Funk Paul F, Hoch Cosima C, Knoedler Samuel, Knoedler Leonard, Cotofana Sebastian, Sofo Giuseppe, Bashiri Dezfouli Ali, Wollenberg Barbara, Guntinas-Lichius Orlando, Alfertshofer Michael
Department of Otorhinolaryngology, Head and Neck Surgery, University Hospital Jena, Friedrich Schiller University Jena, Am Klinikum 1, 07747 Jena, Germany.
Department of Otolaryngology, Head and Neck Surgery, School of Medicine and Health, Technical University of Munich (TUM), Ismaningerstrasse 22, 81675 Munich, Germany.
Eur J Investig Health Psychol Educ. 2024 Mar 8;14(3):657-668. doi: 10.3390/ejihpe14030043.
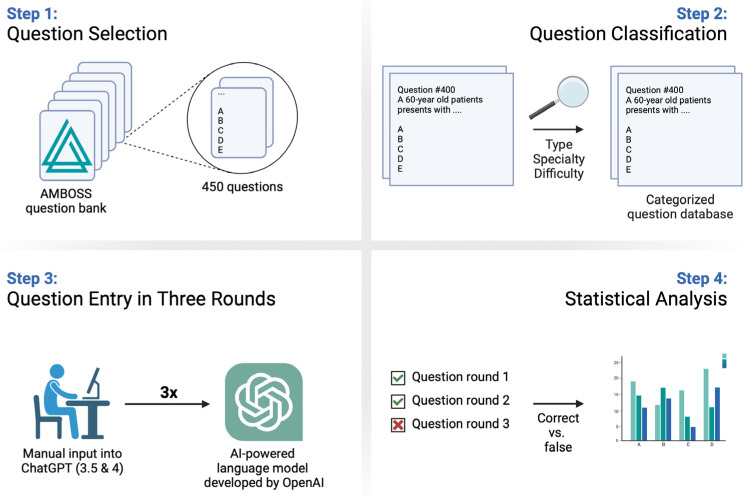
(1) Background: As the field of artificial intelligence (AI) evolves, tools like ChatGPT are increasingly integrated into various domains of medicine, including medical education and research. Given the critical nature of medicine, it is of paramount importance that AI tools offer a high degree of reliability in the information they provide. (2) Methods: A total of = 450 medical examination questions were manually entered into ChatGPT thrice, each for ChatGPT 3.5 and ChatGPT 4. The responses were collected, and their accuracy and consistency were statistically analyzed throughout the series of entries. (3) Results: ChatGPT 4 displayed a statistically significantly improved accuracy with 85.7% compared to that of 57.7% of ChatGPT 3.5 ( < 0.001). Furthermore, ChatGPT 4 was more consistent, correctly answering 77.8% across all rounds, a significant increase from the 44.9% observed from ChatGPT 3.5 ( < 0.001). (4) Conclusions: The findings underscore the increased accuracy and dependability of ChatGPT 4 in the context of medical education and potential clinical decision making. Nonetheless, the research emphasizes the indispensable nature of human-delivered healthcare and the vital role of continuous assessment in leveraging AI in medicine.
(1) 背景:随着人工智能(AI)领域的发展,ChatGPT等工具越来越多地融入医学的各个领域,包括医学教育和研究。鉴于医学的关键性质,人工智能工具所提供信息的高度可靠性至关重要。(2) 方法:总共450道医学考试题目被手动输入ChatGPT三次,每次分别针对ChatGPT 3.5和ChatGPT 4。收集回复,并对整个输入系列中回复的准确性和一致性进行统计分析。(3) 结果:ChatGPT 4的准确率在统计学上有显著提高,为85.7%,而ChatGPT 3.5为57.7%(P<0.001)。此外,ChatGPT 4更具一致性,在所有轮次中正确回答率为77.8%,较ChatGPT 3.5观察到的44.9%有显著提高(P<0.001)。(4) 结论:这些发现强调了ChatGPT 4在医学教育和潜在临床决策背景下准确性和可靠性的提高。尽管如此,该研究强调了人工提供医疗服务的不可或缺性以及持续评估在医学中利用人工智能方面的关键作用。