surveys. We argue that group-specific statistics, such as a median survival time estimate for a treatment arm in an RCT, have limited meaning as estimates of larger patient population parameters. In contrast, random allocation between interventions facilitates comparative causal inferences about between-treatment effects, such as hazard ratios or differences between probabilities of response. Comparative inferences also require the assumption of transportability from a clinical trial's convenience sample to a targeted patient population. We focus on the consequences and limitations of randomization procedures in order to clarify the distinctions between pairs of complementary concepts of fundamental importance to data science and RCT interpretation. These include internal and external validity, generalizability and transportability, uncertainty and variability, representativeness and inclusiveness, blocking and stratification, relevance and robustness, forward and reverse causal inference, intention to treat and per protocol analyses, and potential outcomes and counterfactuals.
本文描述了基于随机对照试验(RCT)数据进行推断的基本原理和局限性。我们认为,对于临床试验而言,从患者群体中获得具有代表性的随机样本是不可能的,因为患者是随着时间依次纳入的,因此构成了一个便利样本,仅受方案纳入标准的限制。因此,试验样本不太可能代表一个可定义的患者群体。我们使用因果图来说明临床试验样本中干预措施的随机分配与调查中执行的真正简单或分层随机抽样之间的差异。我们认为,特定组别的统计数据,如RCT中某治疗组的中位生存时间估计值,作为对更大患者群体参数的估计,其意义有限。相比之下,干预措施之间的随机分配有助于对治疗效果之间进行比较性因果推断,如风险比或反应概率之间的差异。比较性推断还需要假设从临床试验的便利样本到目标患者群体具有可转移性。我们关注随机化程序的后果和局限性,以阐明对数据科学和RCT解释至关重要的几对互补概念之间的区别。这些概念包括内部和外部有效性、可推广性和可转移性、不确定性和变异性、代表性和包容性、区组化和分层、相关性和稳健性、正向和反向因果推断、意向性分析和符合方案分析,以及潜在结果和反事实。