Pushpanathan Krithi, Zou Minjie, Srinivasan Sahana, Wong Wendy Meihua, Mangunkusumo Erlangga Ariadarma, Thomas George Naveen, Lai Yien, Sun Chen-Hsin, Lam Janice Sing Harn, Tan Marcus Chun Jin, Lin Hazel Anne Hui'En, Ma Weizhi, Koh Victor Teck Chang, Chen David Ziyou, Tham Yih-Chung
Department of Ophthalmology, Yong Loo Lin School of Medicine, National University of Singapore, Singapore.
Centre for Innovation and Precision Eye Health, Yong Loo Lin School of Medicine, National University of Singapore and National University Health System, Singapore.
Ophthalmol Sci. 2025 Feb 22;5(4):100745. doi: 10.1016/j.xops.2025.100745. eCollection 2025 Jul-Aug.
The newly launched OpenAI o1 is said to offer improved reasoning, potentially providing higher quality responses to eye care queries. However, its performance remains unassessed. We evaluated the performance of o1, ChatGPT-4o, and ChatGPT-4 in addressing ophthalmic-related queries, focusing on correctness, completeness, and readability.
Cross-sectional study.
Sixteen queries, previously identified as suboptimally responded to by ChatGPT-4 from prior studies, were used, covering 3 subtopics: myopia (6 questions), ocular symptoms (4 questions), and retinal conditions (6 questions).
For each subtopic, 3 attending-level ophthalmologists, masked to the model sources, evaluated the responses based on correctness, completeness, and readability (on a 5-point scale for each metric).
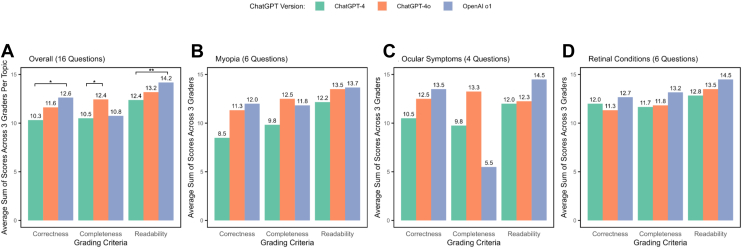
Mean summed scores of each model for correctness, completeness, and readability, rated on a 5-point scale (maximum score: 15).
O1 scored highest in correctness (12.6) and readability (14.2), outperforming ChatGPT-4, which scored 10.3 ( = 0.010) and 12.4 ( < 0.001), respectively. No significant difference was found between o1 and ChatGPT-4o. When stratified by subtopics, o1 consistently demonstrated superior correctness and readability. In completeness, ChatGPT-4o achieved the highest score of 12.4, followed by o1 (10.8), though the difference was not statistically significant. o1 showed notable limitations in completeness for ocular symptom queries, scoring 5.5 out of 15.
While o1 is marketed as offering improved reasoning capabilities, its performance in addressing eye care queries does not significantly differ from its predecessor, ChatGPT-4o. Nevertheless, it surpasses ChatGPT-4, particularly in correctness and readability.
Proprietary or commercial disclosure may be found in the Footnotes and Disclosures at the end of this article.
新推出的OpenAI o1据说具有改进的推理能力,可能会为眼科护理问题提供更高质量的回答。然而,其性能仍未得到评估。我们评估了o1、ChatGPT-4o和ChatGPT-4在处理眼科相关问题方面的性能,重点关注正确性、完整性和可读性。
横断面研究。
使用了先前研究中确定ChatGPT-4回答欠佳的16个问题,涵盖3个子主题:近视(6个问题)、眼部症状(4个问题)和视网膜疾病(6个问题)。
对于每个子主题,3名主治医师级别的眼科医生在不知道模型来源的情况下,根据正确性、完整性和可读性(每个指标采用5分制)对回答进行评估。
每个模型在正确性、完整性和可读性方面的平均总分,采用5分制评分(最高分:15分)。
o1在正确性(12.6)和可读性(14.2)方面得分最高,优于ChatGPT-4,后者在正确性和可读性方面的得分分别为10.3(P = 0.010)和12.4(P < 0.001)。o1和ChatGPT-4o之间未发现显著差异。按子主题分层时,o1始终表现出更高的正确性和可读性。在完整性方面,ChatGPT-4o得分最高,为12.4,其次是o1(10.8),但差异无统计学意义。o1在眼部症状问题的完整性方面存在明显局限性,得分为15分中的5.5分。
虽然o1被宣传为具有改进的推理能力,但其在处理眼科护理问题方面的性能与前身ChatGPT-4o相比没有显著差异。然而,它超过了ChatGPT-4,特别是在正确性和可读性方面。
专有或商业披露信息可在本文末尾的脚注和披露中找到。