Department of Chinese Language & Literature, The Catholic University of Korea, 43 Jibong-Ro, Gyeonggi-Do, Bucheon-Si, 14662, Republic of Korea.
Sci Rep. 2023 Nov 21;13(1):20398. doi: 10.1038/s41598-023-47118-4.
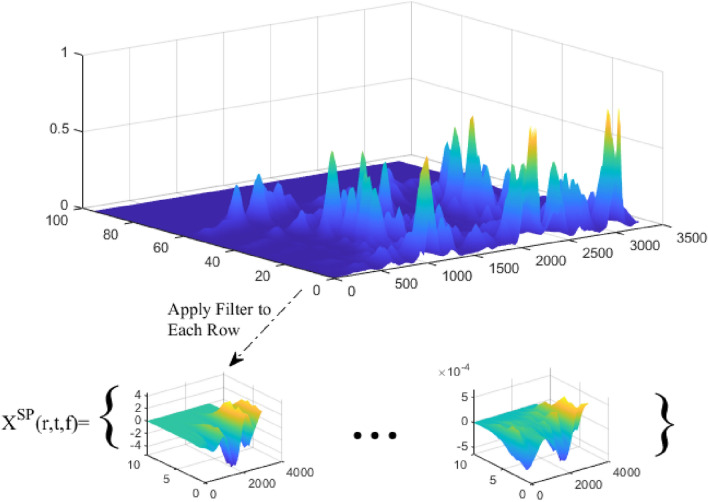
Speech emotion analysis is one of the most basic requirements for the evolution of Artificial Intelligence (AI) in the field of human-machine interaction. Accurate emotion recognition in speech can be effective in applications such as online support, lie detection systems and customer feedback analysis. However, the existing techniques for this field have not yet met sufficient development. This paper presents a new method to improve the performance of emotion analysis in speech. The proposed method includes the following steps: pre-processing, feature description, feature extraction, and classification. The initial description of speech features in the proposed method is done by using the combination of spectro-temporal modulation (STM) and entropy features. Also, a Convolutional Neural Network (CNN) is utilized to reduce the dimensions of these features and extract the features of each signal. Finally, the combination of gamma classifier (GC) and Error-Correcting Output Codes (ECOC) is applied to classify features and extract emotions in speech. The performance of the proposed method has been evaluated using two datasets, Berlin and ShEMO. The results show that the proposed method can recognize speech emotions in the Berlin and ShEMO datasets with an average accuracy of 93.33 and 85.73%, respectively, which is at least 6.67% better than compared methods.
语音情感分析是人机交互领域人工智能发展的最基本要求之一。在语音中进行准确的情感识别可以有效地应用于在线支持、测谎系统和客户反馈分析等领域。然而,该领域现有的技术尚未得到充分发展。本文提出了一种新的方法来提高语音情感分析的性能。所提出的方法包括以下步骤:预处理、特征描述、特征提取和分类。所提出方法中语音特征的初始描述是通过使用时频调制(STM)和熵特征的组合来完成的。此外,还利用卷积神经网络(CNN)来降低这些特征的维度,并提取每个信号的特征。最后,应用伽马分类器(GC)和纠错输出码(ECOC)组合来对特征进行分类并提取语音中的情感。使用两个数据集 Berlin 和 ShEMO 对所提出的方法的性能进行了评估。结果表明,该方法在 Berlin 和 ShEMO 数据集上识别语音情感的平均准确率分别为 93.33%和 85.73%,至少比比较方法好 6.67%。