School of Chemistry and Biochemistry, Georgia Institute of Technology, Atlanta, Georgia 30332, United States.
Petit Institute of Bioengineering and Bioscience, Georgia Institute of Technology, Atlanta, Georgia 30332, United States.
J Am Soc Mass Spectrom. 2024 Jun 5;35(6):1089-1100. doi: 10.1021/jasms.3c00403. Epub 2024 May 1.
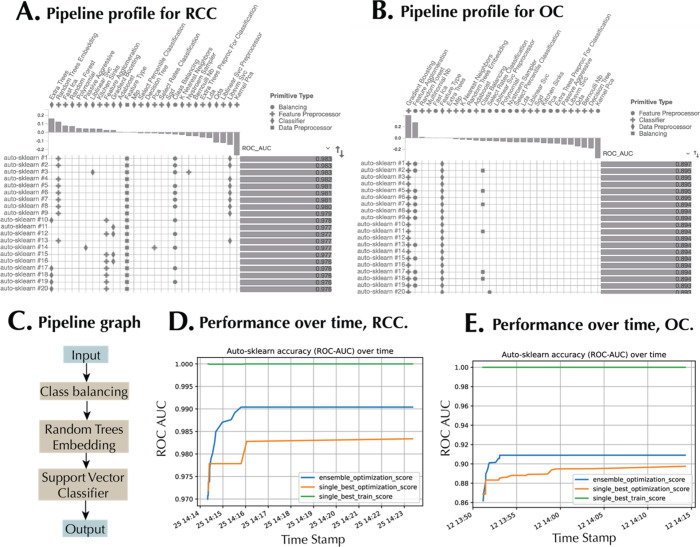
Metabolomics generates complex data necessitating advanced computational methods for generating biological insight. While machine learning (ML) is promising, the challenges of selecting the best algorithms and tuning hyperparameters, particularly for nonexperts, remain. Automated machine learning (AutoML) can streamline this process; however, the issue of interpretability could persist. This research introduces a unified pipeline that combines AutoML with explainable AI (XAI) techniques to optimize metabolomics analysis. We tested our approach on two data sets: renal cell carcinoma (RCC) urine metabolomics and ovarian cancer (OC) serum metabolomics. AutoML, using Auto-sklearn, surpassed standalone ML algorithms like SVM and k-Nearest Neighbors in differentiating between RCC and healthy controls, as well as OC patients and those with other gynecological cancers. The effectiveness of Auto-sklearn is highlighted by its AUC scores of 0.97 for RCC and 0.85 for OC, obtained from the unseen test sets. Importantly, on most of the metrics considered, Auto-sklearn demonstrated a better classification performance, leveraging a mix of algorithms and ensemble techniques. Shapley Additive Explanations (SHAP) provided a global ranking of feature importance, identifying dibutylamine and ganglioside GM(d34:1) as the top discriminative metabolites for RCC and OC, respectively. Waterfall plots offered local explanations by illustrating the influence of each metabolite on individual predictions. Dependence plots spotlighted metabolite interactions, such as the connection between hippuric acid and one of its derivatives in RCC, and between GM3(d34:1) and GM3(18:1_16:0) in OC, hinting at potential mechanistic relationships. Through decision plots, a detailed error analysis was conducted, contrasting feature importance for correctly versus incorrectly classified samples. In essence, our pipeline emphasizes the importance of harmonizing AutoML and XAI, facilitating both simplified ML application and improved interpretability in metabolomics data science.
代谢组学生成的复杂数据需要先进的计算方法来产生生物学见解。虽然机器学习(ML)很有前途,但对于非专业人士来说,选择最佳算法和调整超参数的挑战仍然存在。自动化机器学习(AutoML)可以简化这个过程;然而,可解释性的问题可能仍然存在。本研究介绍了一个结合了 AutoML 和可解释 AI(XAI)技术的统一管道,以优化代谢组学分析。我们在两个数据集上测试了我们的方法:肾细胞癌(RCC)尿液代谢组学和卵巢癌(OC)血清代谢组学。使用 Auto-sklearn 的 AutoML 在区分 RCC 与健康对照以及 OC 患者与其他妇科癌症患者方面,超过了 SVM 和 k-Nearest Neighbors 等独立的 ML 算法。Auto-sklearn 的有效性通过其在看不见的测试集上为 RCC 和 OC 获得的 0.97 和 0.85 的 AUC 分数得到了突出。重要的是,在大多数考虑的指标上,Auto-sklearn 利用算法和集成技术的组合,展示了更好的分类性能。Shapley Additive Explanations (SHAP) 提供了特征重要性的全局排名,确定二丁胺和神经节苷脂 GM(d34:1) 分别为 RCC 和 OC 的顶级区分代谢物。瀑布图通过说明每个代谢物对单个预测的影响来提供局部解释。依赖图突出了代谢物相互作用,例如在 RCC 中, hippuric acid 与其衍生物之一之间的连接,以及在 OC 中 GM3(d34:1) 和 GM3(18:1_16:0) 之间的连接,暗示了潜在的机制关系。通过决策图,对特征重要性进行了详细的错误分析,比较了正确和错误分类样本的特征重要性。从本质上讲,我们的管道强调了协调 AutoML 和 XAI 的重要性,既简化了 ML 应用,又提高了代谢组学数据科学的可解释性。