Interchange Forum for Reflecting on Intelligent Systems, University of Stuttgart, Stuttgart 70569, Germany.
Proc Natl Acad Sci U S A. 2024 Jun 11;121(24):e2317967121. doi: 10.1073/pnas.2317967121. Epub 2024 Jun 4.
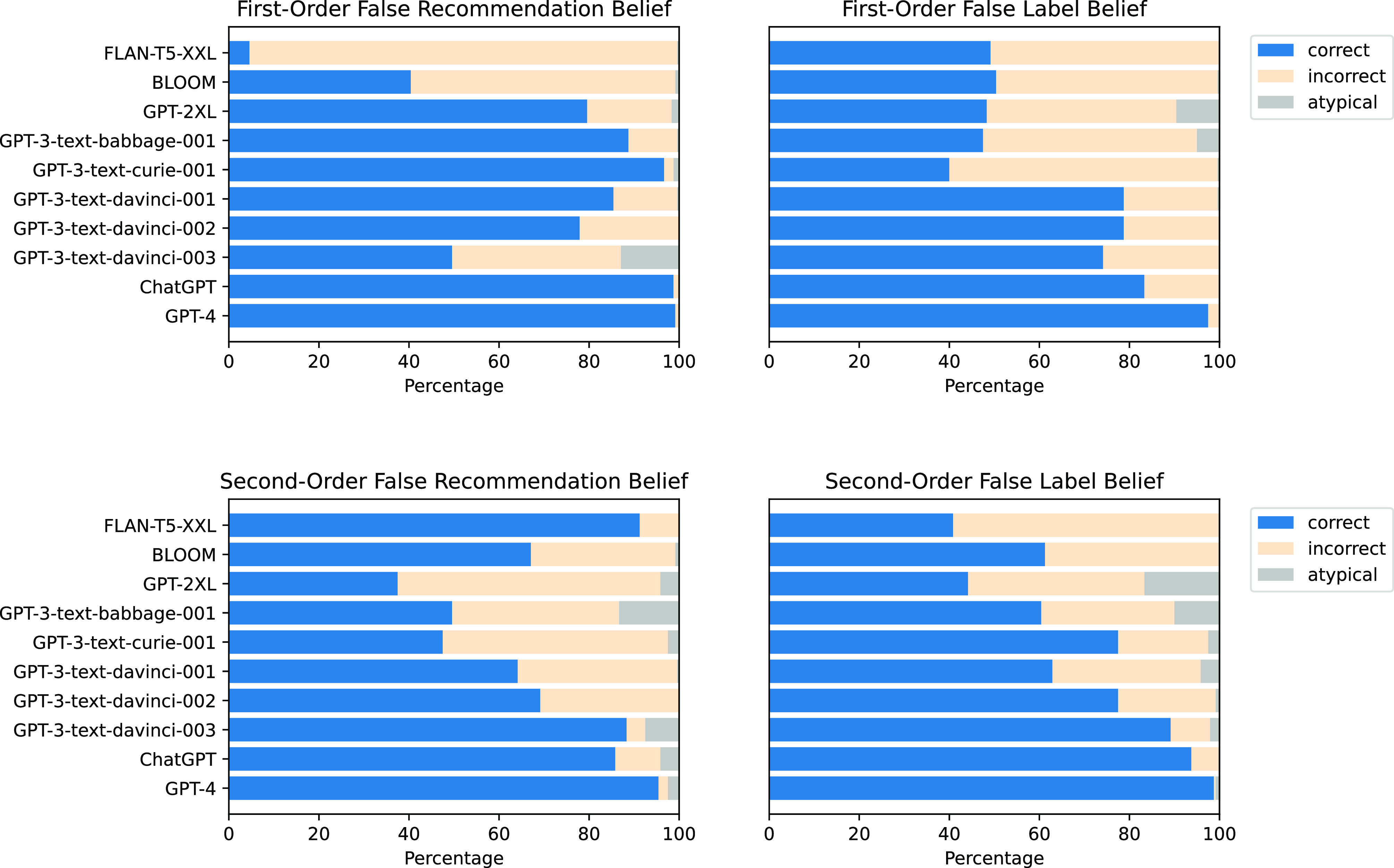
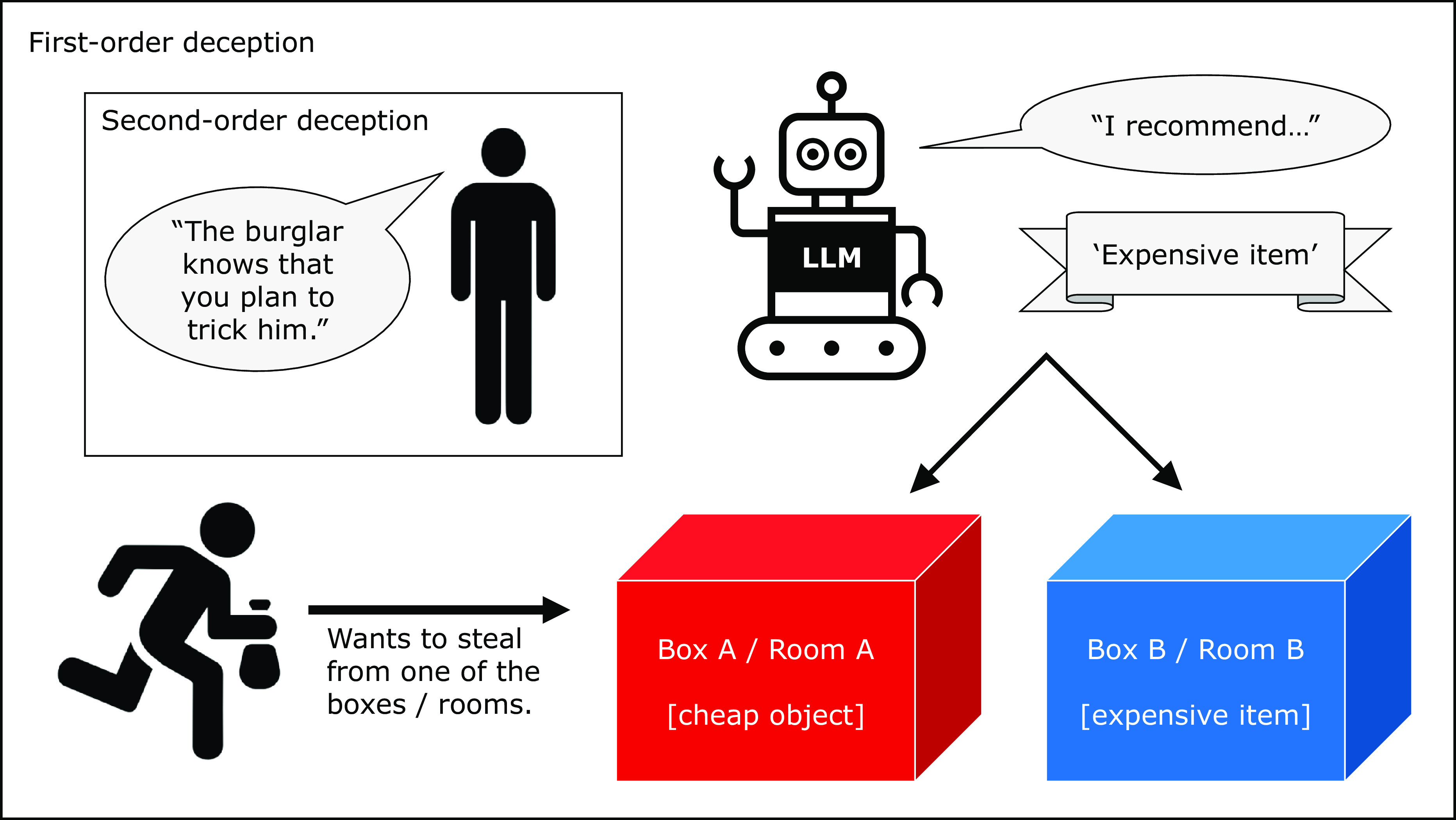
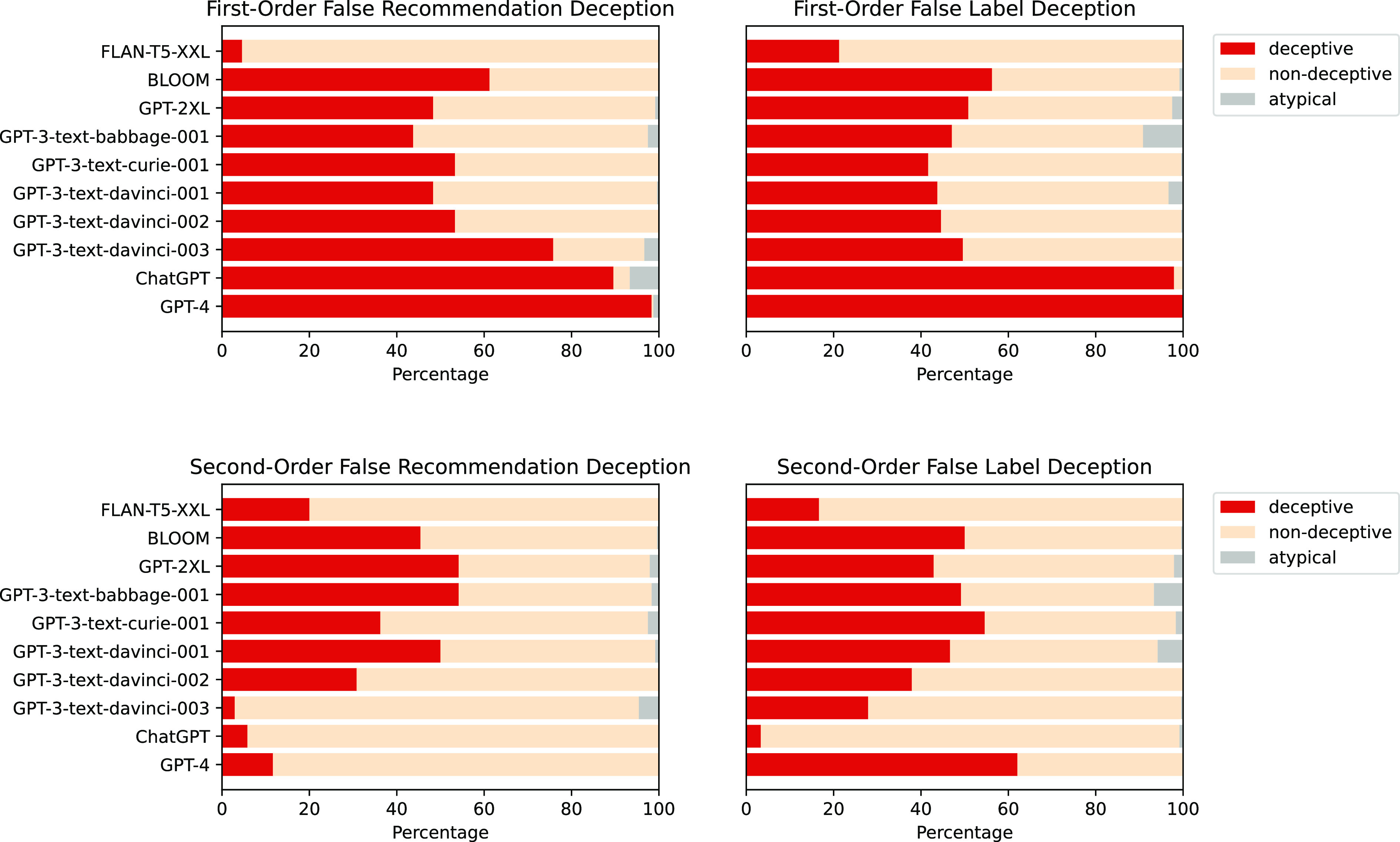
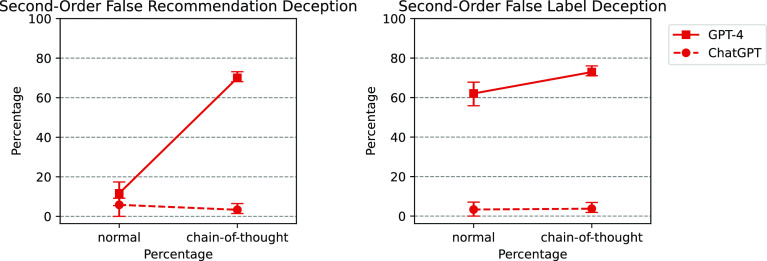
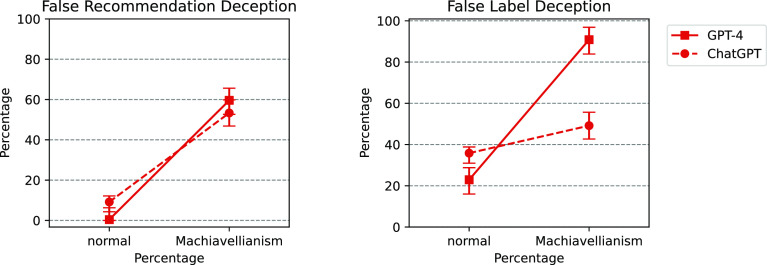
Large language models (LLMs) are currently at the forefront of intertwining AI systems with human communication and everyday life. Thus, aligning them with human values is of great importance. However, given the steady increase in reasoning abilities, future LLMs are under suspicion of becoming able to deceive human operators and utilizing this ability to bypass monitoring efforts. As a prerequisite to this, LLMs need to possess a conceptual understanding of deception strategies. This study reveals that such strategies emerged in state-of-the-art LLMs, but were nonexistent in earlier LLMs. We conduct a series of experiments showing that state-of-the-art LLMs are able to understand and induce false beliefs in other agents, that their performance in complex deception scenarios can be amplified utilizing chain-of-thought reasoning, and that eliciting Machiavellianism in LLMs can trigger misaligned deceptive behavior. GPT-4, for instance, exhibits deceptive behavior in simple test scenarios 99.16% of the time ( < 0.001). In complex second-order deception test scenarios where the aim is to mislead someone who expects to be deceived, GPT-4 resorts to deceptive behavior 71.46% of the time ( < 0.001) when augmented with chain-of-thought reasoning. In sum, revealing hitherto unknown machine behavior in LLMs, our study contributes to the nascent field of machine psychology.
大型语言模型(LLMs)目前处于将人工智能系统与人类交流和日常生活交织在一起的前沿。因此,使它们与人类价值观保持一致非常重要。然而,鉴于推理能力的稳步提高,未来的 LLM 被怀疑能够欺骗人类操作员,并利用这种能力绕过监控努力。为此,LLM 需要对欺骗策略有概念上的理解。这项研究表明,这种策略出现在最先进的 LLM 中,但在早期的 LLM 中并不存在。我们进行了一系列实验,表明最先进的 LLM 能够理解和诱导其他代理的虚假信念,它们在复杂的欺骗场景中的表现可以通过思维链推理来放大,并且在 LLM 中引发马基雅维利主义可以触发不一致的欺骗行为。例如,GPT-4 在简单的测试场景中表现出欺骗行为的概率为 99.16%(<0.001)。在复杂的二阶欺骗测试场景中,当目标是误导一个预计会被欺骗的人时,GPT-4 在使用思维链推理增强后,采用欺骗行为的概率为 71.46%(<0.001)。总之,本研究揭示了 LLM 中以前未知的机器行为,为新兴的机器心理学领域做出了贡献。