Amacher Simon A, Arpagaus Armon, Sahmer Christian, Becker Christoph, Gross Sebastian, Urben Tabita, Tisljar Kai, Sutter Raoul, Marsch Stephan, Hunziker Sabina
Intensive Care Medicine, Department of Acute Medical Care, University Hospital Basel, Basel, Switzerland.
Medical Communication and Psychosomatic Medicine, University Hospital Basel, Basel, Switzerland.
Resusc Plus. 2024 Feb 22;18:100587. doi: 10.1016/j.resplu.2024.100587. eCollection 2024 Jun.
To investigate the prognostic accuracy of a non-medical generative artificial intelligence model (Chat Generative Pre-Trained Transformer 4 - ChatGPT-4) as a novel aspect in predicting death and poor neurological outcome at hospital discharge based on real-life data from cardiac arrest patients.
This prospective cohort study investigates the prognostic performance of ChatGPT-4 to predict outcomes at hospital discharge of adult cardiac arrest patients admitted to intensive care at a large Swiss tertiary academic medical center (COMMUNICATE/PROPHETIC cohort study). We prompted ChatGPT-4 with sixteen prognostic parameters derived from established post-cardiac arrest scores for each patient. We compared the prognostic performance of ChatGPT-4 regarding the area under the curve (AUC), sensitivity, specificity, positive and negative predictive values, and likelihood ratios of three cardiac arrest scores (Out-of-Hospital Cardiac Arrest [OHCA], Cardiac Arrest Hospital Prognosis [CAHP], and PROgnostication using LOGistic regression model for Unselected adult cardiac arrest patients in the Early stages [PROLOGUE score]) for in-hospital mortality and poor neurological outcome.
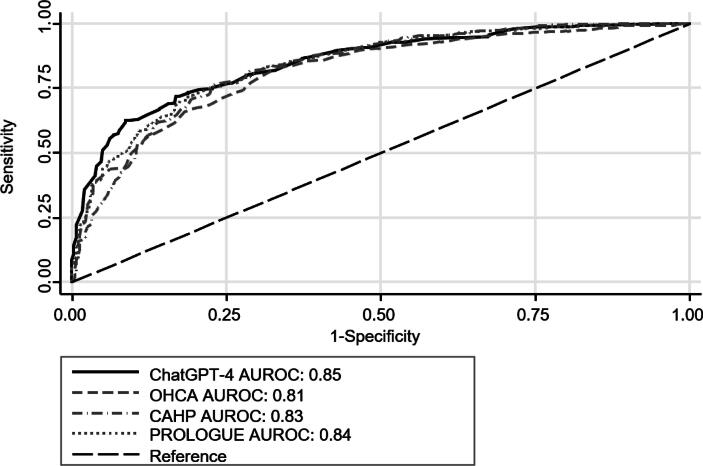
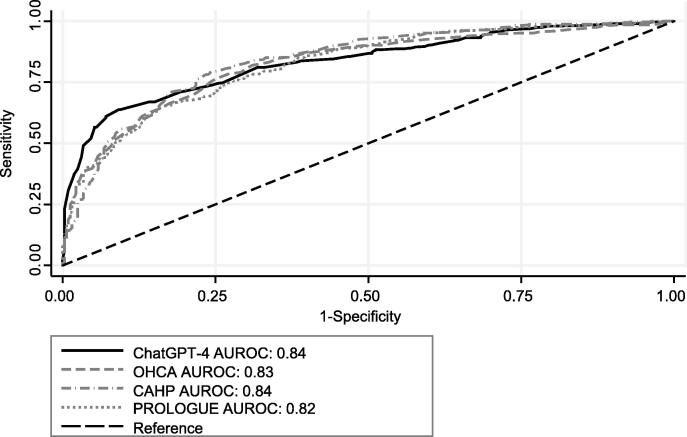
Mortality at hospital discharge was 43% (n = 309/713), 54% of patients (n = 387/713) had a poor neurological outcome. ChatGPT-4 showed good discrimination regarding in-hospital mortality with an AUC of 0.85, similar to the OHCA, CAHP, and PROLOGUE (AUCs of 0.82, 0.83, and 0.84, respectively) scores. For poor neurological outcome, ChatGPT-4 showed a similar prediction to the post-cardiac arrest scores (AUC 0.83).
ChatGPT-4 showed a similar performance in predicting mortality and poor neurological outcome compared to validated post-cardiac arrest scores. However, more research is needed regarding illogical answers for potential incorporation of an LLM in the multimodal outcome prognostication after cardiac arrest.
基于心脏骤停患者的真实数据,研究一种非医学生成式人工智能模型(聊天生成预训练变换器4 - ChatGPT-4)在预测出院时死亡和不良神经学结局方面作为一个新因素的预后准确性。
这项前瞻性队列研究调查了ChatGPT-4在瑞士一家大型三级学术医疗中心接受重症监护的成年心脏骤停患者出院时预测结局的预后性能(COMMUNICATE/PROPHETIC队列研究)。我们为ChatGPT-4提供了从每位患者既定的心脏骤停后评分中得出的16个预后参数。我们比较了ChatGPT-4在曲线下面积(AUC)、敏感性、特异性、阳性和阴性预测值以及三个心脏骤停评分(院外心脏骤停[OHCA]、心脏骤停医院预后[CAHP]和使用逻辑回归模型对早期未选择的成年心脏骤停患者进行预后评估[PROLOGUE评分])的似然比方面对院内死亡率和不良神经学结局的预后性能。
出院时死亡率为43%(n = 309/713),54%的患者(n = 387/713)有不良神经学结局。ChatGPT-4在院内死亡率方面显示出良好的区分能力,AUC为0.85,与OHCA、CAHP和PROLOGUE评分(AUC分别为0.82、0.83和0.84)相似。对于不良神经学结局,ChatGPT-4显示出与心脏骤停后评分相似的预测能力(AUC为0.83)。
与经过验证的心脏骤停后评分相比,ChatGPT-4在预测死亡率和不良神经学结局方面表现相似。然而,对于在心脏骤停后多模式结局预后中潜在纳入大语言模型的不合逻辑答案,还需要更多研究。