Han Lifeng, Gladkoff Serge, Erofeev Gleb, Sorokina Irina, Galiano Betty, Nenadic Goran
Department of Computer Science, The University of Manchester, Manchester, United Kingom.
AI Lab, Logrus Global, Translation & Localization, Philadelphia, PA, United States.
Front Digit Health. 2024 Feb 26;6:1211564. doi: 10.3389/fdgth.2024.1211564. eCollection 2024.
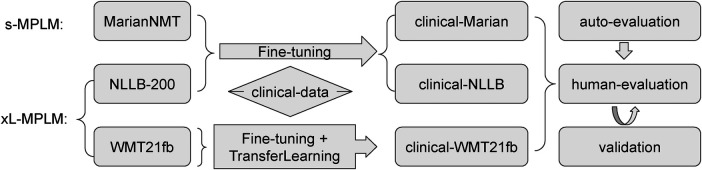
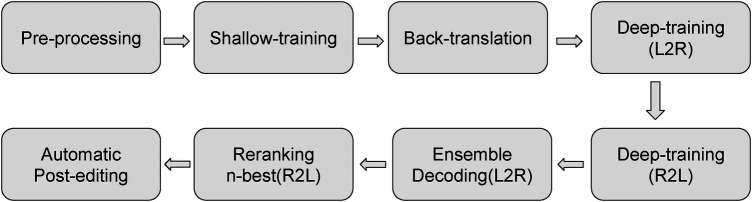
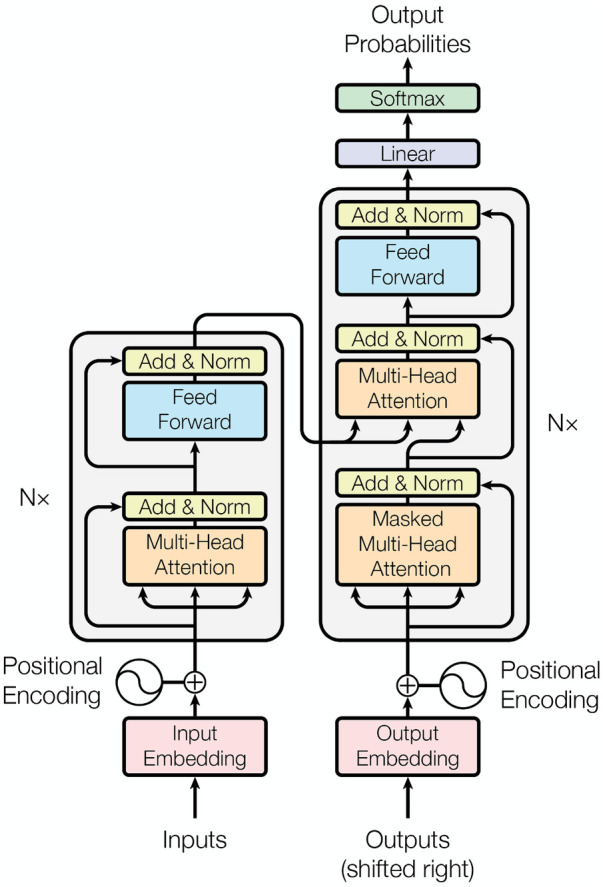
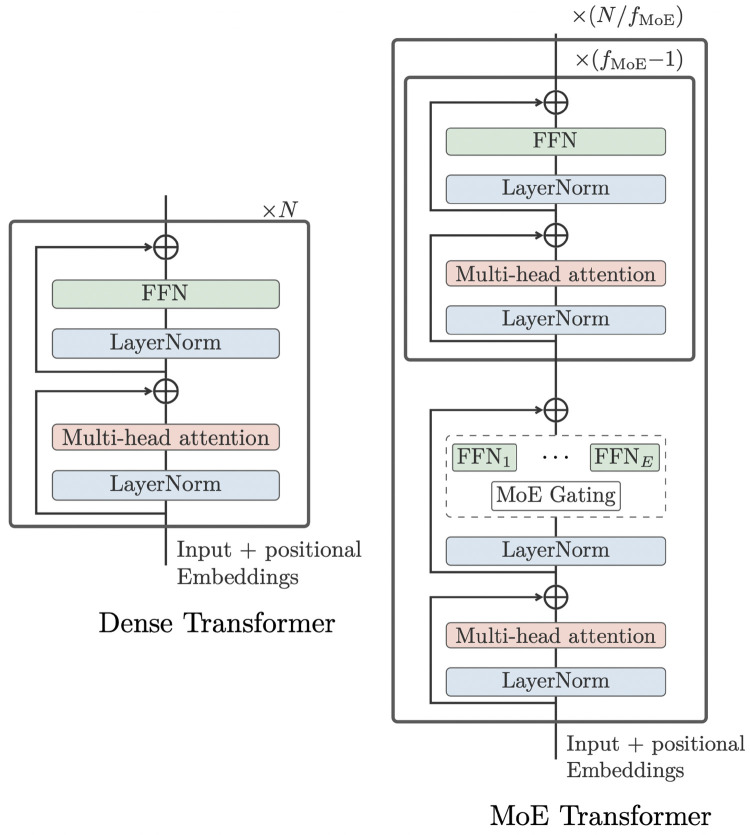
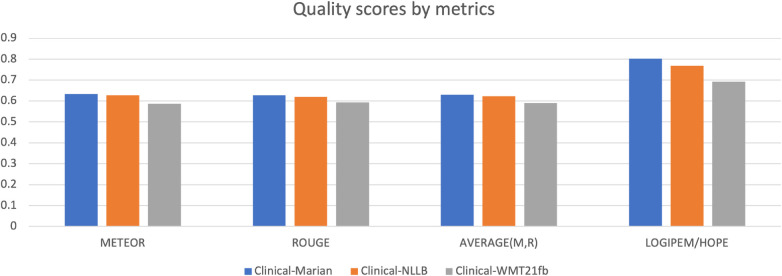
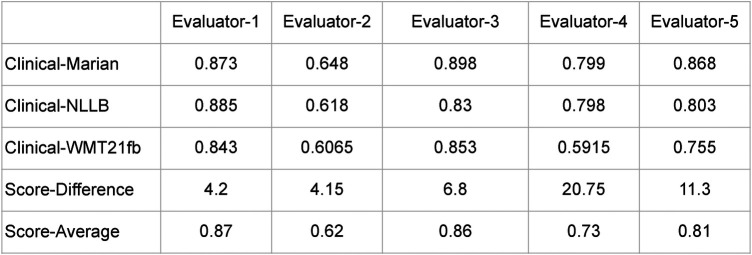
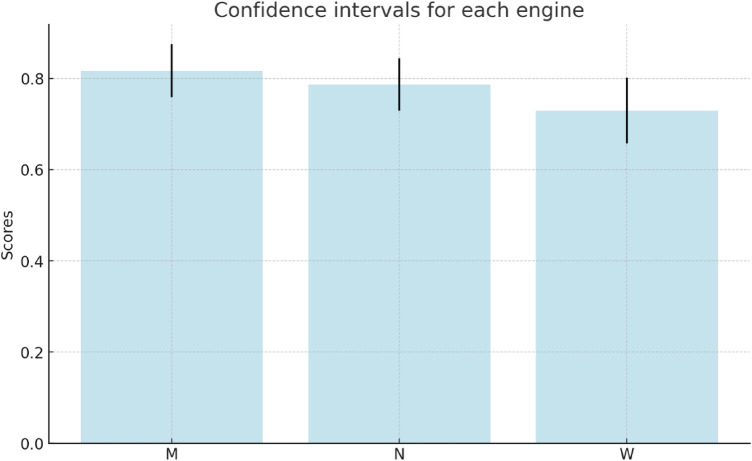
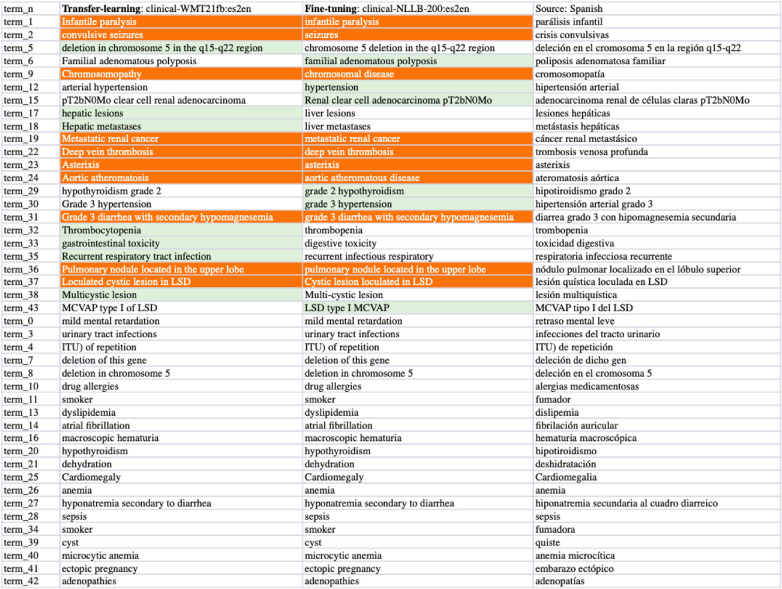
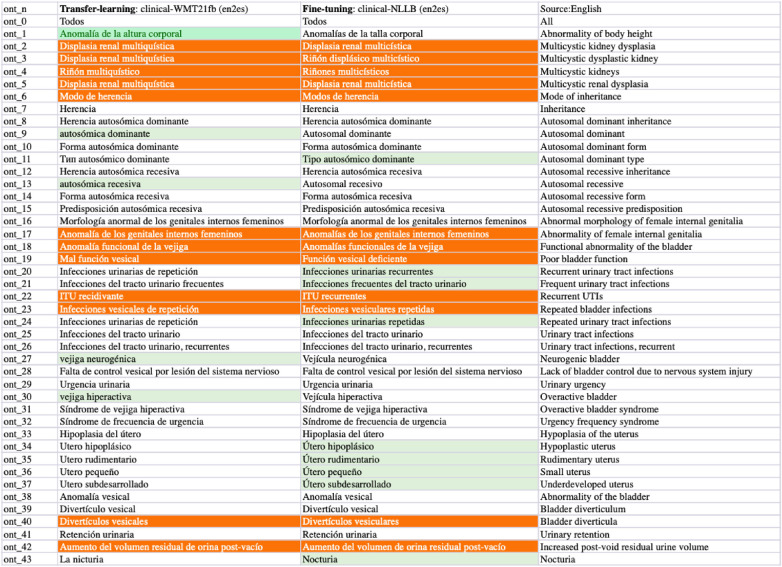
Clinical text and documents contain very rich information and knowledge in healthcare, and their processing using state-of-the-art language technology becomes very important for building intelligent systems for supporting healthcare and social good. This processing includes creating language understanding models and translating resources into other natural languages to share domain-specific cross-lingual knowledge. In this work, we conduct investigations on clinical text machine translation by examining multilingual neural network models using deep learning such as Transformer based structures. Furthermore, to address the language resource imbalance issue, we also carry out experiments using a transfer learning methodology based on massive multilingual pre-trained language models (MMPLMs). The experimental results on three sub-tasks including (1) clinical case (CC), (2) clinical terminology (CT), and (3) ontological concept (OC) show that our models achieved top-level performances in the ClinSpEn-2022 shared task on English-Spanish clinical domain data. Furthermore, our expert-based human evaluations demonstrate that the small-sized pre-trained language model (PLM) outperformed the other two extra-large language models by a large margin in the clinical domain fine-tuning, which finding was never reported in the field. Finally, the transfer learning method works well in our experimental setting using the WMT21fb model to accommodate a new language space Spanish that was not seen at the pre-training stage within WMT21fb itself, which deserves more exploitation for clinical knowledge transformation, e.g. to investigate into more languages. These research findings can shed some light on domain-specific machine translation development, especially in clinical and healthcare fields. Further research projects can be carried out based on our work to improve healthcare text analytics and knowledge transformation. Our data is openly available for research purposes at: https://github.com/HECTA-UoM/ClinicalNMT.
临床文本和文档包含医疗保健领域非常丰富的信息和知识,利用先进的语言技术对其进行处理对于构建支持医疗保健和社会公益的智能系统变得非常重要。这种处理包括创建语言理解模型以及将资源翻译成其他自然语言以共享特定领域的跨语言知识。在这项工作中,我们通过研究使用深度学习的多语言神经网络模型(如基于Transformer的结构)来进行临床文本机器翻译的调查。此外,为了解决语言资源不平衡问题,我们还基于大规模多语言预训练语言模型(MMPLMs)使用迁移学习方法进行实验。在包括(1)临床病例(CC)、(2)临床术语(CT)和(3)本体概念(OC)的三个子任务上的实验结果表明,我们的模型在ClinSpEn - 2022英语 - 西班牙语临床领域数据共享任务中取得了顶级性能。此外,我们基于专家的人工评估表明,在临床领域微调中,小型预训练语言模型(PLM)比其他两个超大型语言模型表现出色得多,这一发现从未在该领域报道过。最后,迁移学习方法在我们使用WMT21fb模型的实验设置中效果良好,以适应一个在WMT21fb本身预训练阶段未见过的新语言空间西班牙语,这值得在临床知识转化方面进行更多探索,例如研究更多语言。这些研究结果可以为特定领域的机器翻译发展提供一些启示,特别是在临床和医疗保健领域。可以基于我们的工作开展进一步的研究项目,以改善医疗文本分析和知识转化。我们的数据可公开用于研究目的,网址为:https://github.com/HECTA - UoM/ClinicalNMT。