Hegde Narayan, Vardhan Madhurima, Nathani Deepak, Rosenzweig Emily, Speed Cathy, Karthikesalingam Alan, Seneviratne Martin
Google Research, Bangalore, India.
Verily Life Sciences, San Francisco, United States of America.
PLOS Digit Health. 2024 Apr 2;3(4):e0000431. doi: 10.1371/journal.pdig.0000431. eCollection 2024 Apr.
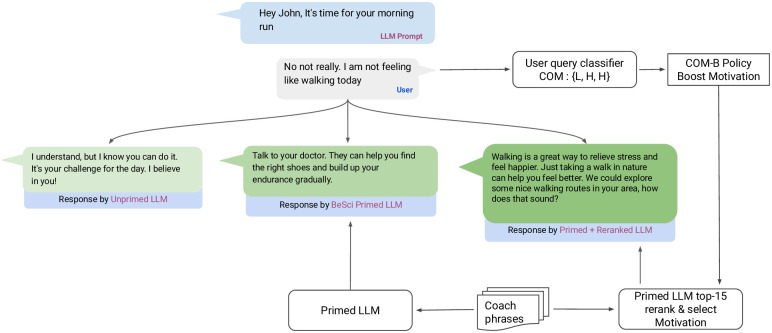
Large language models (LLMs) have shown promise for task-oriented dialogue across a range of domains. The use of LLMs in health and fitness coaching is under-explored. Behavior science frameworks such as COM-B, which conceptualizes behavior change in terms of capability (C), Opportunity (O) and Motivation (M), can be used to architect coaching interventions in a way that promotes sustained change. Here we aim to incorporate behavior science principles into an LLM using two knowledge infusion techniques: coach message priming (where exemplar coach responses are provided as context to the LLM), and dialogue re-ranking (where the COM-B category of the LLM output is matched to the inferred user need). Simulated conversations were conducted between the primed or unprimed LLM and a member of the research team, and then evaluated by 8 human raters. Ratings for the primed conversations were significantly higher in terms of empathy and actionability. The same raters also compared a single response generated by the unprimed, primed and re-ranked models, finding a significant uplift in actionability and empathy from the re-ranking technique. This is a proof of concept of how behavior science frameworks can be infused into automated conversational agents for a more principled coaching experience.
大语言模型(LLMs)已在一系列领域的面向任务的对话中展现出前景。大语言模型在健康与健身指导方面的应用尚未得到充分探索。行为科学框架,如COM - B,它从能力(C)、机会(O)和动机(M)的角度对行为改变进行概念化,可以用于构建指导干预措施,以促进持续的改变。在此,我们旨在通过两种知识注入技术将行为科学原理融入大语言模型:教练信息引导(将示例教练回复作为大语言模型的上下文提供)和对话重新排序(将大语言模型输出的COM - B类别与推断出的用户需求相匹配)。在经过引导或未引导的大语言模型与一名研究团队成员之间进行了模拟对话,然后由8名人类评分者进行评估。在同理心和可操作性方面,对经过引导的对话的评分显著更高。同样的评分者还比较了未引导、引导和重新排序模型生成的单个回复,发现重新排序技术在可操作性和同理心方面有显著提升。这证明了行为科学框架如何能够融入自动化对话代理,以获得更有原则的指导体验。