McNeil Andrew J, Parks Kelsey, Liu Xiaoqi, Jiang Bohan, Coco Joseph, McCool Kira, Fabbri Daniel, Duhaime Erik P, Dawant Benoit M, Tkaczyk Eric R
Dermatology Service and Research Service, Department of Veterans Affairs, Tennessee Valley Healthcare System, Nashville, TN, United States.
Department of Dermatology, Vanderbilt University Medical Center, Nashville, TN, United States.
JMIR Dermatol. 2023 Dec 26;6:e48589. doi: 10.2196/48589.
Chronic graft-versus-host disease (cGVHD) is a significant cause of long-term morbidity and mortality in patients after allogeneic hematopoietic cell transplantation. Skin is the most commonly affected organ, and visual assessment of cGVHD can have low reliability. Crowdsourcing data from nonexpert participants has been used for numerous medical applications, including image labeling and segmentation tasks.
This study aimed to assess the ability of crowds of nonexpert raters-individuals without any prior training for identifying or marking cGHVD-to demarcate photos of cGVHD-affected skin. We also studied the effect of training and feedback on crowd performance.
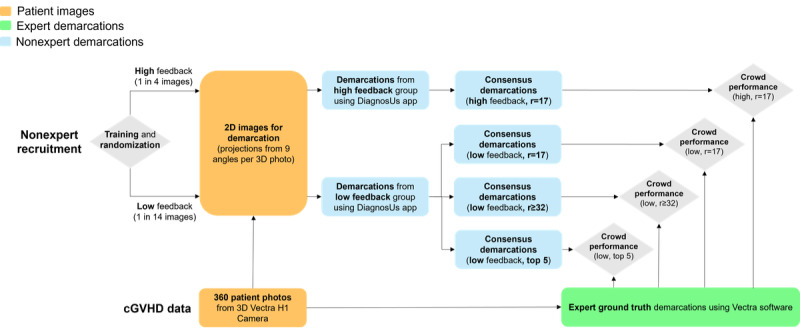
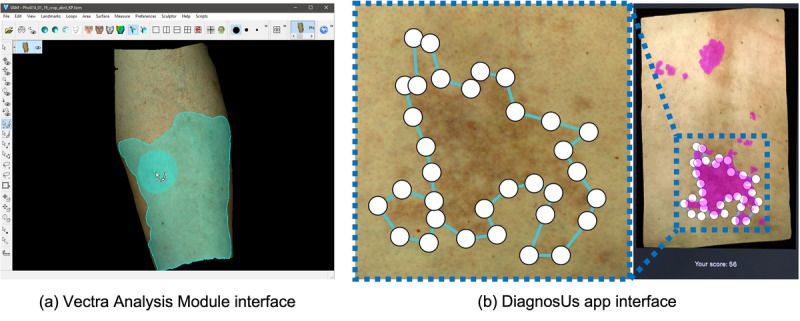
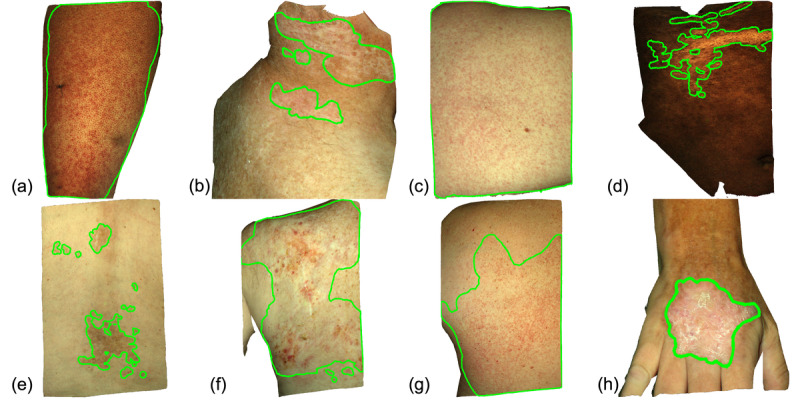
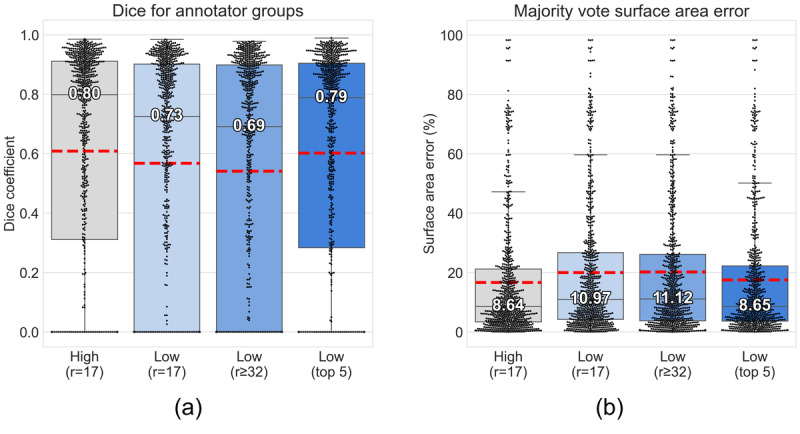
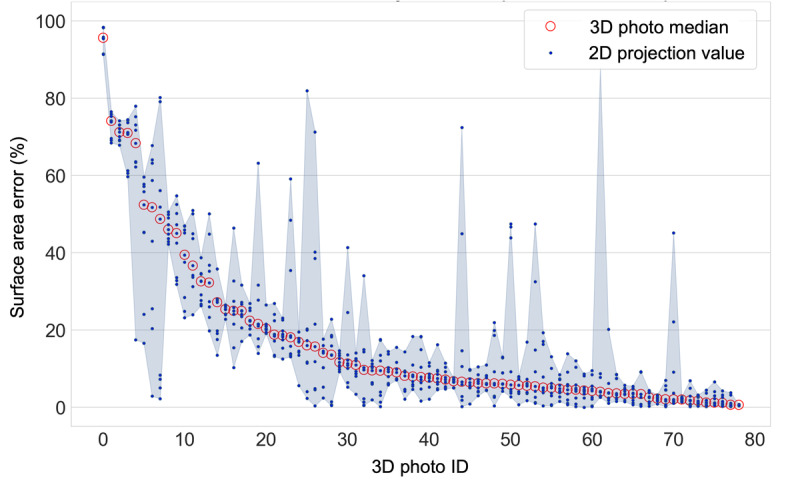
Using a Canfield Vectra H1 3D camera, 360 photographs of the skin of 36 patients with cGVHD were taken. Ground truth demarcations were provided in 3D by a trained expert and reviewed by a board-certified dermatologist. In total, 3000 2D images (projections from various angles) were created for crowd demarcation through the DiagnosUs mobile app. Raters were split into high and low feedback groups. The performances of 4 different crowds of nonexperts were analyzed, including 17 raters per image for the low and high feedback groups, 32-35 raters per image for the low feedback group, and the top 5 performers for each image from the low feedback group.
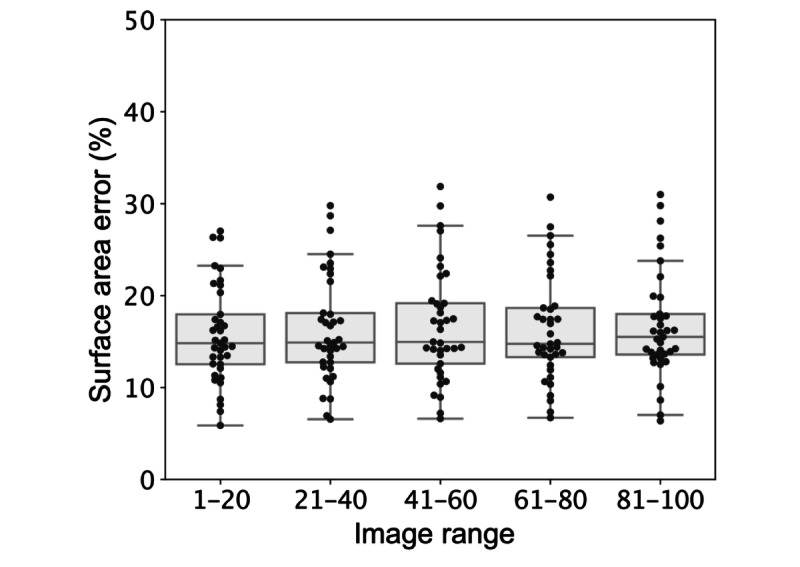
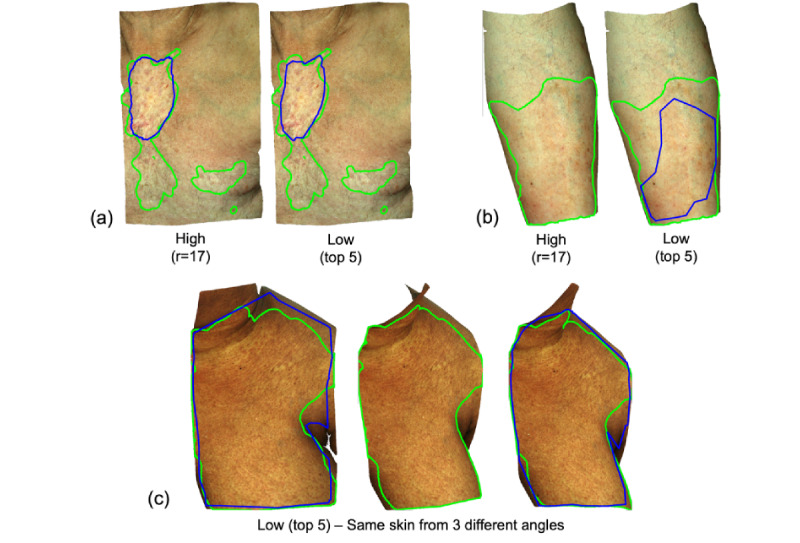
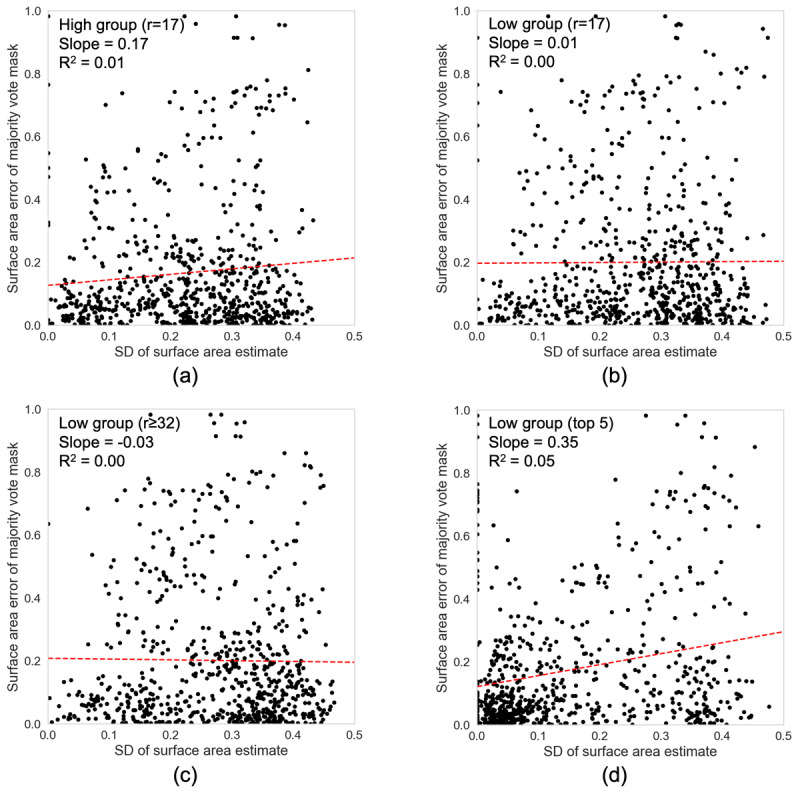
Across 8 demarcation competitions, 130 raters were recruited to the high feedback group and 161 to the low feedback group. This resulted in a total of 54,887 individual demarcations from the high feedback group and 78,967 from the low feedback group. The nonexpert crowds achieved good overall performance for segmenting cGVHD-affected skin with minimal training, achieving a median surface area error of less than 12% of skin pixels for all crowds in both the high and low feedback groups. The low feedback crowds performed slightly poorer than the high feedback crowd, even when a larger crowd was used. Tracking the 5 most reliable raters from the low feedback group for each image recovered a performance similar to that of the high feedback crowd. Higher variability between raters for a given image was not found to correlate with lower performance of the crowd consensus demarcation and cannot therefore be used as a measure of reliability. No significant learning was observed during the task as more photos and feedback were seen.
Crowds of nonexpert raters can demarcate cGVHD images with good overall performance. Tracking the top 5 most reliable raters provided optimal results, obtaining the best performance with the lowest number of expert demarcations required for adequate training. However, the agreement amongst individual nonexperts does not help predict whether the crowd has provided an accurate result. Future work should explore the performance of crowdsourcing in standard clinical photos and further methods to estimate the reliability of consensus demarcations.
慢性移植物抗宿主病(cGVHD)是异基因造血细胞移植患者长期发病和死亡的重要原因。皮肤是最常受影响的器官,对cGVHD的视觉评估可靠性可能较低。来自非专业参与者的众包数据已用于众多医学应用,包括图像标记和分割任务。
本研究旨在评估非专业评分者群体(即未接受过任何识别或标记cGVHD培训的个体)对cGVHD受累皮肤照片进行划分的能力。我们还研究了培训和反馈对群体表现的影响。
使用Canfield Vectra H1 3D相机,拍摄了36例cGVHD患者皮肤的360张照片。由一名经过培训的专家以3D形式提供真实边界,并由一名获得委员会认证的皮肤科医生进行审核。通过DiagnosUs移动应用程序总共创建了3000张二维图像(来自不同角度的投影)用于群体划分。评分者被分为高反馈组和低反馈组。分析了4个不同非专业群体的表现,包括低反馈组和高反馈组每张图像17名评分者、低反馈组每张图像32 - 35名评分者,以及低反馈组每张图像表现最佳的前5名评分者。
在8次划分竞赛中,130名评分者被招募到高反馈组,161名被招募到低反馈组。这导致高反馈组共有54887次个体划分,低反馈组有78967次。非专业群体在经过最少培训后对cGVHD受累皮肤进行分割时总体表现良好,高反馈组和低反馈组所有群体的皮肤像素表面积误差中位数均小于12%。低反馈群体的表现略逊于高反馈群体,即使使用了更大的群体。跟踪低反馈组每张图像最可靠的5名评分者,其表现与高反馈群体相似。未发现给定图像评分者之间较高的变异性与群体共识划分的较低表现相关,因此不能将其用作可靠性的衡量标准。在任务过程中,随着看到更多照片和反馈,未观察到显著的学习效果。
非专业评分者群体能够以良好的总体表现对cGVHD图像进行划分。跟踪最可靠的前5名评分者可提供最佳结果,以最少的专家划分数量进行充分训练即可获得最佳表现。然而,个体非专业人员之间的一致性无助于预测群体是否给出了准确结果。未来的工作应探索众包在标准临床照片中的表现,以及进一步估计共识划分可靠性的方法。