Huang Alexander A, Huang Samuel Y
Northwestern University Feinberg School of Medicine Chicago Illinois USA.
Virginia Commonwealth University School of Medicine Richmond Virginia USA.
Health Sci Rep. 2023 Oct 20;6(10):e1635. doi: 10.1002/hsr2.1635. eCollection 2023 Oct.
Depression affects personal and public well-being and identification of natural therapeutics such as nutrition is necessary to help alleviate this public health concern.
The study aimed to identify feature importance in a machine learning model using solely nutrition covariates.
A retrospective analysis was conducted using a modern, nationally representative cohort, the National Health and Nutrition Examination Surveys (NHANES 2017-2020). Depressive symptoms were evaluated using the validated 9-item Patient Health Questionnaire (PHQ-9), and all adult patients (total of 7929 individuals) who completed the PHQ-9 and total nutritional intake questionnaire were included in the study. Univariable regression was used to identify significant nutritional covariates to be included in a machine learning model and feature importance was reported. The acquisition and analysis of the data were authorized by the National Center for Health Statistics Ethics Review Board.
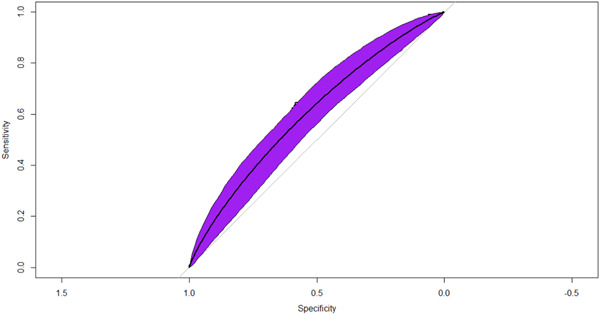
7929 patients met the inclusion criteria in this study. The machine learning model had 24 out of a total of 60 features that were found to be significant on univariate analysis ( < 0.01 used). In the XGBoost model the model had an Area Under the Receiver Operator Characteristic Curve (AUROC) = 0.603, Sensitivity = 0.943, Specificity = 0.163. The top four highest ranked features by gain, a measure of the percentage contribution of the covariate to the overall model prediction, were Potassium Intake (Gain = 6.8%), Vitamin E Intake (Gain = 5.7%), Number of Foods and Beverages Reported (Gain = 5.7%), and Vitamin K Intake (Gain 5.6%).
Machine learning models with feature importance can be utilized to identify nutritional covariates for further study in patients with clinical symptoms of depression.
抑郁症影响个人和公众健康,识别营养等自然疗法对于缓解这一公共卫生问题很有必要。
本研究旨在确定仅使用营养协变量的机器学习模型中的特征重要性。
使用具有全国代表性的现代队列——国家健康与营养检查调查(2017 - 2020年NHANES)进行回顾性分析。使用经过验证的9项患者健康问卷(PHQ - 9)评估抑郁症状,所有完成PHQ - 9和总营养摄入问卷的成年患者(共7929人)纳入研究。采用单变量回归确定纳入机器学习模型的显著营养协变量,并报告特征重要性。数据的获取和分析得到了国家卫生统计中心伦理审查委员会的授权。
本研究中有7929名患者符合纳入标准。机器学习模型在总共60个特征中有24个在单变量分析中被发现具有显著性(使用P < 0.01)。在XGBoost模型中,受试者工作特征曲线下面积(AUROC) = 0.603,敏感性 = 0.943,特异性 = 0.163。按增益(衡量协变量对总体模型预测的贡献百分比)排名前四的特征是钾摄入量(增益 = 6.8%)、维生素E摄入量(增益 = 5.7%)、报告的食物和饮料数量(增益 = 5.7%)以及维生素K摄入量(增益 = 5.6%)。
具有特征重要性的机器学习模型可用于识别营养协变量,以便在有抑郁临床症状的患者中进行进一步研究。