Yale College, New Haven, CT, USA.
Yale Child Study Center, Yale School of Medicine, New Haven, CT, USA.
Yale J Biol Med. 2024 Mar 29;97(1):17-27. doi: 10.59249/ZTOZ1966. eCollection 2024 Mar.
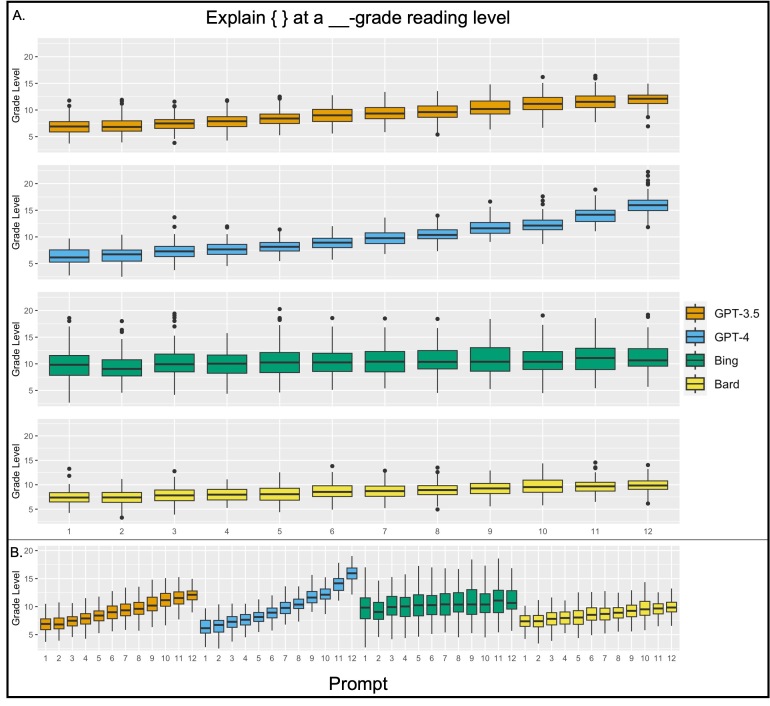
Enhanced health literacy in children has been empirically linked to better health outcomes over the long term; however, few interventions have been shown to improve health literacy. In this context, we investigate whether large language models (LLMs) can serve as a medium to improve health literacy in children. We tested pediatric conditions using 26 different prompts in ChatGPT-3.5, ChatGPT-4, Microsoft Bing, and Google Bard (now known as Google Gemini). The primary outcome measurement was the reading grade level (RGL) of output as assessed by Gunning Fog, Flesch-Kincaid Grade Level, Automated Readability Index, and Coleman-Liau indices. Word counts were also assessed. Across all models, output for basic prompts such as "Explain" and "What is (are)," were at, or exceeded, the tenth-grade RGL. When prompts were specified to explain conditions from the first- to twelfth-grade level, we found that LLMs had varying abilities to tailor responses based on grade level. ChatGPT-3.5 provided responses that ranged from the seventh-grade to college freshmen RGL while ChatGPT-4 outputted responses from the tenth-grade to the college senior RGL. Microsoft Bing provided responses from the ninth- to eleventh-grade RGL while Google Bard provided responses from the seventh- to tenth-grade RGL. LLMs face challenges in crafting outputs below a sixth-grade RGL. However, their capability to modify outputs above this threshold, provides a potential mechanism for adolescents to explore, understand, and engage with information regarding their health conditions, spanning from simple to complex terms. Future studies are needed to verify the accuracy and efficacy of these tools.
儿童健康素养的提高与长期健康结果的改善有关;然而,很少有干预措施被证明可以提高健康素养。在这种情况下,我们研究了大型语言模型(LLM)是否可以作为提高儿童健康素养的媒介。我们使用 26 种不同的提示,在 ChatGPT-3.5、ChatGPT-4、Microsoft Bing 和 Google Bard(现称为 Google Gemini)中测试了儿科疾病。主要的输出测量是通过 Gunning Fog、Flesch-Kincaid 年级水平、自动化可读性指数和 Coleman-Liau 指数评估的阅读年级水平(RGL)。还评估了字数。在所有模型中,对于“解释”和“什么是(是)”等基本提示的输出,都达到或超过了 10 年级 RGL。当提示被指定为解释 1 到 12 年级的疾病时,我们发现 LLM 有根据年级水平调整响应的不同能力。ChatGPT-3.5 的响应范围从 7 年级到大学新生 RGL,而 ChatGPT-4 的响应范围从 10 年级到大学高年级 RGL。Microsoft Bing 的响应范围从 9 年级到 11 年级 RGL,而 Google Bard 的响应范围从 7 年级到 10 年级 RGL。LLM 在制作低于 6 年级 RGL 的输出方面面临挑战。然而,它们能够修改高于这个阈值的输出,为青少年提供了一种潜在的机制,使他们能够探索、理解和参与与自己健康状况相关的信息,涵盖从简单到复杂的术语。需要进一步的研究来验证这些工具的准确性和有效性。