Galal Aya, Talal Marwa, Moustafa Ahmed
Systems Genomics Laboratory, American University in Cairo, New Cairo, Egypt.
Institute of Global Health and Human Ecology, American University in Cairo, New Cairo, Egypt.
Front Genet. 2022 Nov 24;13:1017340. doi: 10.3389/fgene.2022.1017340. eCollection 2022.
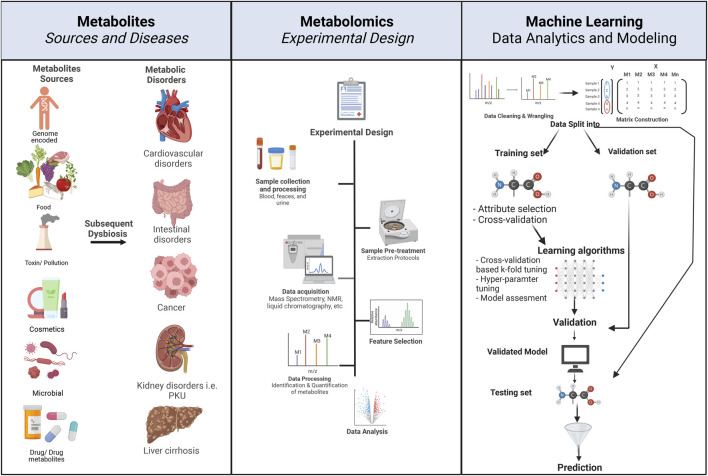
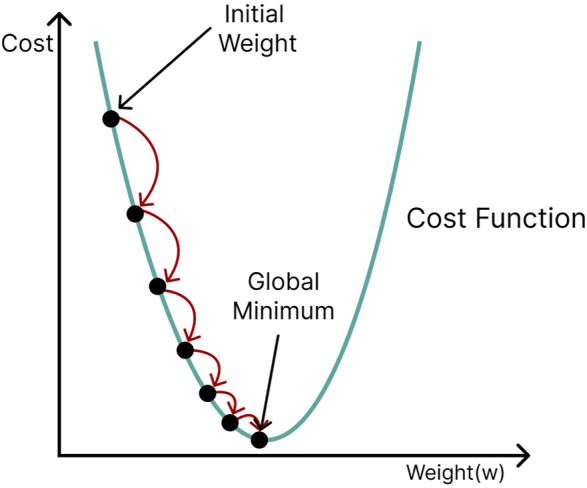
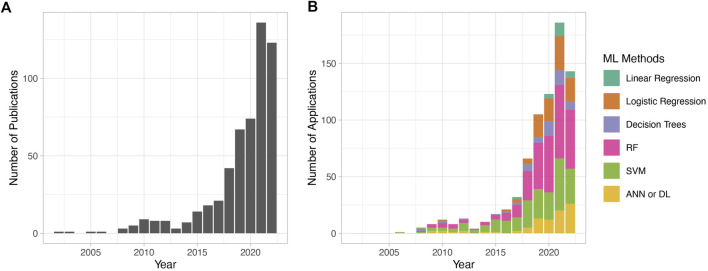
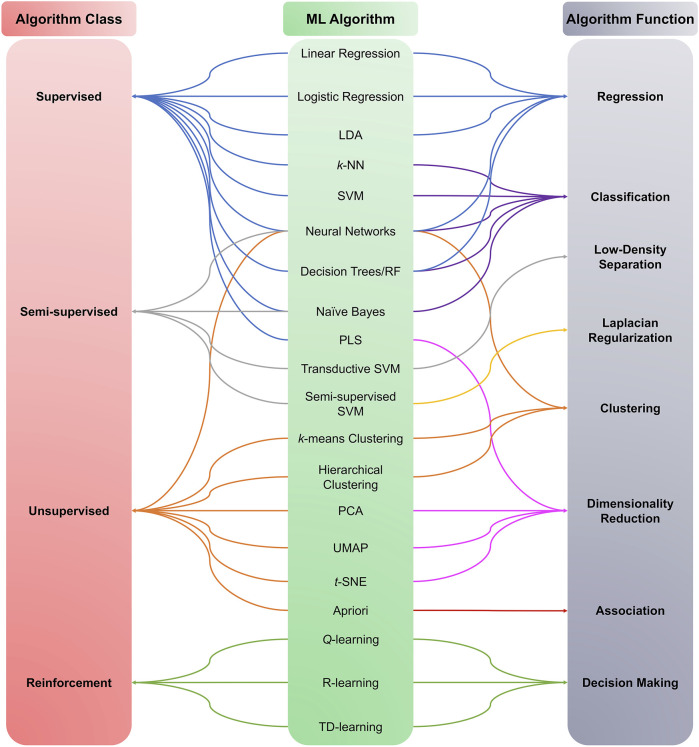
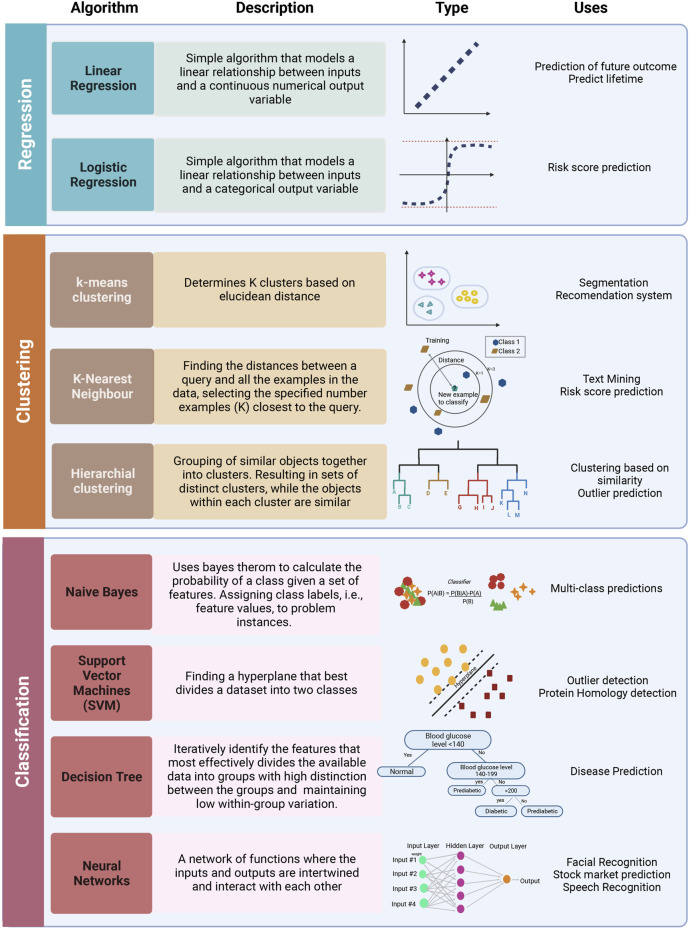
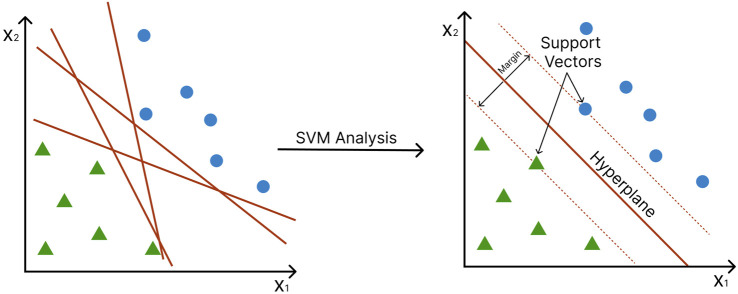
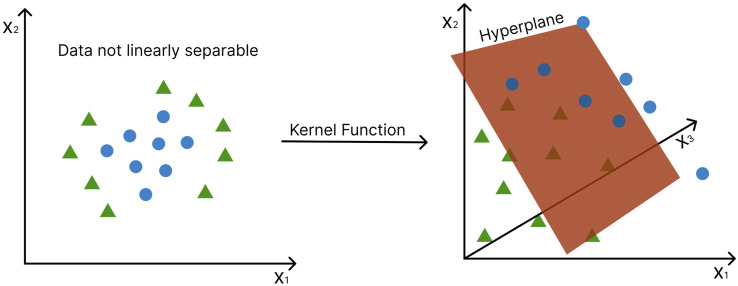
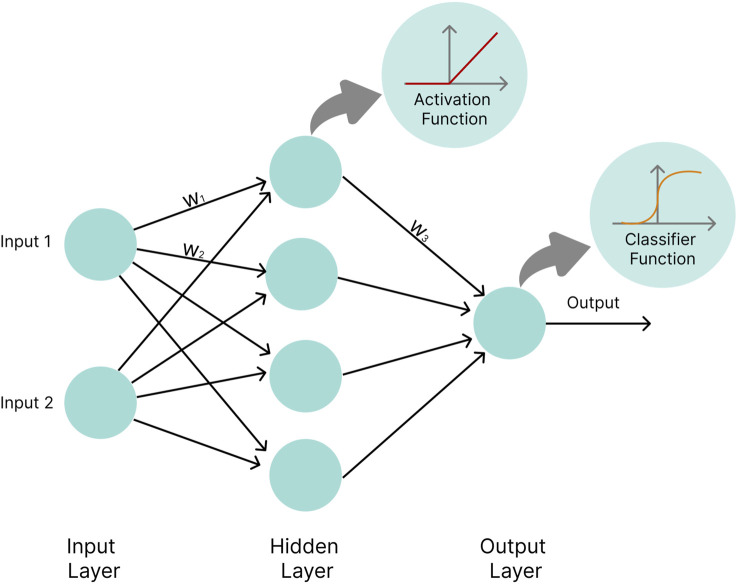
Metabolomics research has recently gained popularity because it enables the study of biological traits at the biochemical level and, as a result, can directly reveal what occurs in a cell or a tissue based on health or disease status, complementing other omics such as genomics and transcriptomics. Like other high-throughput biological experiments, metabolomics produces vast volumes of complex data. The application of machine learning (ML) to analyze data, recognize patterns, and build models is expanding across multiple fields. In the same way, ML methods are utilized for the classification, regression, or clustering of highly complex metabolomic data. This review discusses how disease modeling and diagnosis can be enhanced via deep and comprehensive metabolomic profiling using ML. We discuss the general layout of a metabolic workflow and the fundamental ML techniques used to analyze metabolomic data, including support vector machines (SVM), decision trees, random forests (RF), neural networks (NN), and deep learning (DL). Finally, we present the advantages and disadvantages of various ML methods and provide suggestions for different metabolic data analysis scenarios.
代谢组学研究近来颇受关注,因为它能在生化水平上研究生物学特性,从而基于健康或疾病状态直接揭示细胞或组织中发生的情况,对基因组学和转录组学等其他组学起到补充作用。与其他高通量生物学实验一样,代谢组学产生大量复杂数据。机器学习(ML)在多个领域的应用不断扩展,用于分析数据、识别模式和构建模型。同样,ML方法也用于对高度复杂的代谢组学数据进行分类、回归或聚类。本综述讨论了如何通过使用ML进行深入全面的代谢组学分析来加强疾病建模和诊断。我们讨论了代谢工作流程的总体布局以及用于分析代谢组学数据的基本ML技术,包括支持向量机(SVM)、决策树、随机森林(RF)、神经网络(NN)和深度学习(DL)。最后,我们介绍了各种ML方法的优缺点,并针对不同的代谢数据分析场景提供建议。