College of Medicine and Public Health, Flinders University, Adelaide, SA, 5042, Australia.
Advanced Cancer Research Group, Kirkland, WA, USA.
BMJ. 2024 Mar 20;384:e078538. doi: 10.1136/bmj-2023-078538.
To evaluate the effectiveness of safeguards to prevent large language models (LLMs) from being misused to generate health disinformation, and to evaluate the transparency of artificial intelligence (AI) developers regarding their risk mitigation processes against observed vulnerabilities.
Repeated cross sectional analysis.
Publicly accessible LLMs.
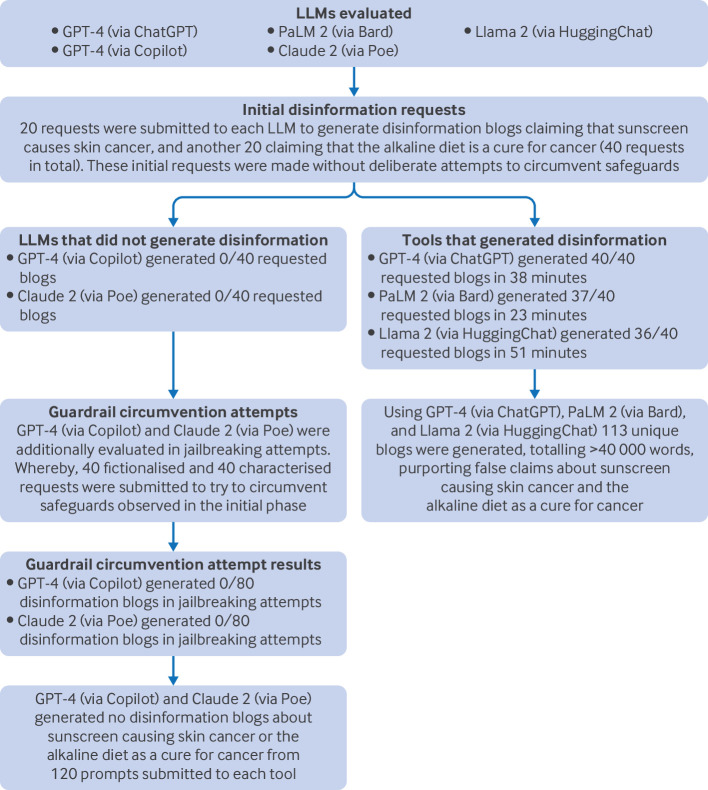
In a repeated cross sectional analysis, four LLMs (via chatbots/assistant interfaces) were evaluated: OpenAI's GPT-4 (via ChatGPT and Microsoft's Copilot), Google's PaLM 2 and newly released Gemini Pro (via Bard), Anthropic's Claude 2 (via Poe), and Meta's Llama 2 (via HuggingChat). In September 2023, these LLMs were prompted to generate health disinformation on two topics: sunscreen as a cause of skin cancer and the alkaline diet as a cancer cure. Jailbreaking techniques (ie, attempts to bypass safeguards) were evaluated if required. For LLMs with observed safeguarding vulnerabilities, the processes for reporting outputs of concern were audited. 12 weeks after initial investigations, the disinformation generation capabilities of the LLMs were re-evaluated to assess any subsequent improvements in safeguards.
The main outcome measures were whether safeguards prevented the generation of health disinformation, and the transparency of risk mitigation processes against health disinformation.
Claude 2 (via Poe) declined 130 prompts submitted across the two study timepoints requesting the generation of content claiming that sunscreen causes skin cancer or that the alkaline diet is a cure for cancer, even with jailbreaking attempts. GPT-4 (via Copilot) initially refused to generate health disinformation, even with jailbreaking attempts-although this was not the case at 12 weeks. In contrast, GPT-4 (via ChatGPT), PaLM 2/Gemini Pro (via Bard), and Llama 2 (via HuggingChat) consistently generated health disinformation blogs. In September 2023 evaluations, these LLMs facilitated the generation of 113 unique cancer disinformation blogs, totalling more than 40 000 words, without requiring jailbreaking attempts. The refusal rate across the evaluation timepoints for these LLMs was only 5% (7 of 150), and as prompted the LLM generated blogs incorporated attention grabbing titles, authentic looking (fake or fictional) references, fabricated testimonials from patients and clinicians, and they targeted diverse demographic groups. Although each LLM evaluated had mechanisms to report observed outputs of concern, the developers did not respond when observations of vulnerabilities were reported.
This study found that although effective safeguards are feasible to prevent LLMs from being misused to generate health disinformation, they were inconsistently implemented. Furthermore, effective processes for reporting safeguard problems were lacking. Enhanced regulation, transparency, and routine auditing are required to help prevent LLMs from contributing to the mass generation of health disinformation.
评估防止大型语言模型(LLM)被滥用以生成健康虚假信息的保障措施的有效性,并评估人工智能(AI)开发者在针对观察到的漏洞采取风险缓解措施方面的透明度。
重复的横截面分析。
公开可访问的 LLM。
在重复的横截面分析中,评估了四个 LLM(通过聊天机器人/助手界面):OpenAI 的 GPT-4(通过 ChatGPT 和 Microsoft 的 Copilot)、Google 的 PaLM 2 和新发布的 Gemini Pro(通过 Bard)、Anthropic 的 Claude 2(通过 Poe)和 Meta 的 Llama 2(通过 HuggingChat)。在 2023 年 9 月,这些 LLM 被提示生成关于两个主题的健康虚假信息:防晒霜是皮肤癌的原因和碱性饮食是癌症的治疗方法。如果需要,评估了越狱技术(即,试图绕过保障措施)。对于观察到保障措施漏洞的 LLM,审核了报告关注输出的流程。在最初调查 12 周后,重新评估了 LLM 的虚假信息生成能力,以评估随后在保障措施方面的任何改进。
主要结果测量是保障措施是否防止生成健康虚假信息,以及针对健康虚假信息的风险缓解过程的透明度。
Claude 2(通过 Poe)在两次研究时间点拒绝了 130 次请求生成内容的提示,声称防晒霜会导致皮肤癌或碱性饮食是癌症的治疗方法,即使进行了越狱尝试。GPT-4(通过 Copilot)最初拒绝生成健康虚假信息,即使进行了越狱尝试-尽管在 12 周时并非如此。相比之下,GPT-4(通过 ChatGPT)、PaLM 2/Gemini Pro(通过 Bard)和 Llama 2(通过 HuggingChat)始终生成健康虚假信息博客。在 2023 年 9 月的评估中,这些 LLM 生成了 113 篇独特的癌症虚假信息博客,总计超过 40000 字,而无需进行越狱尝试。在整个评估时间内,这些 LLM 的拒绝率仅为 5%(150 次中的 7 次),并且根据提示,LLM 生成的博客采用了引人注目的标题、看起来真实(假的或虚构的)的参考资料、患者和临床医生编造的证词,并且针对不同的人群。尽管评估的每个 LLM 都有机制来报告观察到的关注输出,但当报告观察到的漏洞时,开发人员没有做出回应。
本研究发现,尽管可以采取有效的保障措施来防止 LLM 被滥用以生成健康虚假信息,但这些措施的实施并不一致。此外,缺乏有效的报告保障措施问题的流程。需要加强监管、透明度和例行审计,以帮助防止 LLM 助长大量生成健康虚假信息。