Noor Kawsar, Roguski Lukasz, Bai Xi, Handy Alex, Klapaukh Roman, Folarin Amos, Romao Luis, Matteson Joshua, Lea Nathan, Zhu Leilei, Asselbergs Folkert W, Wong Wai Keong, Shah Anoop, Dobson Richard Jb
University College London, London, United Kingdom.
Institute of Health Informatics, University College London, London, United Kingdom.
JMIR Med Inform. 2022 Aug 24;10(8):e38122. doi: 10.2196/38122.
As more health care organizations transition to using electronic health record (EHR) systems, it is important for these organizations to maximize the secondary use of their data to support service improvement and clinical research. These organizations will find it challenging to have systems capable of harnessing the unstructured data fields in the record (clinical notes, letters, etc) and more practically have such systems interact with all of the hospital data systems (legacy and current).
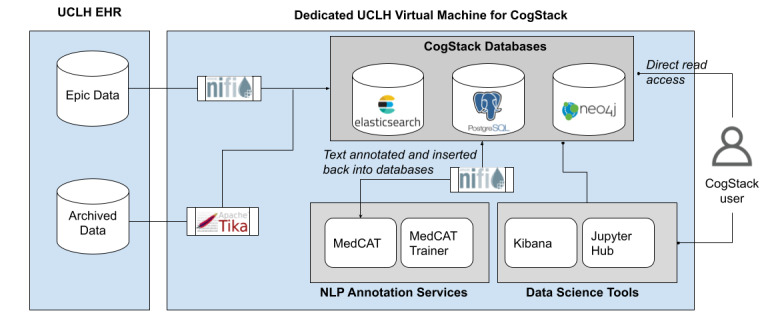
We describe the deployment of the EHR interfacing information extraction and retrieval platform CogStack at University College London Hospitals (UCLH).
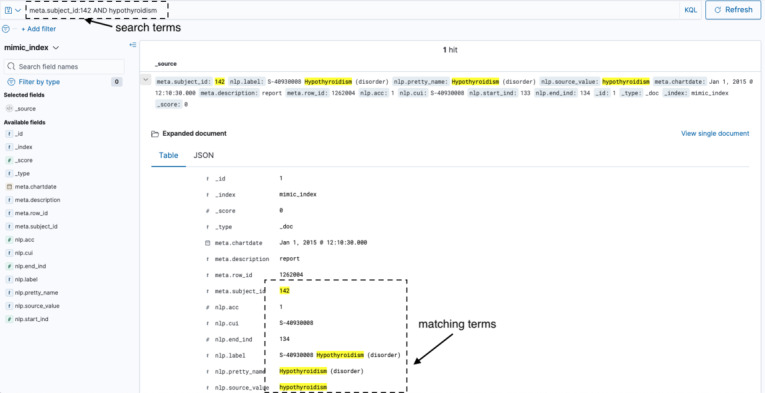
At UCLH, we have deployed the CogStack platform, an information retrieval platform with natural language processing capabilities. The platform addresses the problem of data ingestion and harmonization from multiple data sources using the Apache NiFi module for managing complex data flows. The platform also facilitates the extraction of structured data from free-text records through use of the MedCAT natural language processing library. Finally, data science tools are made available to support data scientists and the development of downstream applications dependent upon data ingested and analyzed by CogStack.
The platform has been deployed at the hospital, and in particular, it has facilitated a number of research and service evaluation projects. To date, we have processed over 30 million records, and the insights produced from CogStack have informed a number of clinical research use cases at the hospital.
The CogStack platform can be configured to handle the data ingestion and harmonization challenges faced by a hospital. More importantly, the platform enables the hospital to unlock important clinical information from the unstructured portion of the record using natural language processing technology.
随着越来越多的医疗保健机构转向使用电子健康记录(EHR)系统,这些机构将其数据的二次利用最大化以支持服务改进和临床研究变得至关重要。这些机构会发现,要拥有能够利用记录中的非结构化数据字段(临床笔记、信件等)的系统,并且更实际地让此类系统与所有医院数据系统(传统系统和当前系统)进行交互具有挑战性。
我们描述了电子健康记录接口信息提取和检索平台CogStack在伦敦大学学院医院(UCLH)的部署情况。
在UCLH,我们部署了CogStack平台,这是一个具有自然语言处理能力的信息检索平台。该平台使用Apache NiFi模块来管理复杂数据流,解决了从多个数据源摄取和协调数据的问题。该平台还通过使用MedCAT自然语言处理库,促进了从自由文本记录中提取结构化数据。最后,提供了数据科学工具来支持数据科学家以及依赖CogStack摄取和分析的数据开发下游应用程序。
该平台已在医院部署,特别是,它推动了许多研究和服务评估项目。迄今为止,我们已经处理了超过3000万条记录,并且CogStack产生的见解为医院的许多临床研究用例提供了依据。
CogStack平台可以配置为处理医院面临的数据摄取和协调挑战。更重要的是,该平台使医院能够使用自然语言处理技术从记录的非结构化部分解锁重要的临床信息。