Dynel Marta
University of Łódź, Poland.
Vilnius Gediminas Technical University, Lithuania.
Discourse Soc. 2021 Mar;32(2):175-195. doi: 10.1177/0957926520970385.
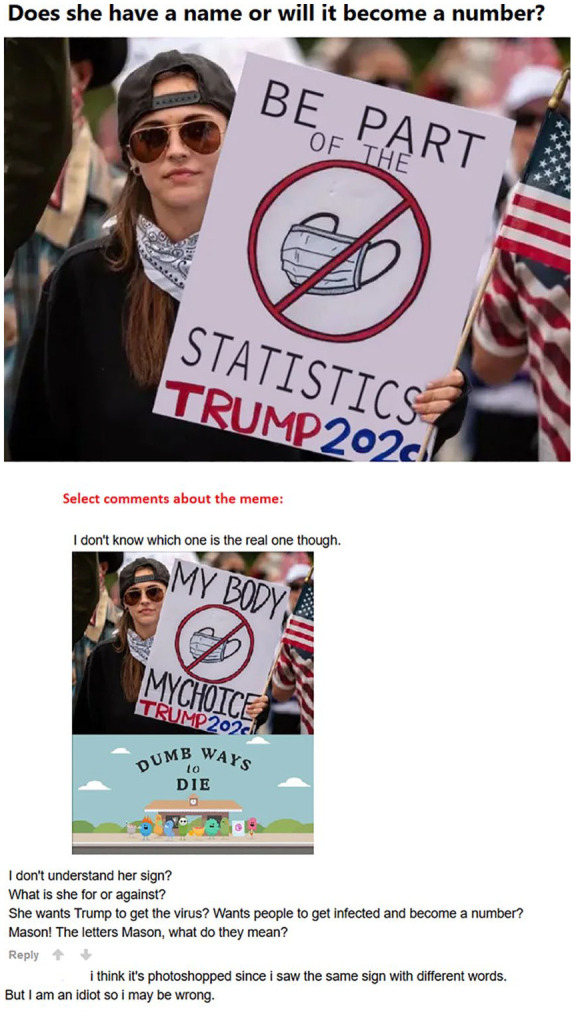
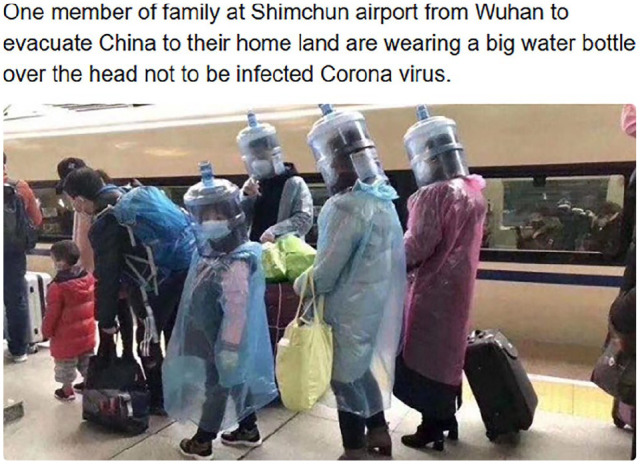
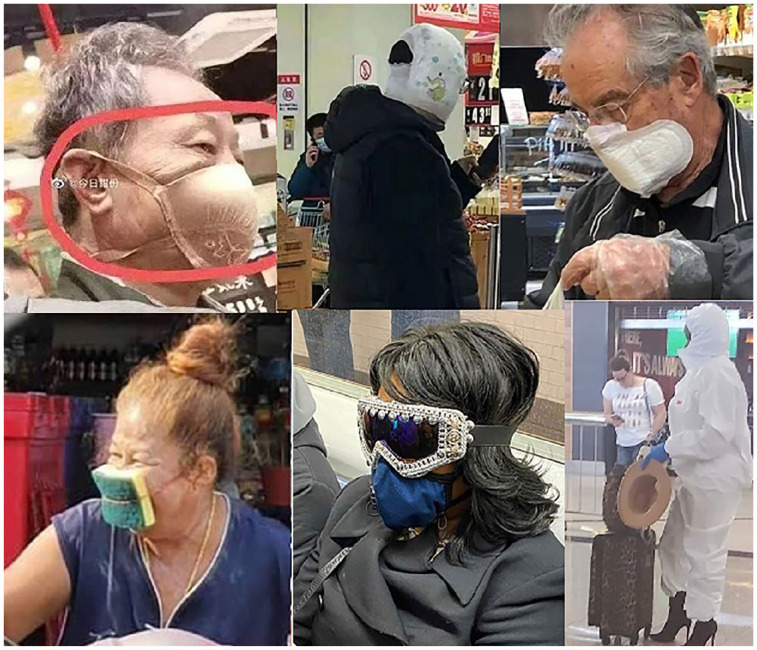
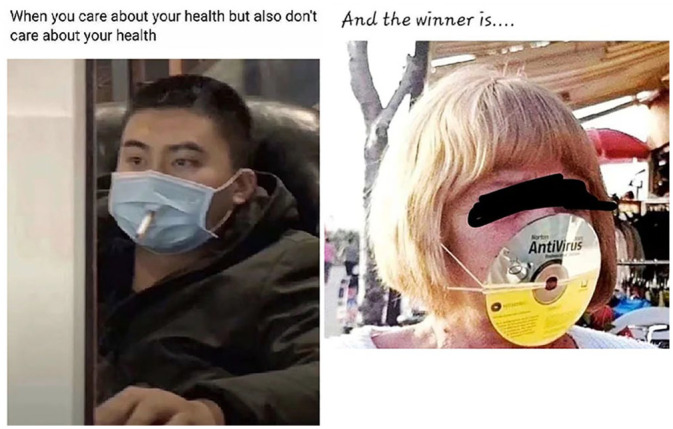
Advancing the concept of multimodal voicing as a tool for describing user-generated online humour, this paper reports a study on humorous COVID-19 mask memes. The corpus is drawn from four popular social media platforms and examined through a multimodal discourse analytic lens. The dominant memetic trends are elucidated and shown to rely programmatically on nested (multimodal) voices, whether compatible or divergent, as is the case with the dissociative echoing of individuals wearing peculiar masks or the dissociative parodic echoing of their collective voice. The theoretical thrust of this analysis is that, as some memes are (re)posted across social media (sometimes going viral), the previous voice(s) - of the meme subject/author/poster - can be re-purposed (e.g. ridiculed) or unwittingly distorted. Overall, this investigation offers new theoretical and methodological implications for the study of memes: it indicates the usefulness of the notions of multimodal voicing, intertextuality and echoing as research apparatus; and it brings to light the epistemological ambiguity in lay and academic understandings of memes, the voices behind which cannot always be categorically known.
本文推进了多模态发声这一概念,将其作为描述用户生成的网络幽默的一种工具,报告了一项关于新冠疫情口罩表情包的研究。语料库取自四个热门社交媒体平台,并通过多模态话语分析视角进行审视。主导的表情包趋势得以阐明,并显示出在程序上依赖嵌套(多模态)声音,无论这些声音是兼容还是相悖,比如戴着奇特口罩的个人的解离式呼应,或者对其集体声音的解离式模仿呼应。该分析的理论要点在于,随着一些表情包在社交媒体上(重新)发布(有时会疯传),表情包主题/作者/发布者之前的声音可能会被重新利用(如被嘲笑)或在不经意间被扭曲。总体而言,这项调查为表情包研究提供了新的理论和方法启示:它表明了多模态发声、互文性和呼应等概念作为研究工具的有用性;并且揭示了大众和学术对表情包理解中的认识论模糊性,其背后的声音并不总是能够明确知晓。