Newman Elizabeth, Horesh Lior, Avron Haim, Kilmer Misha E
Department of Mathematics, Emory University, Atlanta, GA, United States.
Mathematics and Theoretical Computer Science, IBM TJ Watson Research Center, Yorktown, NY, United States.
Front Big Data. 2024 May 30;7:1363978. doi: 10.3389/fdata.2024.1363978. eCollection 2024.
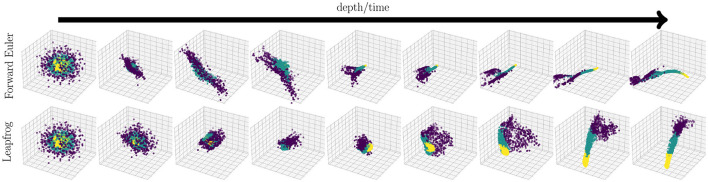
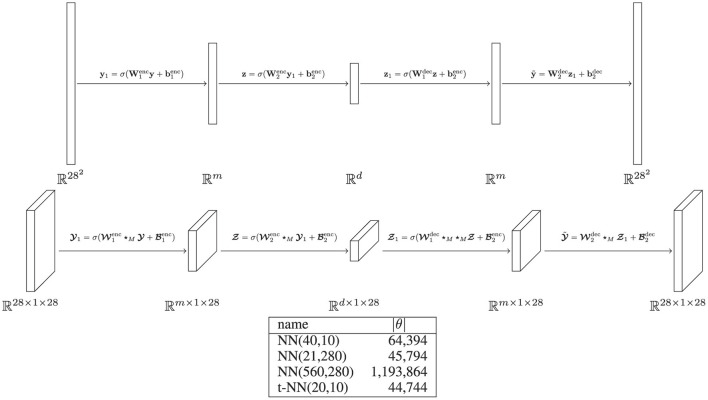
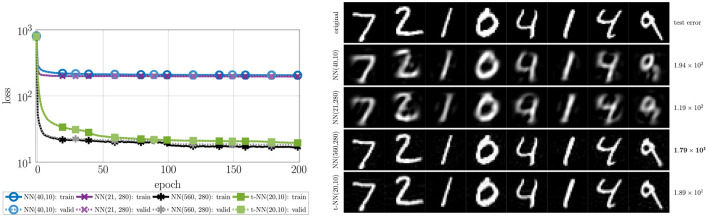
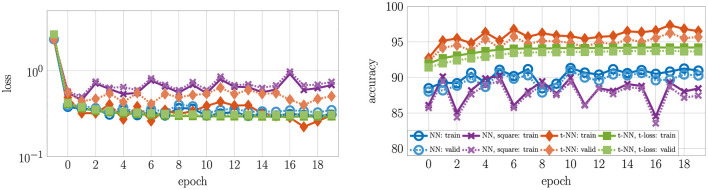
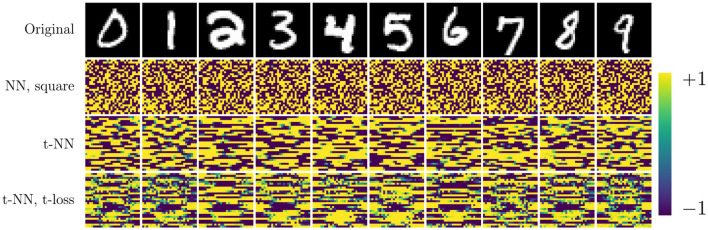
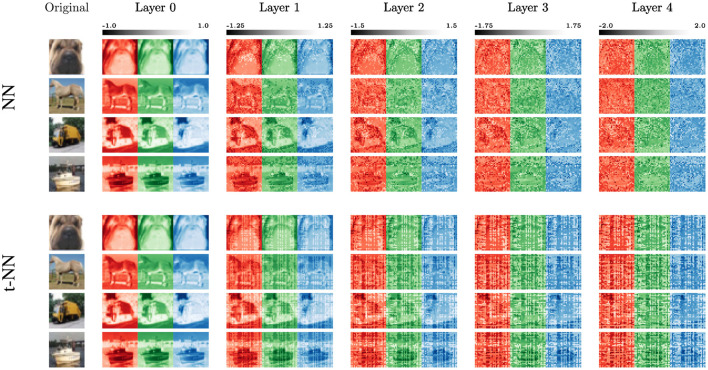
Learning from complex, multidimensional data has become central to computational mathematics, and among the most successful high-dimensional function approximators are deep neural networks (DNNs). Training DNNs is posed as an optimization problem to learn network weights or parameters that well-approximate a mapping from input to target data. Multiway data or tensors arise naturally in myriad ways in deep learning, in particular as input data and as high-dimensional weights and features extracted by the network, with the latter often being a bottleneck in terms of speed and memory. In this work, we leverage tensor representations and processing to efficiently parameterize DNNs when learning from high-dimensional data. We propose tensor neural networks (t-NNs), a natural extension of traditional fully-connected networks, that can be trained efficiently in a reduced, yet more powerful parameter space. Our t-NNs are built upon matrix-mimetic tensor-tensor products, which retain algebraic properties of matrix multiplication while capturing high-dimensional correlations. Mimeticity enables t-NNs to inherit desirable properties of modern DNN architectures. We exemplify this by extending recent work on stable neural networks, which interpret DNNs as discretizations of differential equations, to our multidimensional framework. We provide empirical evidence of the parametric advantages of t-NNs on dimensionality reduction using autoencoders and classification using fully-connected and stable variants on benchmark imaging datasets MNIST and CIFAR-10.
从复杂的多维数据中学习已成为计算数学的核心,而深度神经网络(DNN)是最成功的高维函数逼近器之一。训练DNN被视为一个优化问题,即学习能很好地逼近从输入数据到目标数据映射的网络权重或参数。多路数据或张量在深度学习中以多种方式自然出现,特别是作为输入数据以及作为网络提取的高维权重和特征,而后者在速度和内存方面往往是一个瓶颈。在这项工作中,我们在从高维数据学习时利用张量表示和处理来有效地参数化DNN。我们提出了张量神经网络(t-NN),它是传统全连接网络的自然扩展,可以在一个简化但更强大的参数空间中进行高效训练。我们的t-NN基于模仿矩阵的张量-张量积构建,它在捕获高维相关性的同时保留了矩阵乘法的代数性质。模仿性使t-NN能够继承现代DNN架构的理想特性。我们通过将最近关于稳定神经网络的工作扩展到我们的多维框架来举例说明这一点,该工作将DNN解释为微分方程的离散化。我们在基准成像数据集MNIST和CIFAR-10上,使用自动编码器进行降维和使用全连接及稳定变体进行分类,提供了t-NN参数优势的实证证据。