School of Epidemiology and Public Health, University of Ottawa, Ottawa, Canada.
Clinical Epidemiology Program, Ottawa Hospital Research Institute, Ottawa, Canada.
PLoS One. 2024 Feb 7;19(2):e0295921. doi: 10.1371/journal.pone.0295921. eCollection 2024.
Synthetic datasets are artificially manufactured based on real health systems data but do not contain real patient information. We sought to validate the use of synthetic data in stroke and cancer research by conducting a comparison study of cancer patients with ischemic stroke to non-cancer patients with ischemic stroke.
retrospective cohort study.
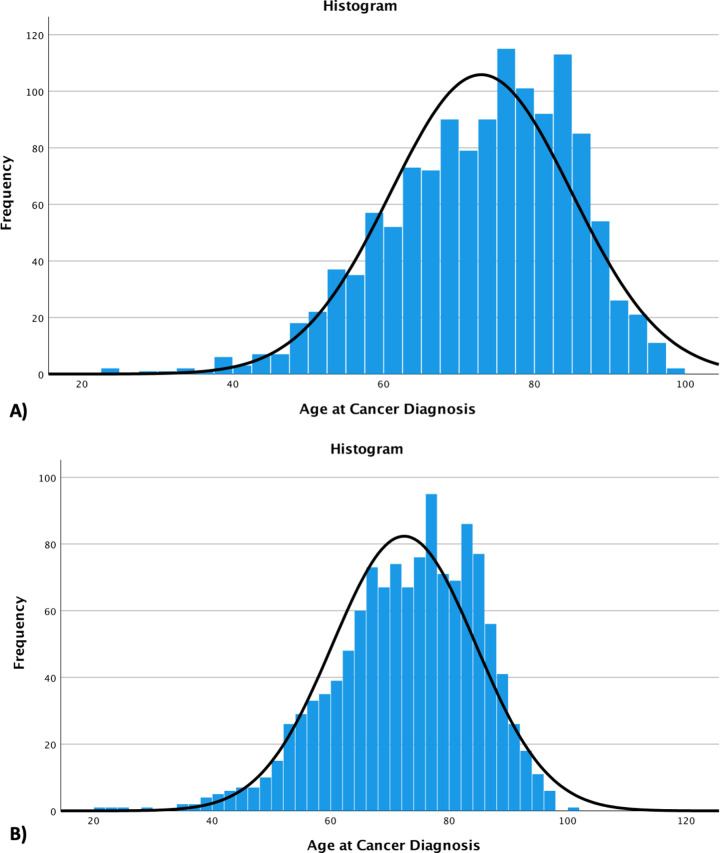
We used synthetic data generated by MDClone and compared it to its original source data (i.e. real patient data from the Ottawa Hospital Data Warehouse).
We compared key differences in demographics, treatment characteristics, length of stay, and costs between cancer patients with ischemic stroke and non-cancer patients with ischemic stroke. We used a binary, multivariable logistic regression model to identify risk factors for recurrent stroke in the cancer population.
Using synthetic data, we found cancer patients with ischemic stroke had a lower prevalence of hypertension (52.0% in the cancer cohort vs 57.7% in the non-cancer cohort, p<0.0001), and a higher prevalence of chronic obstructive pulmonary disease (COPD: 8.5% vs 4.7%, p<0.0001), prior ischemic stroke (1.7% vs 0.1%, p<0.001), and prior venous thromboembolism (VTE: 8.2% vs 1.5%, p<0.0001). They also had a longer length of stay (8 days [IQR 3-16] vs 6 days [IQR 3-13], p = 0.011), and higher costs associated with their stroke encounters: $11,498 (IQR $4,440 -$20,668) in the cancer cohort vs $8,084 (IQR $3,947 -$16,706) in the non-cancer cohort (p = 0.0061). A multivariable logistic regression model identified 5 predictors for recurrent ischemic stroke in the cancer cohort using synthetic data; 3 of the same predictors identified using real patient data with similar effect measures. Summary statistics between synthetic and original datasets did not significantly differ, other than slight differences in the distributions of frequencies for numeric data.
We demonstrated the utility of synthetic data in stroke and cancer research and provided key differences between cancer and non-cancer patients with ischemic stroke. Synthetic data is a powerful tool that can allow researchers to easily explore hypothesis generation, enable data sharing without privacy breaches, and ensure broad access to big data in a rapid, safe, and reliable fashion.
合成数据集是根据真实的健康系统数据人工制造的,但不包含真实患者的信息。我们通过对患有缺血性中风的癌症患者与非癌症患者进行比较研究,旨在验证在中风和癌症研究中使用合成数据的合理性。
回顾性队列研究。
我们使用 MDClone 生成的合成数据,并将其与原始数据源数据(即渥太华医院数据仓库中的真实患者数据)进行比较。
我们比较了患有缺血性中风的癌症患者与非癌症患者在人口统计学、治疗特征、住院时间和费用方面的关键差异。我们使用二元多变量逻辑回归模型来确定癌症人群中复发性中风的危险因素。
我们证明了合成数据在中风和癌症研究中的实用性,并提供了癌症和非癌症缺血性中风患者之间的关键差异。合成数据是一种强大的工具,可以帮助研究人员轻松地探索假设生成,在不侵犯隐私的情况下实现数据共享,并以快速、安全和可靠的方式确保对大数据的广泛访问。