Division of General Medical Sciences, School of Medicine, Washington University in St. Louis, St. Louis, MO, United States.
Institute for Informatics, School of Medicine, Washington University in St. Louis, St. Louis, MO, United States.
J Med Internet Res. 2021 Oct 4;23(10):e30697. doi: 10.2196/30697.
Computationally derived ("synthetic") data can enable the creation and analysis of clinical, laboratory, and diagnostic data as if they were the original electronic health record data. Synthetic data can support data sharing to answer critical research questions to address the COVID-19 pandemic.
We aim to compare the results from analyses of synthetic data to those from original data and assess the strengths and limitations of leveraging computationally derived data for research purposes.
We used the National COVID Cohort Collaborative's instance of MDClone, a big data platform with data-synthesizing capabilities (MDClone Ltd). We downloaded electronic health record data from 34 National COVID Cohort Collaborative institutional partners and tested three use cases, including (1) exploring the distributions of key features of the COVID-19-positive cohort; (2) training and testing predictive models for assessing the risk of admission among these patients; and (3) determining geospatial and temporal COVID-19-related measures and outcomes, and constructing their epidemic curves. We compared the results from synthetic data to those from original data using traditional statistics, machine learning approaches, and temporal and spatial representations of the data.
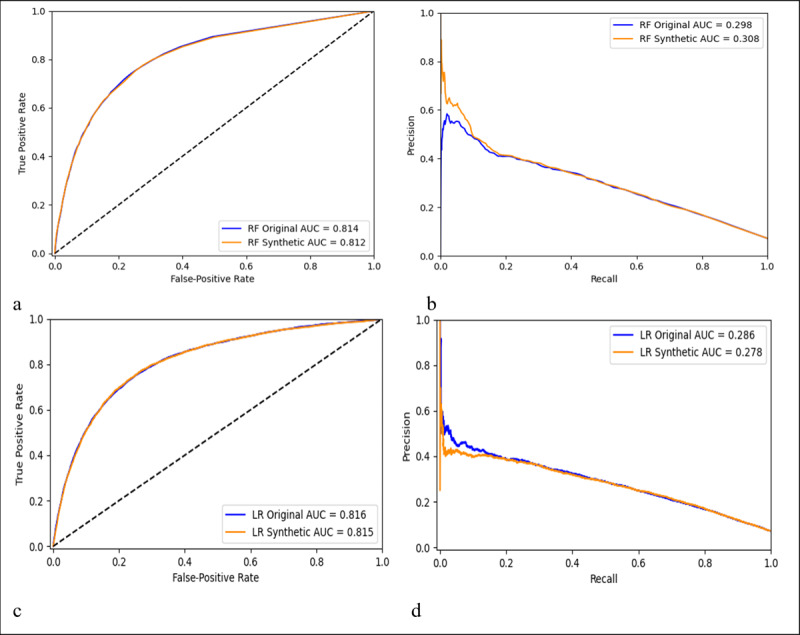
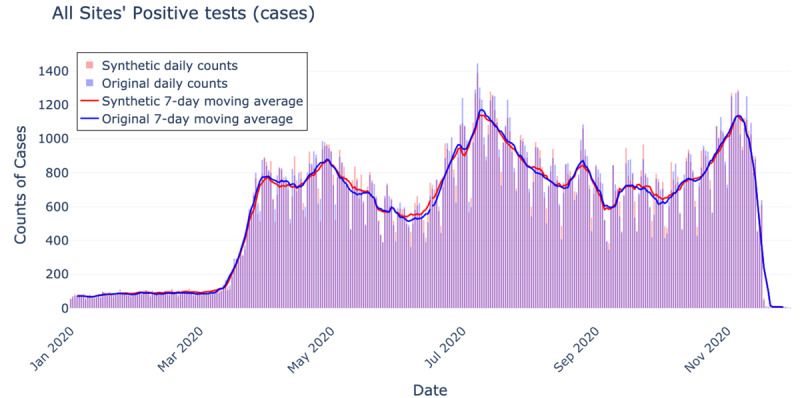
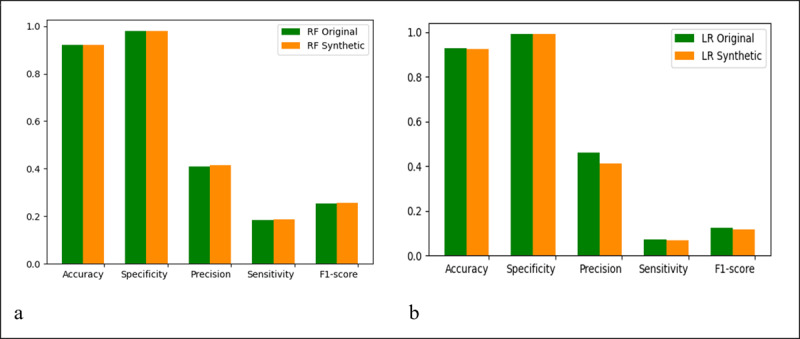
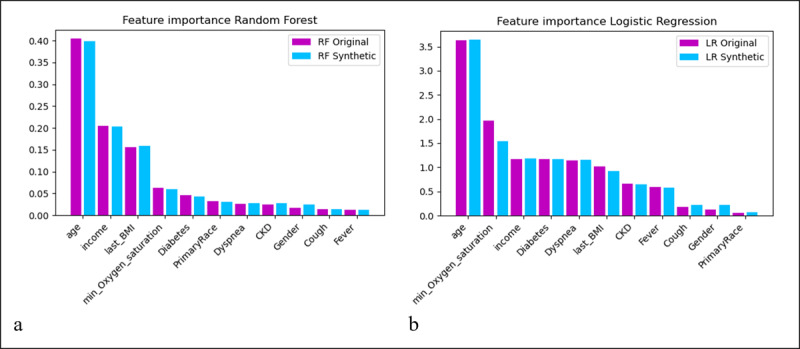
For each use case, the results of the synthetic data analyses successfully mimicked those of the original data such that the distributions of the data were similar and the predictive models demonstrated comparable performance. Although the synthetic and original data yielded overall nearly the same results, there were exceptions that included an odds ratio on either side of the null in multivariable analyses (0.97 vs 1.01) and differences in the magnitude of epidemic curves constructed for zip codes with low population counts.
This paper presents the results of each use case and outlines key considerations for the use of synthetic data, examining their role in collaborative research for faster insights.
计算衍生(“合成”)数据可以创建和分析临床、实验室和诊断数据,就像它们是原始电子健康记录数据一样。合成数据可以支持数据共享,以回答关键研究问题,应对 COVID-19 大流行。
我们旨在比较分析合成数据的结果与原始数据的结果,并评估利用计算衍生数据进行研究的优势和局限性。
我们使用了具有数据合成功能的大数据平台 MDClone 的 National COVID Cohort Collaborative 的实例(MDClone Ltd)。我们从 34 个 National COVID Cohort Collaborative 机构合作伙伴下载了电子健康记录数据,并测试了三个用例,包括(1)探索 COVID-19 阳性队列的关键特征分布;(2)训练和测试评估这些患者入院风险的预测模型;(3)确定与 COVID-19 相关的时空措施和结果,并构建其流行曲线。我们使用传统统计学、机器学习方法以及数据的时空表示来比较合成数据和原始数据的结果。
对于每个用例,合成数据分析的结果成功地模拟了原始数据的结果,使得数据的分布相似,预测模型表现出可比的性能。尽管合成数据和原始数据总体上产生了几乎相同的结果,但也存在例外,包括多变量分析中单侧的优势比(0.97 与 1.01)和构建人口数量低的邮政编码的流行曲线的幅度差异。
本文介绍了每个用例的结果,并概述了使用合成数据的关键考虑因素,探讨了它们在协作研究中更快获得见解的作用。