de Boer Annemarijn R, de Groot Mark C H, Groenhof T Katrien J, van Doorn Sander, Vaartjes Ilonca, Bots Michiel L, Haitjema Saskia
Julius Center for Health Sciences and Primary Care, University Medical Center Utrecht, Utrecht University, Heidelberglaan 100, Utrecht 3584 CX, The Netherlands.
Dutch Heart Foundation, The Hague, The Netherlands.
Eur Heart J Digit Health. 2022 May 20;3(3):437-444. doi: 10.1093/ehjdh/ztac031. eCollection 2022 Sep.
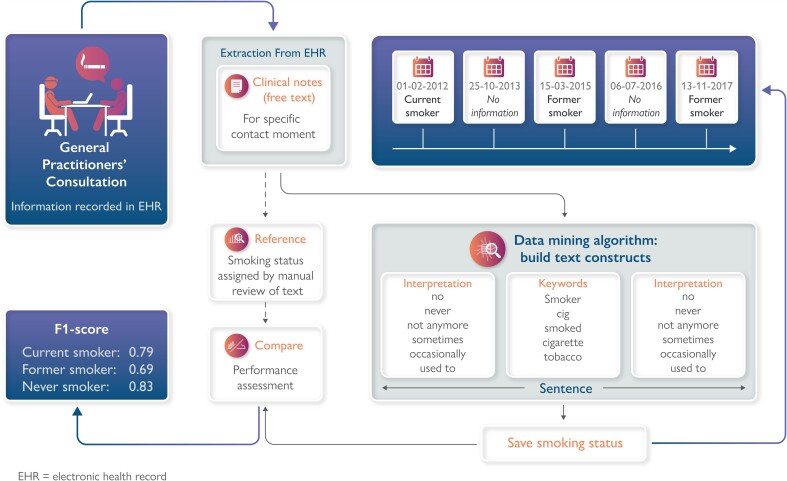
Optimize and assess the performance of an existing data mining algorithm for smoking status from hospital electronic health records (EHRs) in general practice EHRs.
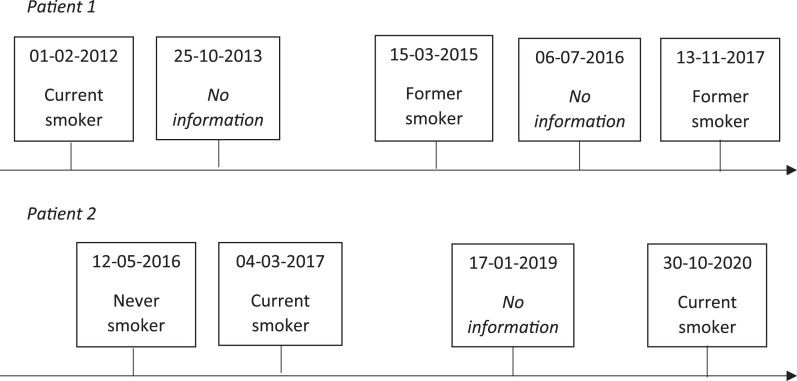
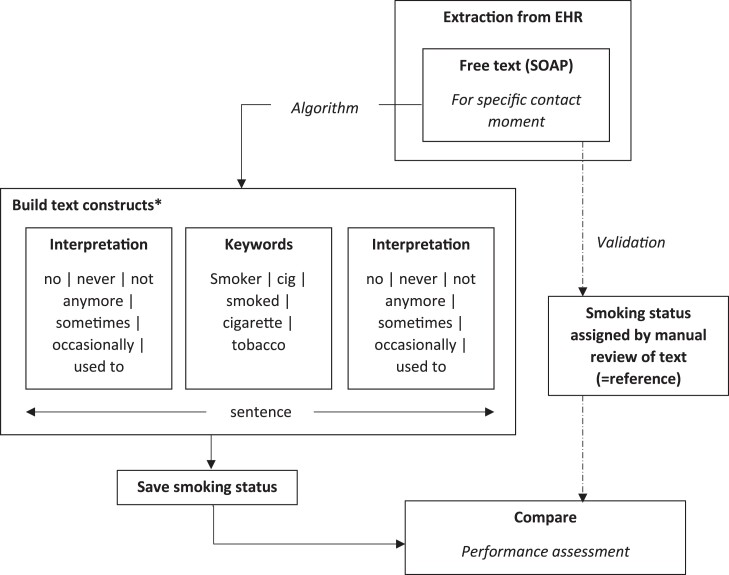
We optimized an existing algorithm in a training set containing all clinical notes from 498 individuals (75 712 contact moments) from the Julius General Practitioners' Network (JGPN). Each moment was classified as either 'current smoker', 'former smoker', 'never smoker', or 'no information'. As a reference, we manually reviewed EHRs. Algorithm performance was assessed in an independent test set ( = 494, 78 129 moments) using precision, recall, and F1-score. Test set algorithm performance for 'current smoker' was precision 79.7%, recall 78.3%, and F1-score 0.79. For former smoker, it was precision 73.8%, recall 64.0%, and F1-score 0.69. For never smoker, it was precision 92.0%, recall 74.9%, and F1-score 0.83. On a patient level, performance for ever smoker (current and former smoker combined) was precision 87.9%, recall 94.7%, and F1-score 0.91. For never smoker, it was 98.0, 82.0, and 0.89%, respectively. We found a more narrative writing style in general practice than in hospital EHRs.
Data mining can successfully retrieve smoking status information from general practice clinical notes with a good performance for classifying ever and never smokers. Differences between general practice and hospital EHRs call for optimization of data mining algorithms when applied beyond a primary development setting.
优化并评估一种现有的数据挖掘算法,该算法用于从全科医疗电子健康记录(EHR)中确定吸烟状态。
我们在一个训练集中优化了现有的算法,该训练集包含来自朱利叶斯全科医生网络(JGPN)的498名个体(75712个接触时刻)的所有临床记录。每个时刻被分类为“当前吸烟者”“既往吸烟者”“从不吸烟者”或“无信息”。作为参考,我们人工查阅了电子健康记录。使用精确率、召回率和F1分数在一个独立的测试集(n = 494,78129个时刻)中评估算法性能。测试集算法对“当前吸烟者”的性能为精确率79.7%,召回率78.3%,F1分数0.79。对于既往吸烟者,精确率为73.8%,召回率为64.0%,F1分数为0.69。对于从不吸烟者,精确率为92.0%,召回率为74.9%,F1分数为0.83。在患者层面,曾经吸烟者(当前吸烟者和既往吸烟者合并)的性能为精确率87.9%,召回率94.7%,F1分数0.91。对于从不吸烟者,分别为98.0%、82.0%和0.89%。我们发现全科医疗中的临床记录比医院电子健康记录的叙事风格更强。
数据挖掘可以成功地从全科医疗临床记录中检索吸烟状态信息,在对曾经吸烟者和从不吸烟者进行分类方面具有良好的性能。全科医疗和医院电子健康记录之间的差异要求在超出主要开发环境应用数据挖掘算法时进行优化。