Vollberg Marius C, Sander David
Department of Psychology, University of Amsterdam.
Swiss Center for Affective Sciences, University of Geneva.
Curr Dir Psychol Sci. 2024 Apr;33(2):93-99. doi: 10.1177/09637214231217678. Epub 2024 Jan 19.
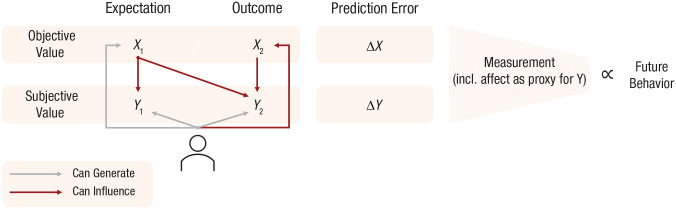
Scientists increasingly apply concepts from reinforcement learning to affect, but which concepts should apply? And what can their application reveal that we cannot know from directly observable states? An important reinforcement learning concept is the difference between reward expectations and outcomes. Such reward prediction errors have become foundational to research on adaptive behavior in humans, animals, and machines. Owing to historical focus on animal models and observable reward (e.g., food or money), however, relatively little attention has been paid to the fact that humans can additionally report correspondingly expected and experienced affect (e.g., feelings). Reflecting a broader "rise of affectivism," attention has started to shift, revealing explanatory power of expected and experienced feelings-including prediction errors-above and beyond observable reward. We propose that applying concepts from reinforcement learning to affect holds promise for elucidating subjective value. Simultaneously, we urge scientists to test-rather than inherit-concepts that may not apply directly.
科学家们越来越多地将强化学习的概念应用于情感,但应该应用哪些概念呢?它们的应用又能揭示哪些我们无法从直接观察到的状态中得知的信息呢?一个重要的强化学习概念是奖励期望与结果之间的差异。这种奖励预测误差已成为人类、动物和机器适应性行为研究的基础。然而,由于历史上对动物模型和可观察奖励(如食物或金钱)的关注,相对较少有人关注人类还能报告相应的预期和体验到的情感(如感觉)这一事实。反映出更广泛的“情感主义兴起”,注意力开始转移,揭示了预期和体验到的情感(包括预测误差)在可观察奖励之上的解释力。我们认为,将强化学习的概念应用于情感有望阐明主观价值。同时,我们敦促科学家对可能无法直接应用的概念进行测试而非继承。